 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Sound: Assembling Sounds from Visuals for Audio-to-Image Generation
Jan 09, 2025Training audio-to-image generative models requires an abundance of diverse audio-visual pairs that are semantically aligned. Such data is almost always curated from in-the-wild videos, given the cross-modal semantic correspondence that is inherent to them. In this work, we hypothesize that insisting on the absolute need for ground truth audio-visual correspondence, is not only unnecessary, but also leads to severe restrictions in scale, quality, and diversity of the data, ultimately impairing its use in the modern generative models. That is, we propose a scalable image sonification framework where instances from a variety of high-quality yet disjoint uni-modal origins can be artificially paired through a retrieval process that is empowered by reasoning capabilities of modern vision-language models. To demonstrate the efficacy of this approach, we use our sonified images to train an audio-to-image generative model that performs competitively against state-of-the-art. Finally, through a series of ablation studies, we exhibit several intriguing auditory capabilities like semantic mixing and interpolation, loudness calibration and acoustic space modeling through reverberation that our model has implicitly developed to guide the image generation process.
On Negative Sampling for Audio-Visual Contrastive Learning from Movies
Apr 29, 2022
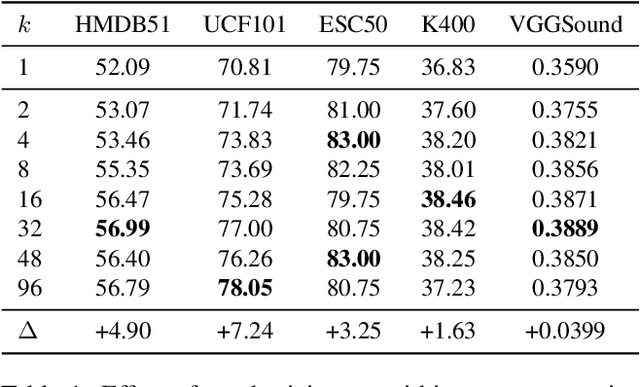
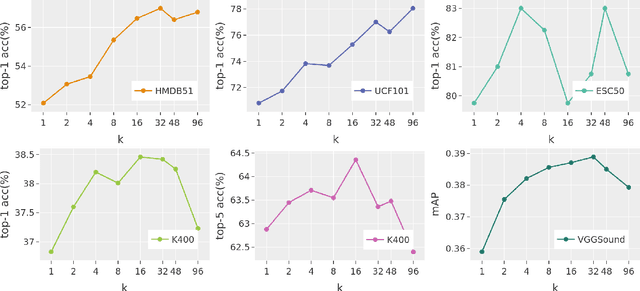
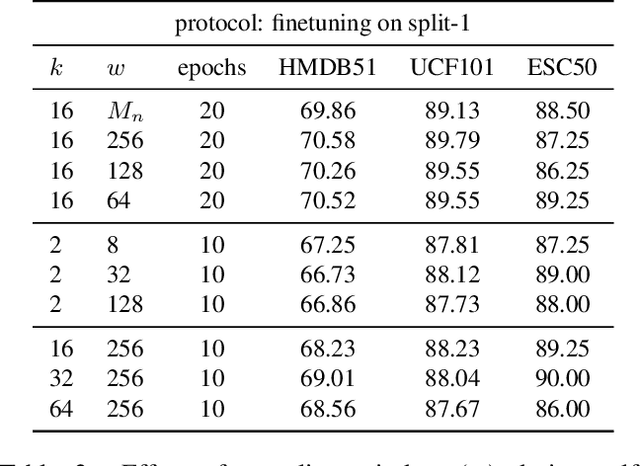
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal a plethora of information about what happens in a scene, make the audio-visual space an intuitive choice for representation learning. In this paper, we explore the efficacy of audio-visual self-supervised learning from uncurated long-form content i.e movies. Studying its differences with conventional short-form content, we identify a non-i.i.d distribution of data, driven by the nature of movies. Specifically, we find long-form content to naturally contain a diverse set of semantic concepts (semantic diversity), where a large portion of them, such as main characters and environments often reappear frequently throughout the movie (reoccurring semantic concepts). In addition, movies often contain content-exclusive artistic artifacts, such as color palettes or thematic music, which are strong signals for uniquely distinguishing a movie (non-semantic consistency). Capitalizing on these observations, we comprehensively study the effect of emphasizing within-movie negative sampling in a contrastive learning setup. Our view is different from those of prior works who consider within-video positive sampling, inspired by the notion of semantic persistency over time, and operate in a short-video regime. Our empirical findings suggest that, with certain modifications, training on uncurated long-form videos yields representations which transfer competitively with the state-of-the-art to a variety of action recognition and audio classification tasks.
