 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Positive History: Re-ranking with List-level Hybrid Feedback
Paper and Code
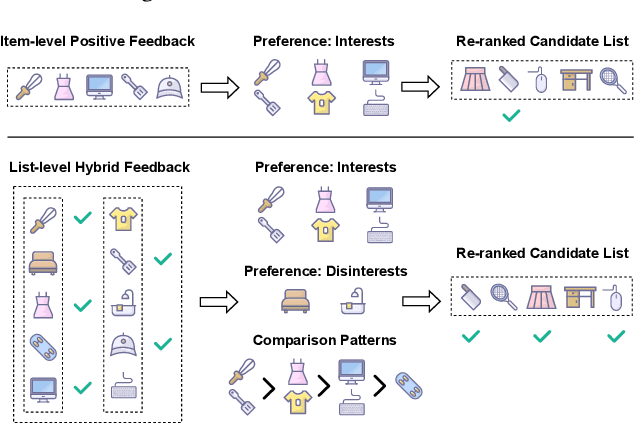
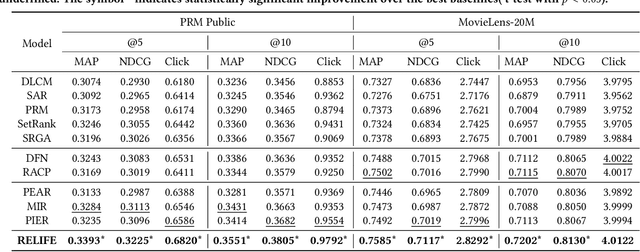
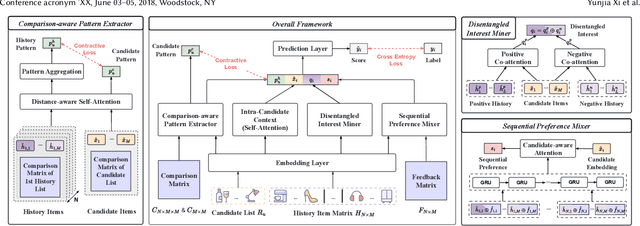
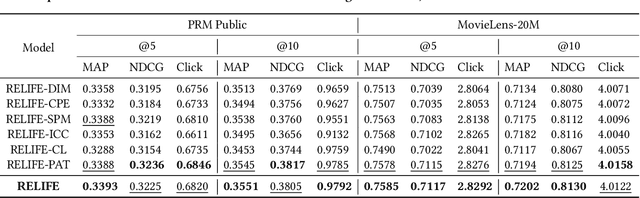
As the last stage of recommender systems, re-ranking generates a re-ordered list that aligns with the user's preference. However, previous works generally focus on item-level positive feedback as history (e.g., only clicked items) and ignore that users provide positive or negative feedback on items in the entire list. This list-level hybrid feedback can reveal users' holistic preferences and reflect users' comparison behavior patterns manifesting within a list. Such patterns could predict user behaviors on candidate lists, thus aiding better re-ranking. Despite appealing benefits, extracting and integrating preferences and behavior patterns from list-level hybrid feedback into re-ranking multiple items remains challenging. To this end, we propose Re-ranking with List-level Hybrid Feedback (dubbed RELIFE). It captures user's preferences and behavior patterns with three modules: a Disentangled Interest Miner to disentangle the user's preferences into interests and disinterests, a Sequential Preference Mixer to learn users' entangled preferences considering the context of feedback, and a Comparison-aware Pattern Extractor to capture user's behavior patterns within each list. Moreover, for better integration of patterns, contrastive learning is adopted to align the behavior patterns of candidate and historical lists. Extensive experiments show that RELIFE significantly outperforms SOTA re-ranking baselines.