 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Framework for Visible-Infrared Cross Modality Person Re-Identification
Jul 15, 2019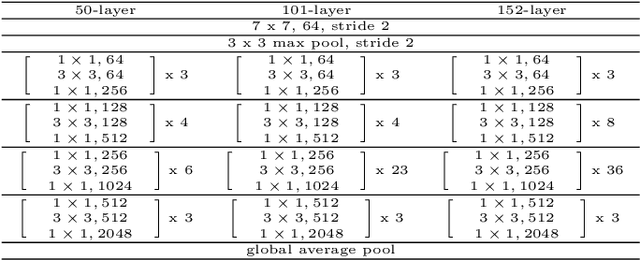
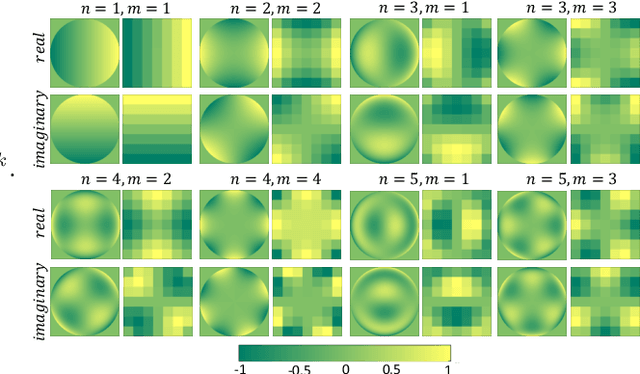

Visible-infrared cross modality person re-identification (VI-ReId) is an important task for video surveillance in poorly illuminated or dark environments. Despite many recent studies on person re-identification in visible domain (ReId), there are few studies dealing with VI-ReId. Besides challenges that are common for both ReId and VI-ReId such as pose/illumination variations, background clutter and occlusion, VI-ReId has additional challenges as color information is not available in infrared images. As a result, the performance of VI-ReId systems is typically lower than ReId systems. In this work, we propose a 4-stream framework to improve VI-ReId performance. We train a separate deep convolutional neural network in each stream using different representations of input images. We expect that different and complementary features can be learned from each stream. In our framework, grayscale and infrared input images are used to train the ResNet in the first stream. In the second stream, RGB and 3-channel infrared images (created by repeating infrared channel) are used. In the remaining two streams, we use local pattern maps as input images. These maps are generated utilizing local Zernike moments transformation. Local pattern maps are obtained from grayscale and infrared images in the 3rd stream and from RGB and 3-channel infrared images in the last stream. We improve the performance of the proposed framework by employing a re-ranking algorithm for post processing. Our results indicate that the proposed framework outperforms current state-of-the-art on SYSU-MM01 dataset with large margin by improving Rank-1/mAP by 34.2%/37.9% and 37.4%/34.8% under all-search and indoor-search modes, respectively.
EgoReID: Person re-identification in Egocentric Videos Acquired by Mobile Devices with First-Person Point-of-View
Dec 22, 2018
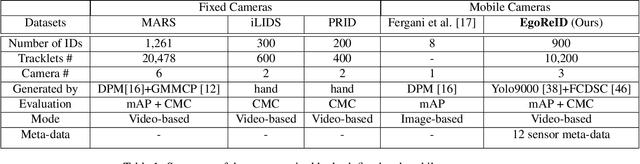
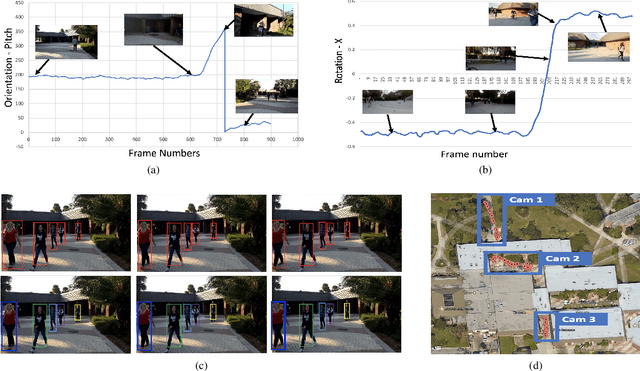
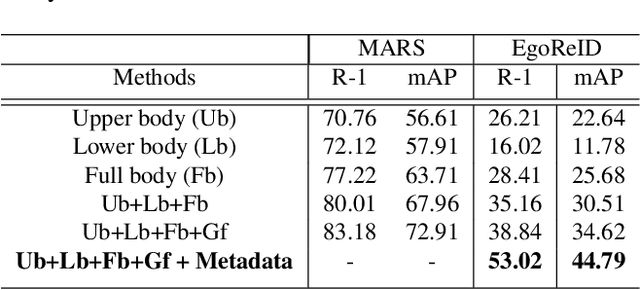
Widespread use of wearable cameras and recording devices such as cellphones have opened the door to a lot of interesting research in first-person Point-of-view (POV) videos (egocentric videos). In recent years, we have seen the performance of video-based person Re-Identification (ReID) methods improve considerably. However, with the influx of varying video domains, such as egocentric videos, it has become apparent that there are still many open challenges to be faced. These challenges are a result of factors such as poor video quality due to ego-motion, blurriness, severe changes in lighting conditions and perspective distortions. To facilitate the research towards conquering these challenges, this paper contributes a new, first-of-its-kind dataset called EgoReID. The dataset is captured using 3 mobile cellphones with non-overlapping field-of-view. It contains 900 IDs and around 10,200 tracks with a total of 176,000 detections. Moreover, for each video we also provide 12-sensor meta data. Directly applying current approaches to our dataset results in poor performance. Considering the unique nature of our dataset, we propose a new framework which takes advantage of both visual and sensor meta data to successfully perform Person ReID. In this paper, we propose to adopt human body region parsing to extract local features from different body regions and then employ 3D convolution to better encode temporal information of each sequence of body parts. In addition, we also employ sensor meta data to determine target's next camera and their estimated time of arrival, such that the search is only performed among tracks present in the predicted next camera around the estimated time. This considerably improves our ReID performance as it significantly reduces our search space.