Watching Too Much Television is Good: Self-Supervised Audio-Visual Representation Learning from Movies and TV Shows
Jun 16, 2021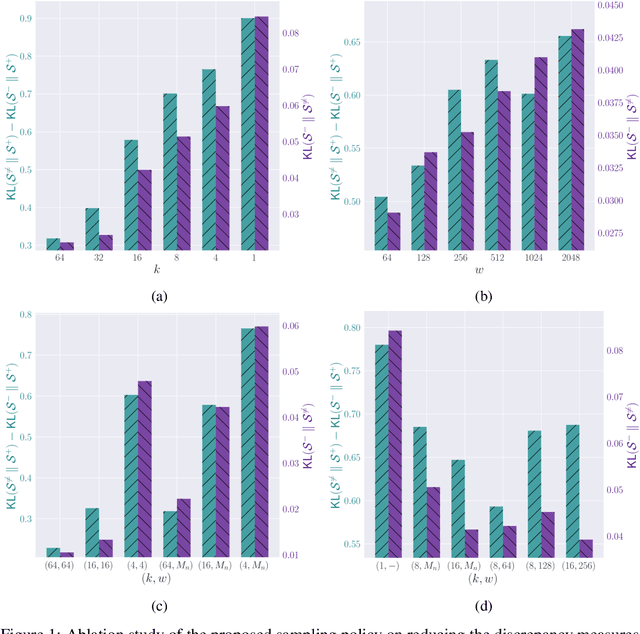
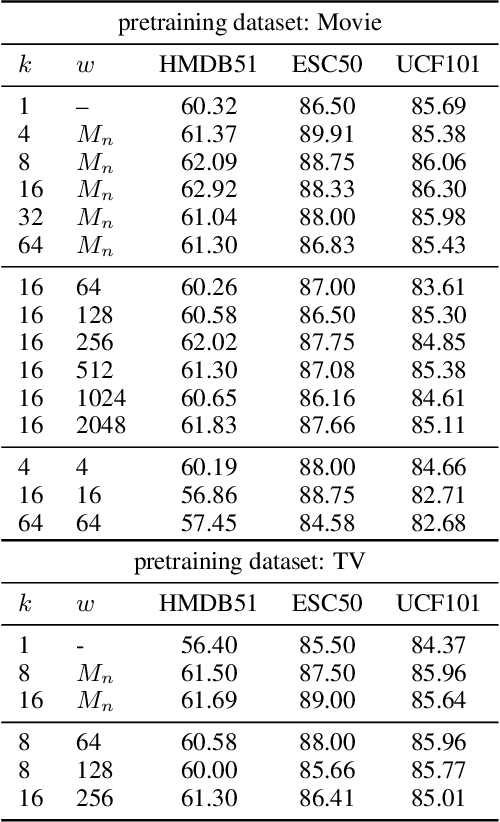
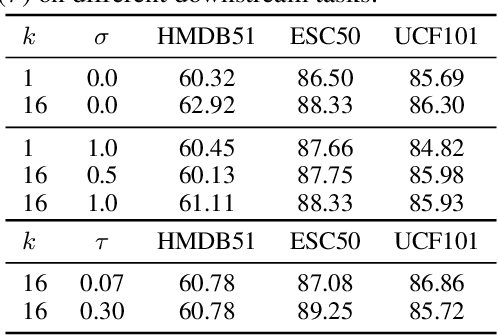
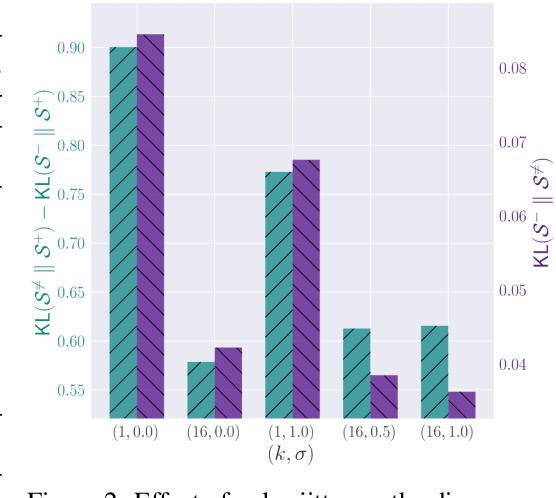
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal so much about what happens in the scene, make the audio-visual space a perfectly intuitive choice for self-supervised representation learning. However, the current literature suggests that training on \textit{uncurated} data yields considerably poorer representations compared to the \textit{curated} alternatives collected in supervised manner, and the gap only narrows when the volume of data significantly increases. Furthermore, the quality of learned representations is known to be heavily influenced by the size and taxonomy of the curated datasets used for self-supervised training. This begs the question of whether we are celebrating too early on catching up with supervised learning when our self-supervised efforts still rely almost exclusively on curated data. In this paper, we study the efficacy of learning from Movies and TV Shows as forms of uncurated data for audio-visual self-supervised learning. We demonstrate that a simple model based on contrastive learning, trained on a collection of movies and TV shows, not