 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Machine Learning Research
Sep 09, 2024



This paper explores a top-down approach to automating incremental advances in machine learning research through component-level innovation, facilitated by Large Language Models (LLMs). Our framework systematically generates novel components, validates their feasibility, and evaluates their performance against existing baselines. A key distinction of this approach lies in how these novel components are generated. Unlike traditional AutoML and NAS methods, which often rely on a bottom-up combinatorial search over predefined, hardcoded base components, our method leverages the cross-domain knowledge embedded in LLMs to propose new components that may not be confined to any hard-coded predefined set. By incorporating a reward model to prioritize promising hypotheses, we aim to improve the efficiency of the hypothesis generation and evaluation process. We hope this approach offers a new avenue for exploration and contributes to the ongoing dialogue in the field.
Representation Reliability and Its Impact on Downstream Tasks
May 31, 2023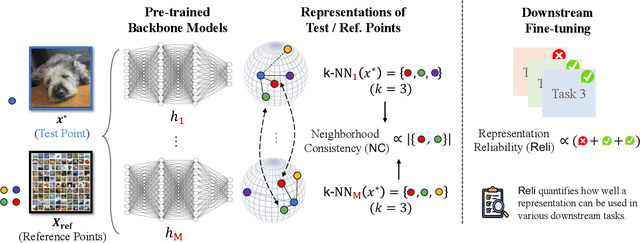
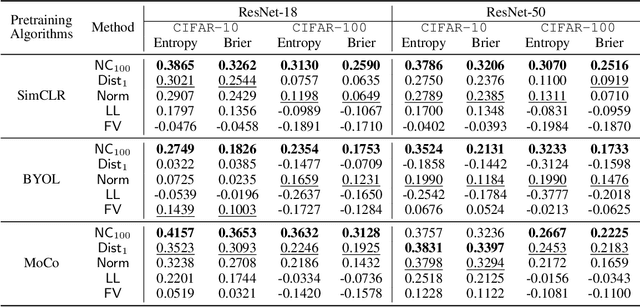
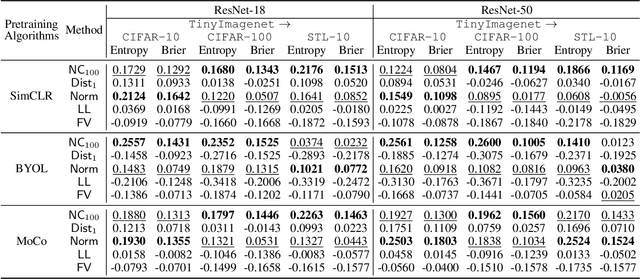
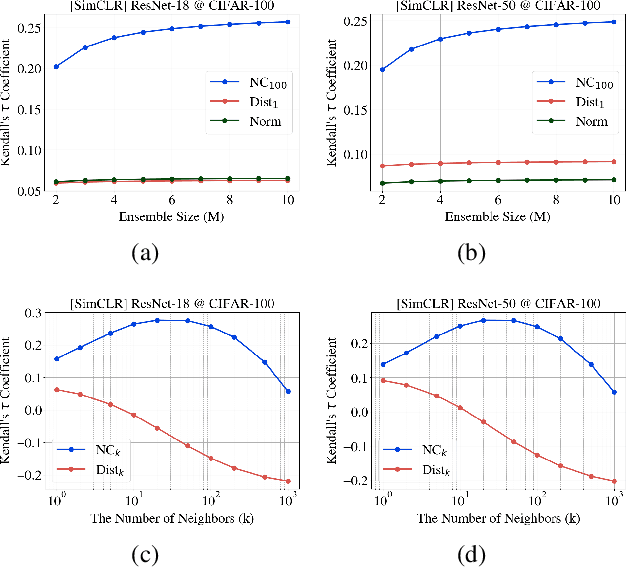
Self-supervised pre-trained models extract general-purpose representations from data, and quantifying how reliable they are is crucial because many downstream models use these representations as input for their own tasks. To this end, we first introduce a formal definition of representation reliability: the representation for a given test input is considered to be reliable if the downstream models built on top of that representation can consistently generate accurate predictions for that test point. It is desired to estimate the representation reliability without knowing the downstream tasks a priori. We provide a negative result showing that existing frameworks for uncertainty quantification in supervised learning are not suitable for this purpose. As an alternative, we propose an ensemble-based method for quantifying representation reliability, based on the concept of neighborhood consistency in the representation spaces across various pre-trained models. More specifically, the key insight is to use shared neighboring points as anchors to align different representation spaces. We demonstrate through comprehensive numerical experiments that our method is capable of predicting representation reliability with high accuracy.
