 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Negative Sampling for Audio-Visual Contrastive Learning from Movies
Paper and Code
Apr 29, 2022
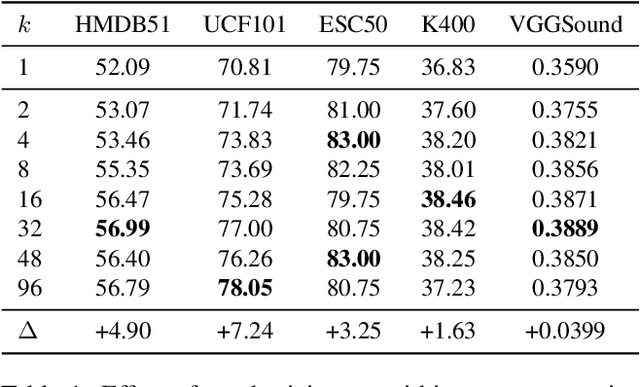
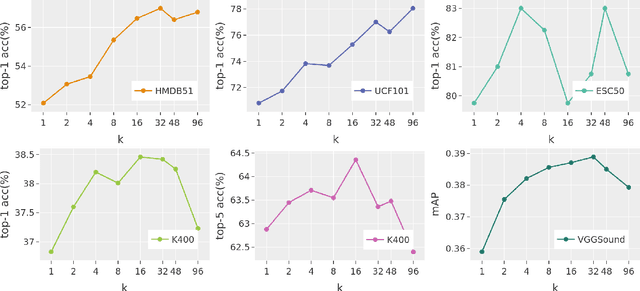
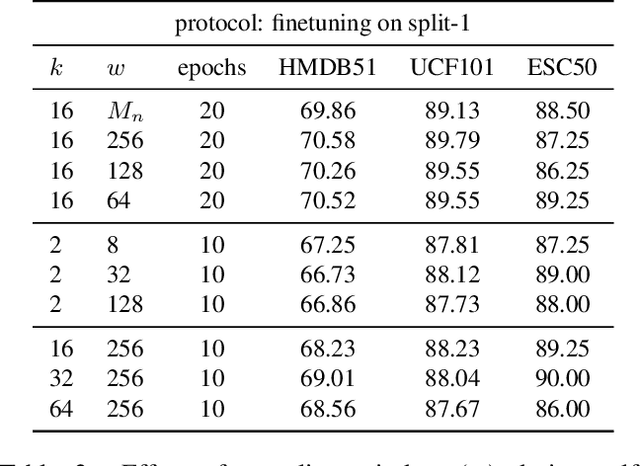
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal a plethora of information about what happens in a scene, make the audio-visual space an intuitive choice for representation learning. In this paper, we explore the efficacy of audio-visual self-supervised learning from uncurated long-form content i.e movies. Studying its differences with conventional short-form content, we identify a non-i.i.d distribution of data, driven by the nature of movies. Specifically, we find long-form content to naturally contain a diverse set of semantic concepts (semantic diversity), where a large portion of them, such as main characters and environments often reappear frequently throughout the movie (reoccurring semantic concepts). In addition, movies often contain content-exclusive artistic artifacts, such as color palettes or thematic music, which are strong signals for uniquely distinguishing a movie (non-semantic consistency). Capitalizing on these observations, we comprehensively study the effect of emphasizing within-movie negative sampling in a contrastive learning setup. Our view is different from those of prior works who consider within-video positive sampling, inspired by the notion of semantic persistency over time, and operate in a short-video regime. Our empirical findings suggest that, with certain modifications, training on uncurated long-form videos yields representations which transfer competitively with the state-of-the-art to a variety of action recognition and audio classification tasks.