 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Structural Disparities for Face Models
Paper and Code
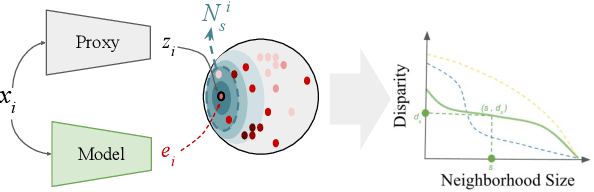
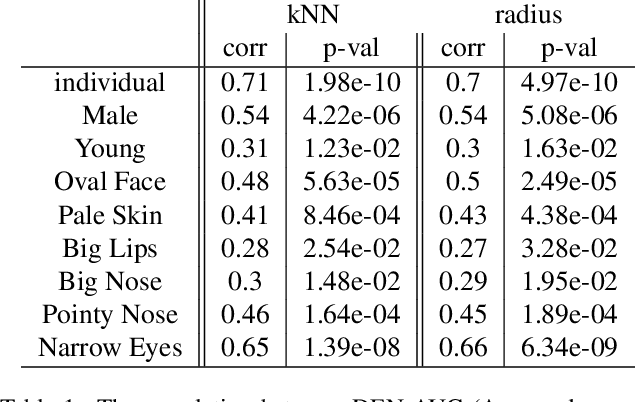


In machine learning, disparity metrics are often defined by measuring the difference in the performance or outcome of a model, across different sub-populations (groups) of datapoints. Thus, the inputs to disparity quantification consist of a model's predictions $\hat{y}$, the ground-truth labels for the predictions $y$, and group labels $g$ for the data points. Performance of the model for each group is calculated by comparing $\hat{y}$ and $y$ for the datapoints within a specific group, and as a result, disparity of performance across the different groups can be calculated. In many real world scenarios however, group labels ($g$) may not be available at scale during training and validation time, or collecting them might not be feasible or desirable as they could often be sensitive information. As a result, evaluating disparity metrics across categorical groups would not be feasible. On the other hand, in many scenarios noisy groupings may be obtainable using some form of a proxy, which would allow measuring disparity metrics across sub-populations. Here we explore performing such analysis on computer vision models trained on human faces, and on tasks such as face attribute prediction and affect estimation. Our experiments indicate that embeddings resulting from an off-the-shelf face recognition model, could meaningfully serve as a proxy for such estimation.