LLM2Loss: Leveraging Language Models for Explainable Model Diagnostics
May 04, 2023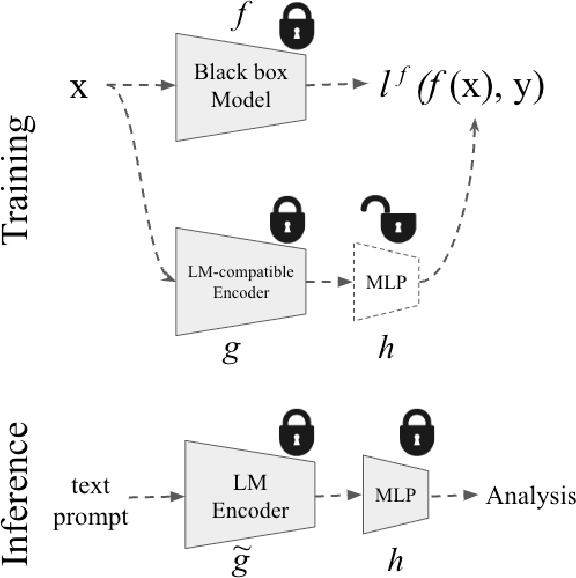

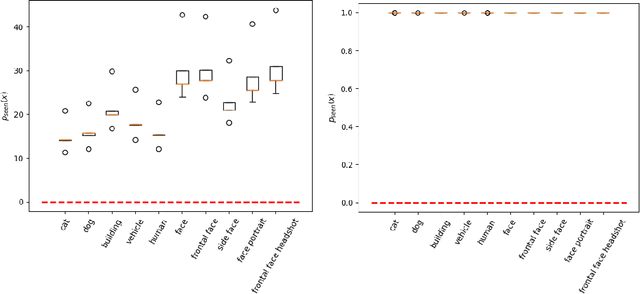

Trained on a vast amount of data, Large Language models (LLMs) have achieved unprecedented success and generalization in modeling fairly complex textual inputs in the abstract space, making them powerful tools for zero-shot learning. Such capability is extended to other modalities such as the visual domain using cross-modal foundation models such as CLIP, and as a result, semantically meaningful representation are extractable from visual inputs. In this work, we leverage this capability and propose an approach that can provide semantic insights into a model's patterns of failures and biases. Given a black box model, its training data, and task definition, we first calculate its task-related loss for each data point. We then extract a semantically meaningful representation for each training data point (such as CLIP embeddings from its visual encoder) and train a lightweight diagnosis model which maps this semantically meaningful representation of a data point to its task loss. We show that an ensemble of such lightweight models can be used to generate insights on the performance of the black-box model, in terms of identifying its patterns of failures and biases.