only dramatically outperforms more complex methods which are trained on orders of magnitude larger uncurated datasets, but also performs very competitively with the state-of-the-art that learns from large-scale curated data. We identify that audiovisual patterns like the appearance of the main character or prominent scenes and mise-en-sc\`ene which frequently occur through the whole duration of a movie, lead to an overabundance of easy negative instances in the contrastive learning formulation. Capitalizing on such observation, we propose a hierarchical sampling policy, which despite its simplicity, effectively improves the performance, particularly when learning from TV shows which naturally face less semantic diversity.
On Symbiosis of Attribute Prediction and Semantic Segmentation
Nov 23, 2019
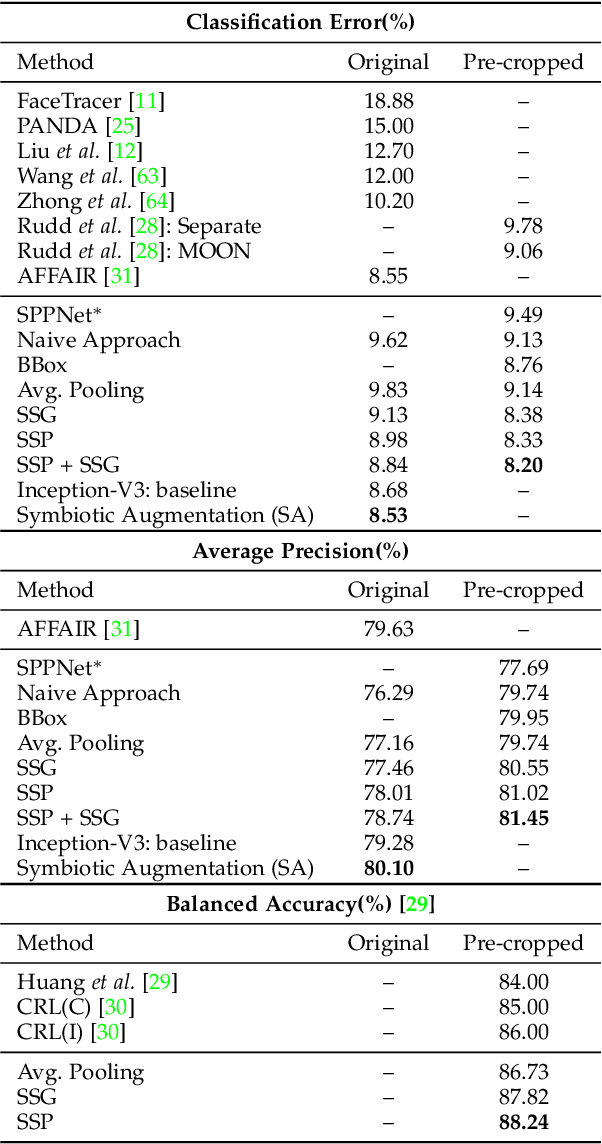


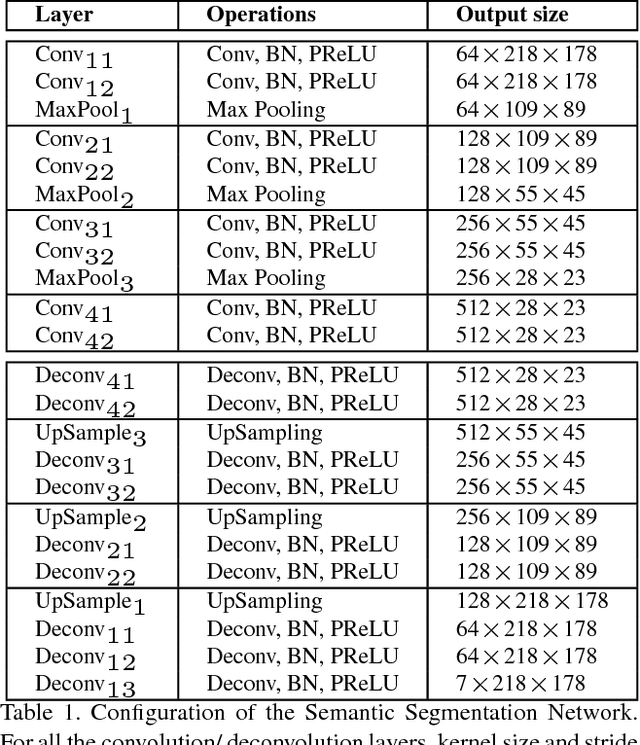
In this paper, we propose to employ semantic segmentation to improve person-related attribute prediction. The core idea lies in the fact that the probability of an attribute to appear in an image is far from being uniform in the spatial domain. We build our attribute prediction model jointly with a deep semantic segmentation network. This harnesses the localization cues learned by the semantic segmentation to guide the attention of the attribute prediction to the regions where different attributes naturally show up. Therefore, in addition to prediction, we are able to localize the attributes despite merely having access to image-level labels (weak supervision) during training. We first propose semantic segmentation-based pooling and gating, respectively denoted as SSP and SSG. In the former, the estimated segmentation masks are used to pool the final activations of the attribute prediction network, from multiple semantically homogeneous regions. In SSG, the same idea is applied to the intermediate layers of the network. SSP and SSG, while effective, impose heavy memory utilization since each channel of the activations is pooled/gated with all the semantic segmentation masks. To circumvent this, we propose Symbiotic Augmentation (SA), where we learn only one mask per activation channel. SA allows the model to either pick one, or combine (weighted superposition) multiple semantic maps, in order to generate the proper mask for each channel. SA simultaneously applies the same mechanism to the reverse problem by leveraging output logits of attribute prediction to guide the semantic segmentation task. We evaluate our proposed methods for facial attributes on CelebA and LFWA datasets, while benchmarking WIDER Attribute and Berkeley Attributes of People for whole body attributes. Our proposed methods achieve superior results compared to the previous works.
