 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Bias-Variance Characteristics of LIME and SHAP in High Sparsity Movie Recommendation Explanation Tasks
Jun 09, 2022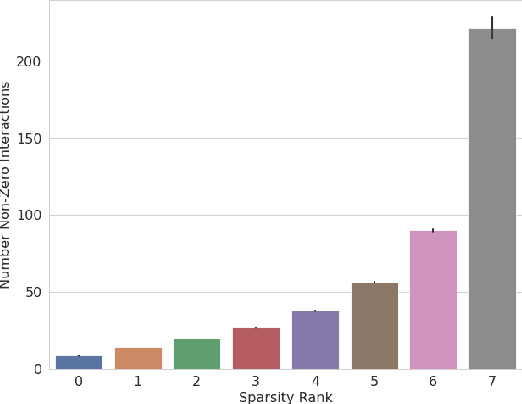
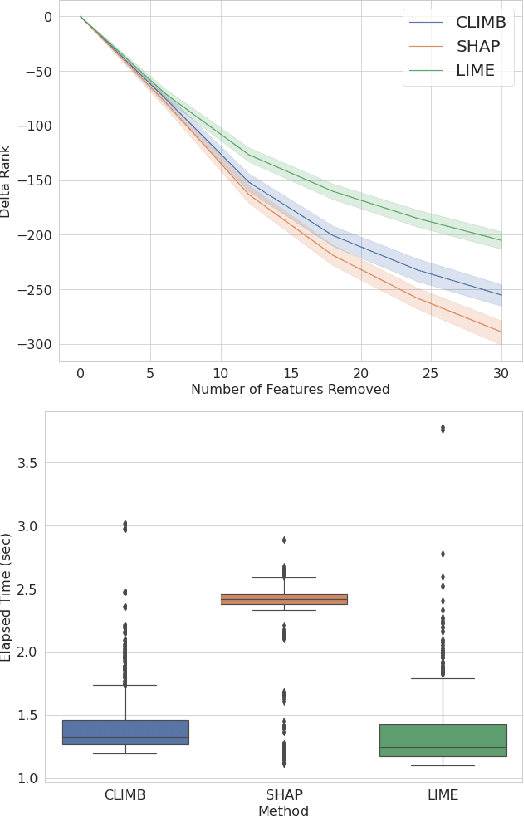
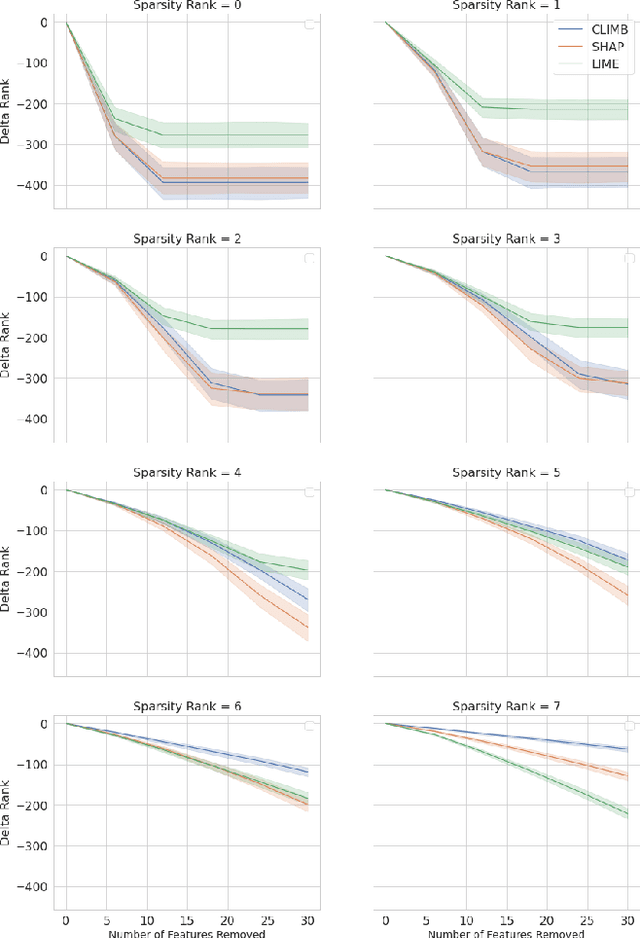
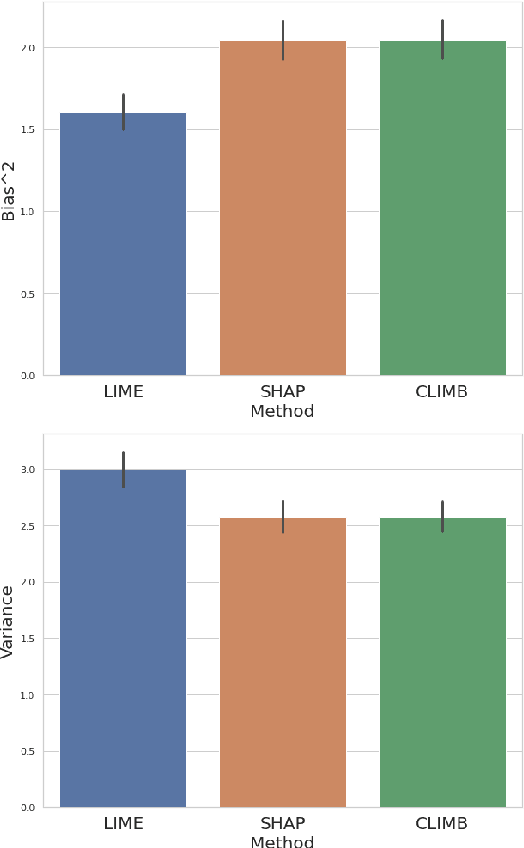
We evaluate two popular local explainability techniques, LIME and SHAP, on a movie recommendation task. We discover that the two methods behave very differently depending on the sparsity of the data set. LIME does better than SHAP in dense segments of the data set and SHAP does better in sparse segments. We trace this difference to the differing bias-variance characteristics of the underlying estimators of LIME and SHAP. We find that SHAP exhibits lower variance in sparse segments of the data compared to LIME. We attribute this lower variance to the completeness constraint property inherent in SHAP and missing in LIME. This constraint acts as a regularizer and therefore increases the bias of the SHAP estimator but decreases its variance, leading to a favorable bias-variance trade-off especially in high sparsity data settings. With this insight, we introduce the same constraint into LIME and formulate a novel local explainabilty framework called Completeness-Constrained LIME (CLIMB) that is superior to LIME and much faster than SHAP.
Learning Representations of Hierarchical Slates in Collaborative Filtering
Sep 25, 2020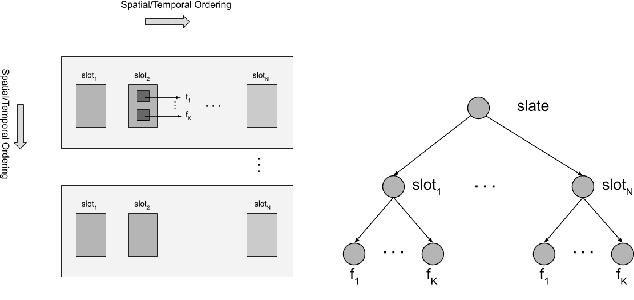
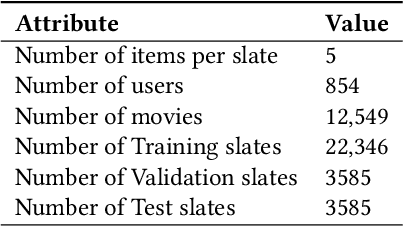

We are interested in building collaborative filtering models for recommendation systems where users interact with slates instead of individual items. These slates can be hierarchical in nature. The central idea of our approach is to learn low dimensional embeddings of these slates. We present a novel way to learn these embeddings by making use of the (unknown) statistics of the underlying distribution generating the hierarchical data. Our representation learning algorithm can be viewed as a simple composition rule that can be applied recursively in a bottom-up fashion to represent arbitrarily complex hierarchical structures in terms of the representations of its constituent components. We demonstrate our ideas on two real world recommendation systems datasets including the one used for the RecSys 2019 challenge. For that dataset, we improve upon the performance achieved by the winning team's model by incorporating embeddings as features generated by our approach in their solution.
A Nonparametric Latent Factor Model For Location-Aware Video Recommendations
Dec 05, 2016



We are interested in learning customers' video preferences from their historic viewing patterns and geographical location. We consider a Bayesian latent factor modeling approach for this task. In order to tune the complexity of the model to best represent the data, we make use of Bayesian nonparameteric techniques. We describe an inference technique that can scale to large real-world data sets. Finally we show results obtained by applying the model to a large internal Netflix data set, that illustrates that the model was able to capture interesting relationships between viewing patterns and geographical location.