Improving Identity-Robustness for Face Models
Apr 07, 2023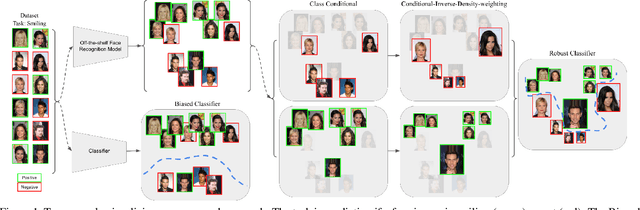
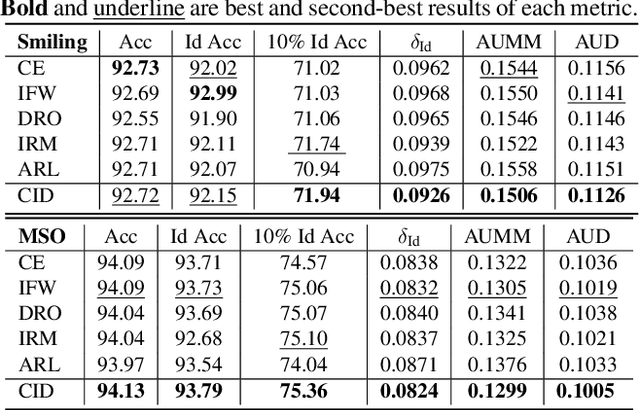
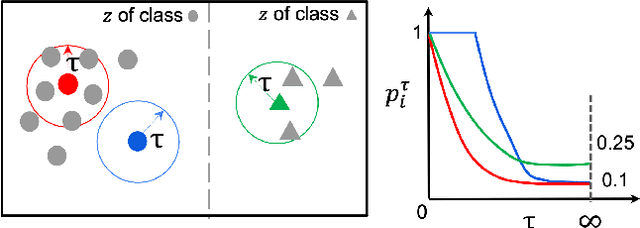
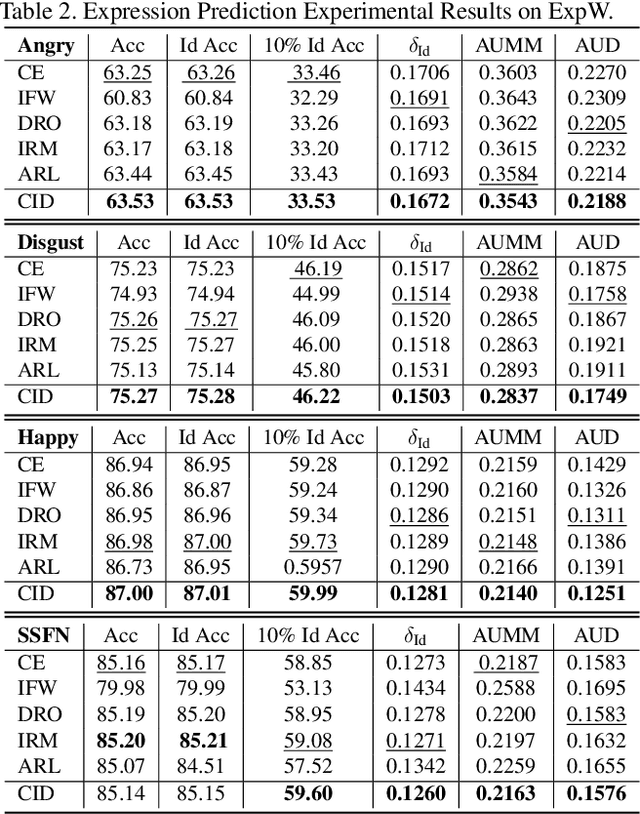
Despite the success of deep-learning models in many tasks, there have been concerns about such models learning shortcuts, and their lack of robustness to irrelevant confounders. When it comes to models directly trained on human faces, a sensitive confounder is that of human identities. Many face-related tasks should ideally be identity-independent, and perform uniformly across different individuals (i.e. be fair). One way to measure and enforce such robustness and performance uniformity is through enforcing it during training, assuming identity-related information is available at scale. However, due to privacy concerns and also the cost of collecting such information, this is often not the case, and most face datasets simply contain input images and their corresponding task-related labels. Thus, improving identity-related robustness without the need for such annotations is of great importance. Here, we explore using face-recognition embedding vectors, as proxies for identities, to enforce such robustness. We propose to use the structure in the face-recognition embedding space, to implicitly emphasize rare samples within each class. We do so by weighting samples according to their conditional inverse density (CID) in the proxy embedding space. Our experiments suggest that such a simple sample weighting scheme, not only improves the training robustness, it often improves the overall performance as a result of such robustness. We also show that employing such constraints during training results in models that are significantly less sensitive to different levels of bias in the dataset.