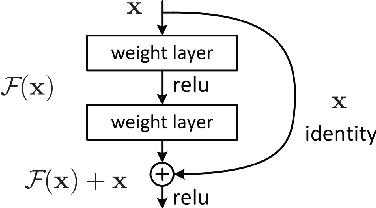
Human Semantic Parsing for Person Re-identification
Mar 31, 2018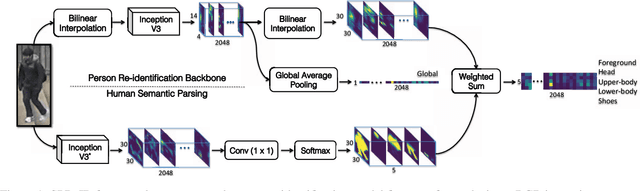
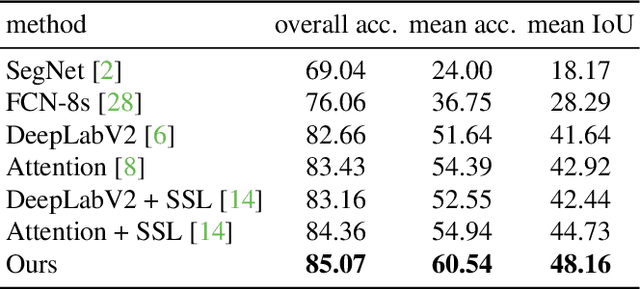
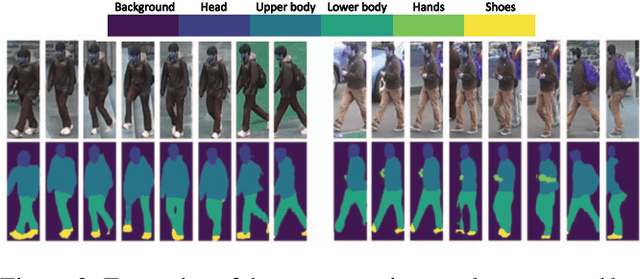
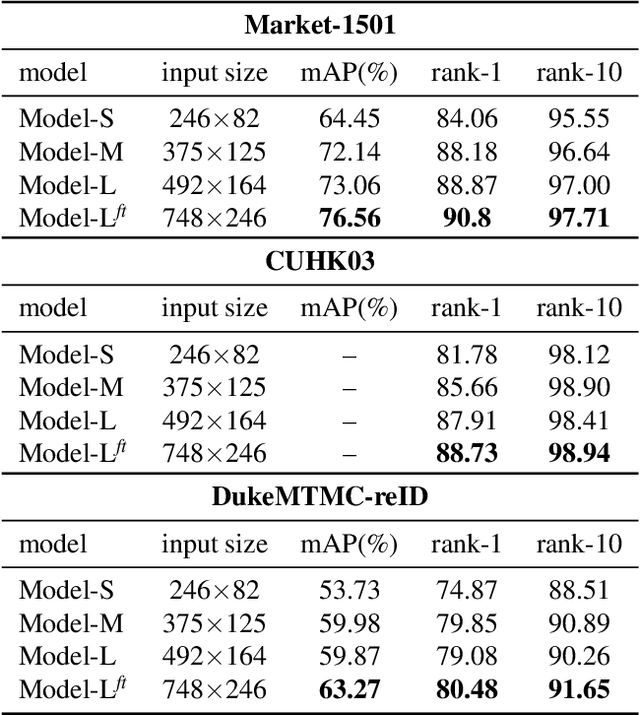
Person re-identification is a challenging task mainly due to factors such as background clutter, pose, illumination and camera point of view variations. These elements hinder the process of extracting robust and discriminative representations, hence preventing different identities from being successfully distinguished. To improve the representation learning, usually, local features from human body parts are extracted. However, the common practice for such a process has been based on bounding box part detection. In this paper, we propose to adopt human semantic parsing which, due to its pixel-level accuracy and capability of modeling arbitrary contours, is naturally a better alternative. Our proposed SPReID integrates human semantic parsing in person re-identification and not only considerably outperforms its counter baseline, but achieves state-of-the-art performance. We also show that by employing a \textit{simple} yet effective training strategy, standard popular deep convolutional architectures such as Inception-V3 and ResNet-152, with no modification, while operating solely on full image, can dramatically outperform current state-of-the-art. Our proposed methods improve state-of-the-art person re-identification on: Market-1501 by ~17% in mAP and ~6% in rank-1, CUHK03 by ~4% in rank-1 and DukeMTMC-reID by ~24% in mAP and ~10% in rank-1.