Training Faster by Separating Modes of Variation in Batch-normalized Models
Jun 07, 2018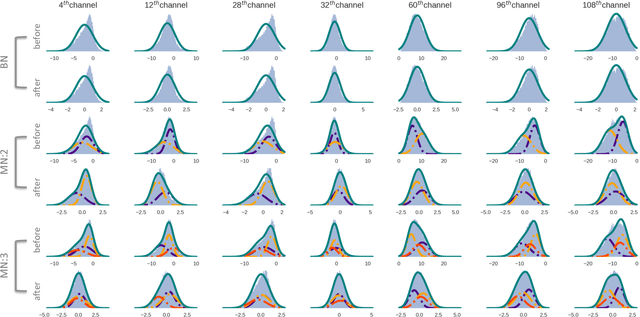


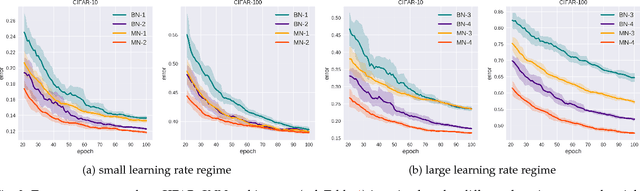
Batch Normalization (BN) is essential to effectively train state-of-the-art deep Convolutional Neural Networks (CNN). It normalizes inputs to the layers during training using the statistics of each mini-batch. In this work, we study BN from the viewpoint of Fisher kernels. We show that assuming samples within a mini-batch are from the same probability density function, then BN is identical to the Fisher vector of a Gaussian distribution. That means BN can be explained in terms of kernels that naturally emerge from the probability density function of the underlying data distribution. However, given the rectifying non-linearities employed in CNN architectures, distribution of inputs to the layers show heavy tail and asymmetric characteristics. Therefore, we propose approximating underlying data distribution not with one, but a mixture of Gaussian densities. Deriving Fisher vector for a Gaussian Mixture Model (GMM), reveals that BN can be improved by independently normalizing with respect to the statistics of disentangled sub-populations. We refer to our proposed soft piecewise version of BN as Mixture Normalization (MN). Through extensive set of experiments on CIFAR-10 and CIFAR-100, we show that MN not only effectively accelerates training image classification and Generative Adversarial networks, but also reaches higher quality models.
Human Semantic Parsing for Person Re-identification
Mar 31, 2018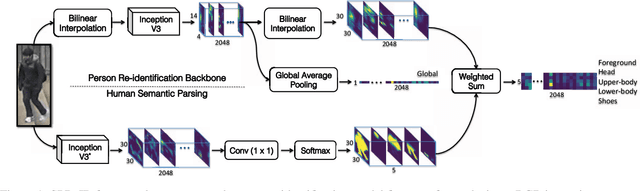
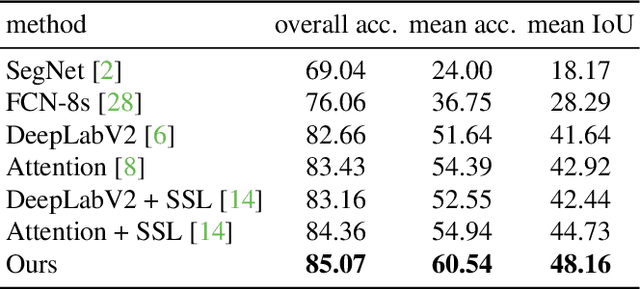
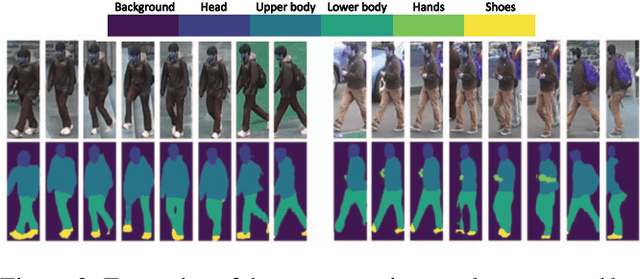
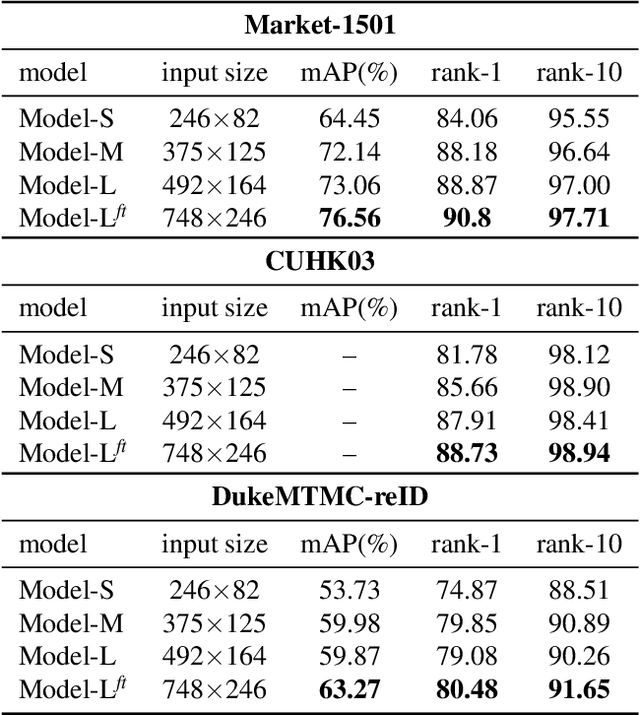
Person re-identification is a challenging task mainly due to factors such as background clutter, pose, illumination and camera point of view variations. These elements hinder the process of extracting robust and discriminative representations, hence preventing different identities from being successfully distinguished. To improve the representation learning, usually, local features from human body parts are extracted. However, the common practice for such a process has been based on bounding box part detection. In this paper, we propose to adopt human semantic parsing which, due to