Fairness via Adversarial Attribute Neighbourhood Robust Learning
Oct 12, 2022

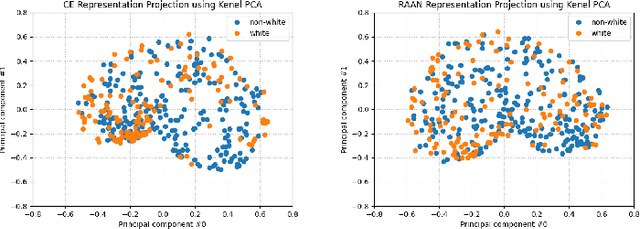
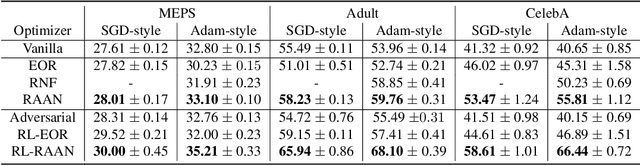
Improving fairness between privileged and less-privileged sensitive attribute groups (e.g, {race, gender}) has attracted lots of attention. To enhance the model performs uniformly well in different sensitive attributes, we propose a principled \underline{R}obust \underline{A}dversarial \underline{A}ttribute \underline{N}eighbourhood (RAAN) loss to debias the classification head and promote a fairer representation distribution across different sensitive attribute groups. The key idea of RAAN is to mitigate the differences of biased representations between different sensitive attribute groups by assigning each sample an adversarial robust weight, which is defined on the representations of adversarial attribute neighbors, i.e, the samples from different protected groups. To provide efficient optimization algorithms, we cast the RAAN into a sum of coupled compositional functions and propose a stochastic adaptive (Adam-style) and non-adaptive (SGD-style) algorithm framework SCRAAN with provable theoretical guarantee. Extensive empirical studies on fairness-related benchmark datasets verify the effectiveness of the proposed method.
Uncertainty in Contrastive Learning: On the Predictability of Downstream Performance
Jul 19, 2022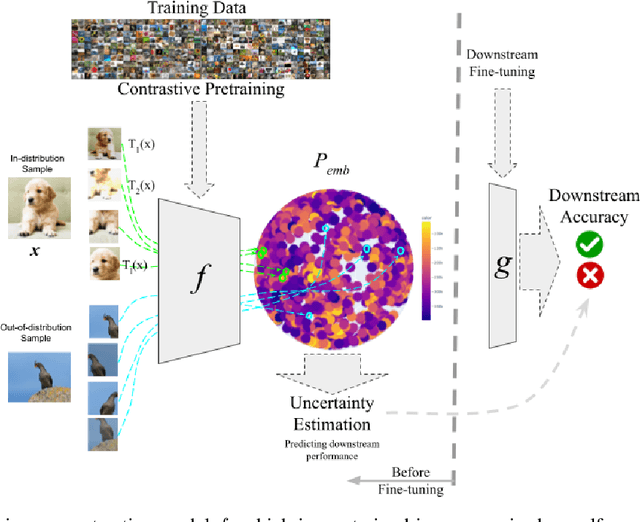

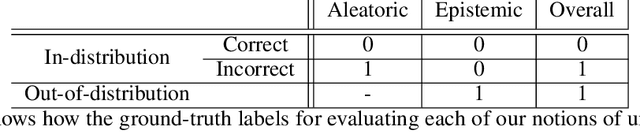
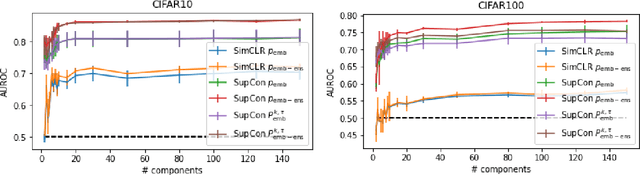
The superior performance of some of today's state-of-the-art deep learning models is to some extent owed to extensive (self-)supervised contrastive pretraining on large-scale datasets. In contrastive learning, the network is presented with pairs of positive (similar) and negative (dissimilar) datapoints and is trained to find an embedding vector for each datapoint, i.e., a representation, which can be further fine-tuned for various downstream tasks. In order to safely deploy these models in critical decision-making systems, it is crucial to equip them with a measure of their uncertainty or reliability. However, due to the pairwise nature of training a contrastive model, and the lack of absolute labels on the output (an abstract embedding vector), adapting conventional uncertainty estimation techniques to such models is non-trivial. In this work, we study whether the uncertainty of such a representation can be quantified for a single datapoint in a meaningful way. In other words, we explore if the downstream performance on a given datapoint is predictable, directly from its pre-trained embedding. We show that this goal can be achieved by directly estimating the distribution of the training data in the embedding space and accounting for the local consistency of the representations. Our experiments show that this notion of uncertainty for an embedding vector often strongly correlates with its downstream accuracy.
