 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Facial Attribute Prediction using Semantic Segmentation
Paper and Code
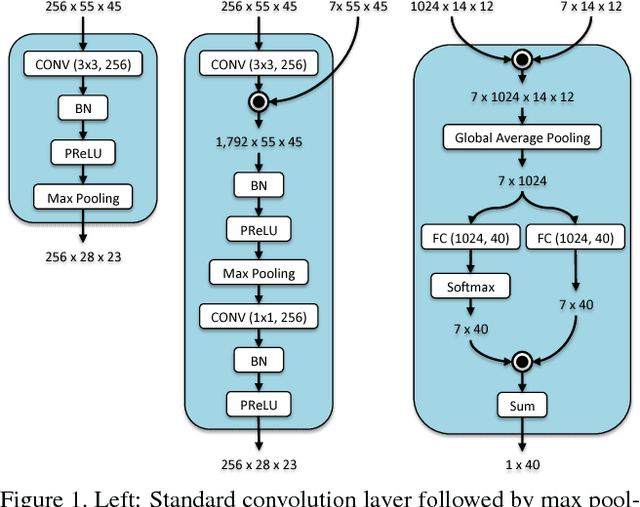
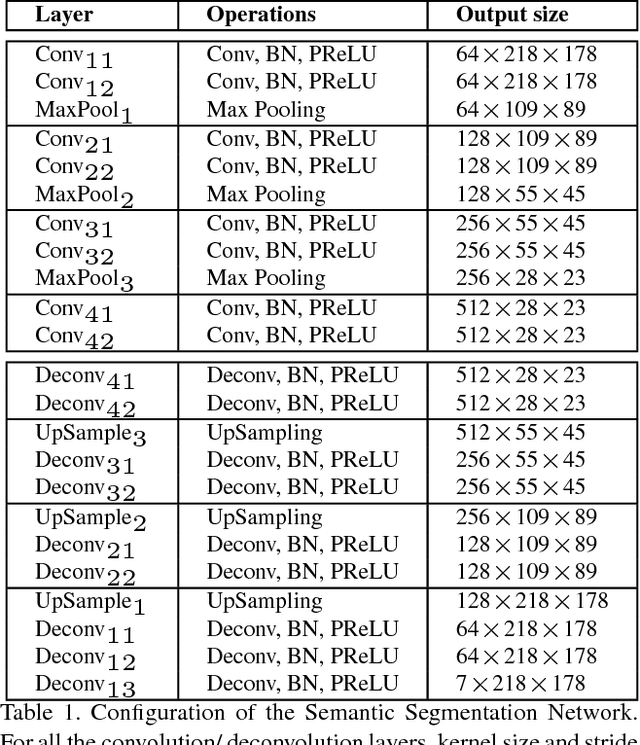


Attributes are semantically meaningful characteristics whose applicability widely crosses category boundaries. They are particularly important in describing and recognizing concepts where no explicit training example is given, \textit{e.g., zero-shot learning}. Additionally, since attributes are human describable, they can be used for efficient human-computer interaction. In this paper, we propose to employ semantic segmentation to improve facial attribute prediction. The core idea lies in the fact that many facial attributes describe local properties. In other words, the probability of an attribute to appear in a face image is far from being uniform in the spatial domain. We build our facial attribute prediction model jointly with a deep semantic segmentation network. This harnesses the localization cues learned by the semantic segmentation to guide the attention of the attribute prediction to the regions where different attributes naturally show up. As a result of this approach, in addition to recognition, we are able to localize the attributes, despite merely having access to image level labels (weak supervision) during training. We evaluate our proposed method on CelebA and LFWA datasets and achieve superior results to the prior arts. Furthermore, we show that in the reverse problem, semantic face parsing improves when facial attributes are available. That reaffirms the need to jointly model these two interconnected tasks.