its pixel-level accuracy and capability of modeling arbitrary contours, is naturally a better alternative. Our proposed SPReID integrates human semantic parsing in person re-identification and not only considerably outperforms its counter baseline, but achieves state-of-the-art performance. We also show that by employing a \textit{simple} yet effective training strategy, standard popular deep convolutional architectures such as Inception-V3 and ResNet-152, with no modification, while operating solely on full image, can dramatically outperform current state-of-the-art. Our proposed methods improve state-of-the-art person re-identification on: Market-1501 by ~17% in mAP and ~6% in rank-1, CUHK03 by ~4% in rank-1 and DukeMTMC-reID by ~24% in mAP and ~10% in rank-1.
Improving Facial Attribute Prediction using Semantic Segmentation
Apr 27, 2017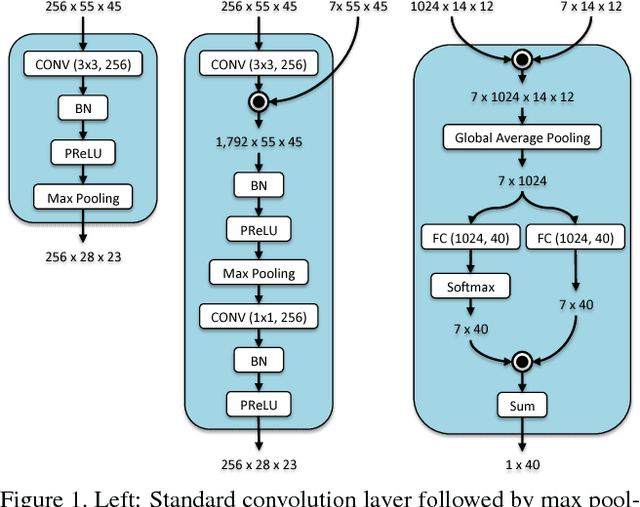


Attributes are semantically meaningful characteristics whose applicability widely crosses category boundaries. They are particularly important in describing and recognizing concepts where no explicit training example is given, \textit{e.g., zero-shot learning}. Additionally, since attributes are human describable, they can be used for efficient human-computer interaction. In this paper, we propose to employ semantic segmentation to improve facial attribute prediction. The core idea lies in the fact that many facial attributes describe local properties. In other words, the probability of an attribute to appear in a face image is far from being uniform in the spatial domain. We build our facial attribute prediction model jointly with a deep semantic segmentation network. This harnesses the localization cues learned by the semantic segmentation to guide the attention of the attribute prediction to the regions where different attributes naturally show up. As a result of this approach, in addition to recognition, we are able to localize the attributes, despite merely having access to image level labels (weak supervision) during training. We evaluate our proposed method on CelebA and LFWA datasets and achieve superior results to the prior arts. Furthermore, we show that in the reverse problem, semantic face parsing improves when facial attributes are available. That reaffirms the need to jointly model these two interconnected tasks.