On Negative Sampling for Audio-Visual Contrastive Learning from Movies
Apr 29, 2022
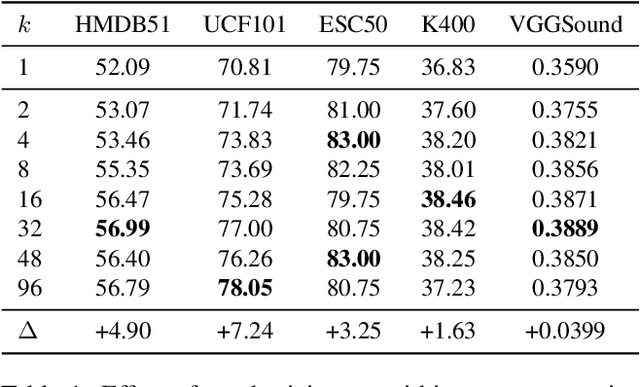
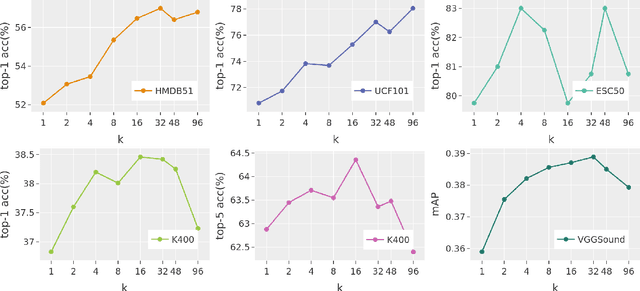
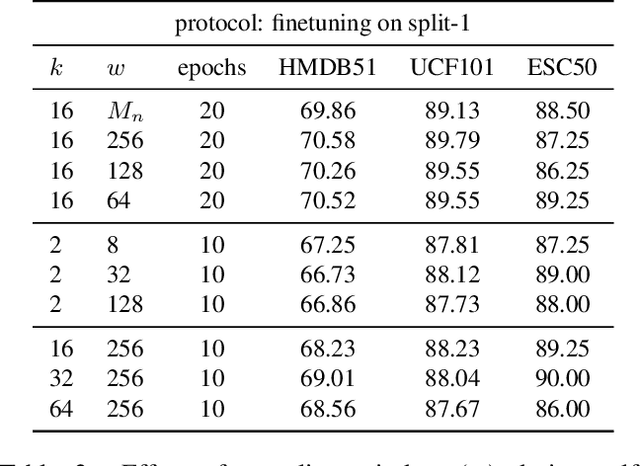
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal a plethora of information about what happens in a scene, make the audio-visual space an intuitive choice for representation learning. In this paper, we explore the efficacy of audio-visual self-supervised learning from uncurated long-form content i.e movies. Studying its differences with conventional short-form content, we identify a non-i.i.d distribution of data, driven by the nature of movies. Specifically, we find long-form content to naturally contain a diverse set of semantic concepts (semantic diversity), where a large portion of them, such as main characters and environments often reappear frequently throughout the movie (reoccurring semantic concepts). In addition, movies often contain content-exclusive artistic artifacts, such as color palettes or thematic music, which are strong signals for uniquely distinguishing a movie (non-semantic consistency). Capitalizing on these observations, we comprehensively study the effect of emphasizing within-movie negative sampling in a contrastive learning setup. Our view is different from those of prior works who consider within-video positive sampling, inspired by the notion of semantic persistency over time, and operate in a short-video regime. Our empirical findings suggest that, with certain modifications, training on uncurated long-form videos yields representations which transfer competitively with the state-of-the-art to a variety of action recognition and audio classification tasks.
Character-focused Video Thumbnail Retrieval
Apr 13, 2022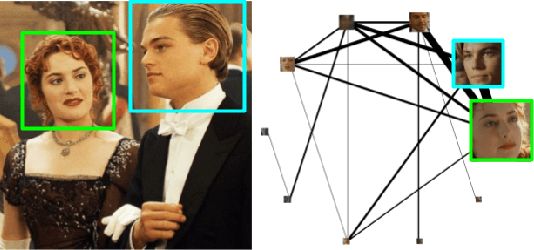
We explore retrieving character-focused video frames as candidates for being video thumbnails. To evaluate each frame of the video based on the character(s) present in it, characters (faces) are evaluated in two aspects: Facial-expression: We train a CNN model to measure whether a face has an acceptable facial expression for being in a video thumbnail. This model is trained to distinguish faces extracted from artworks/thumbnails, from faces extracted from random frames of videos. Prominence and interactions: Character(s) in the thumbnail should be important character(s) in the video, to prevent the algorithm from suggesting non-representative frames as candidates. We use face clustering to identify the characters in the video, and form a graph in which the prominence (frequency of appearance) of the character(s), and their interactions (co-occurrence) are captured. We use this graph to infer the relevance of the characters present in each candidate frame. Once every face is scored based on the two criteria above, we infer frame level scores by combining the scores for all the faces within a frame.
Estimating Structural Disparities for Face Models
Apr 13, 2022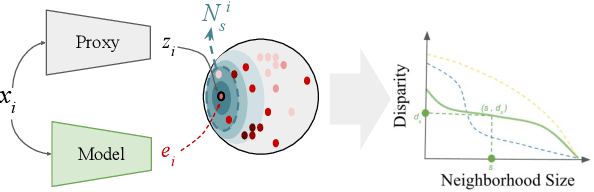
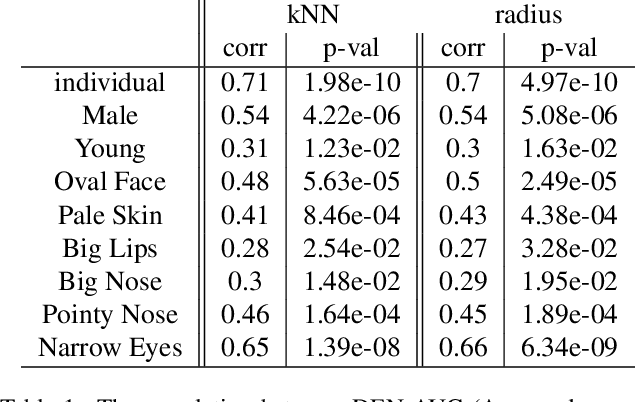


In machine learning, disparity metrics are often defined by measuring the difference in the performance or outcome of a model, across different sub-populations (groups) of datapoints. Thus, the inputs to disparity quantification consist of a model's predictions $\hat{y}$, the ground-truth labels for the predictions $y$, and group labels $g$ for the data points. Performance of the model for each group is calculated by comparing $\hat{y}$ and $y$ for the datapoints within a specific group, and as a result, disparity of performance across the different groups can be calculated. In many real world scenarios however, group labels ($g$) may not be available at scale during training and validation time, or collecting them might not be feasible or desirable as they could often be sensitive information. As a result, evaluating disparity metrics across categorical groups would not be feasible. On the other hand, in many scenarios noisy groupings may be obtainable using some form of a proxy, which would allow measuring disparity metrics across sub-populations. Here we explore performing such analysis on computer vision models trained on human faces, and on tasks such as face attribute prediction and affect estimation. Our experiments indicate that embeddings resulting from an off-the-shelf face recognition model, could meaningfully serve as a proxy for such estimation.