Understanding Trajectory Behavior: A Motion Pattern Approach
Jan 04, 2015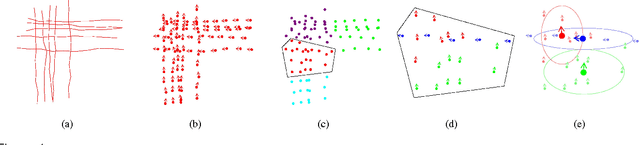
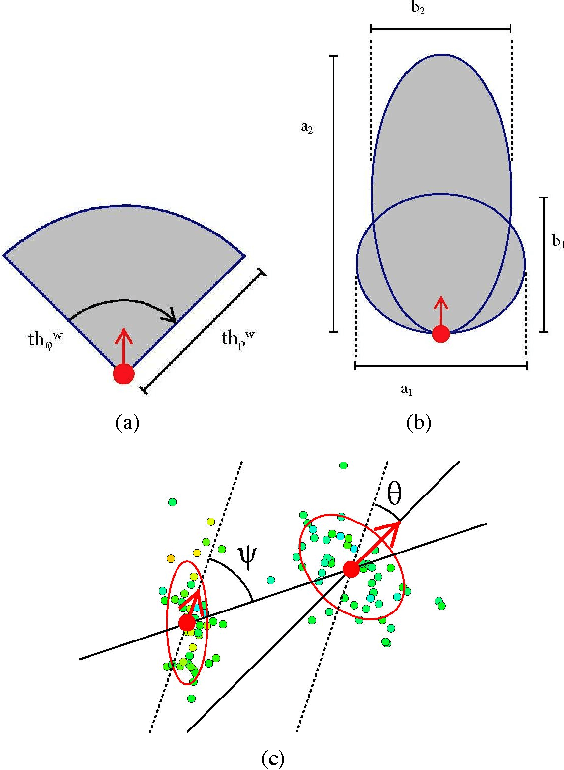
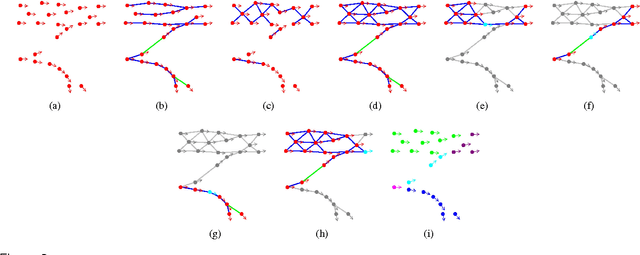

Mining the underlying patterns in gigantic and complex data is of great importance to data analysts. In this paper, we propose a motion pattern approach to mine frequent behaviors in trajectory data. Motion patterns, defined by a set of highly similar flow vector groups in a spatial locality, have been shown to be very effective in extracting dominant motion behaviors in video sequences. Inspired by applications and properties of motion patterns, we have designed a framework that successfully solves the general task of trajectory clustering. Our proposed algorithm consists of four phases: flow vector computation, motion component extraction, motion component's reachability set creation, and motion pattern formation. For the first phase, we break down trajectories into flow vectors that indicate instantaneous movements. In the second phase, via a Kmeans clustering approach, we create motion components by clustering the flow vectors with respect to their location and velocity. Next, we create motion components' reachability set in terms of spatial proximity and motion similarity. Finally, for the fourth phase, we cluster motion components using agglomerative clustering with the weighted Jaccard distance between the motion components' signatures, a set created using path reachability. We have evaluated the effectiveness of our proposed method in an extensive set of experiments on diverse datasets. Further, we have shown how our proposed method handles difficulties in the general task of trajectory clustering that challenge the existing state-of-the-art methods.