On Attention Modules for Audio-Visual Synchronization
Dec 14, 2018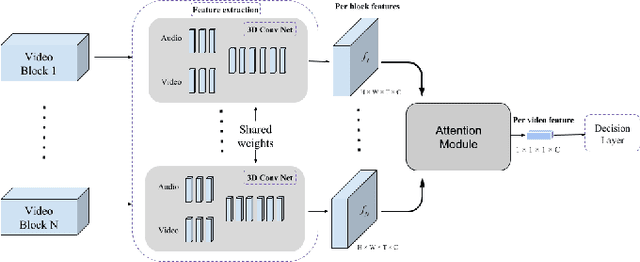
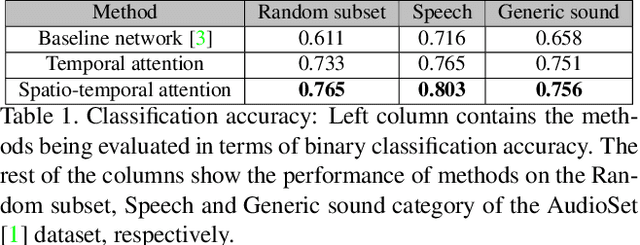
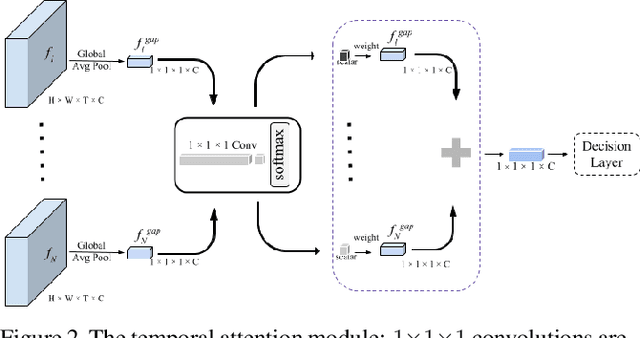
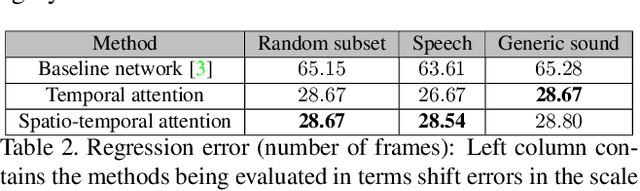
With the development of media and networking technologies, multimedia applications ranging from feature presentation in a cinema setting to video on demand to interactive video conferencing are in great demand. Good synchronization between audio and video modalities is a key factor towards defining the quality of a multimedia presentation. The audio and visual signals of a multimedia presentation are commonly managed by independent workflows - they are often separately authored, processed, stored and even delivered to the playback system. This opens up the possibility of temporal misalignment between the two modalities - such a tendency is often more pronounced in the case of produced content (such as movies). To judge whether audio and video signals of a multimedia presentation are synchronized, we as humans often pay close attention to discriminative spatio-temporal blocks of the video (e.g. synchronizing the lip movement with the utterance of words, or the sound of a bouncing ball at the moment it hits the ground). At the same time, we ignore large portions of the video in which no discriminative sounds exist (e.g. background music playing in a movie). Inspired by this observation, we study leveraging attention modules for automatically detecting audio-visual synchronization. We propose neural network based attention modules, capable of weighting different portions (spatio-temporal blocks) of the video based on their respective discriminative power. Our experiments indicate that incorporating attention modules yields state-of-the-art results for the audio-visual synchronization classification problem.