 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNever mind the metrics -- what about the uncertainty? Visualising confusion matrix metric distributions
Paper and Code
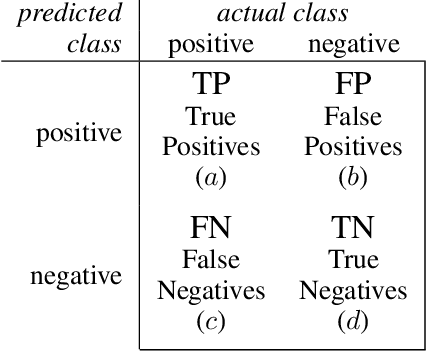
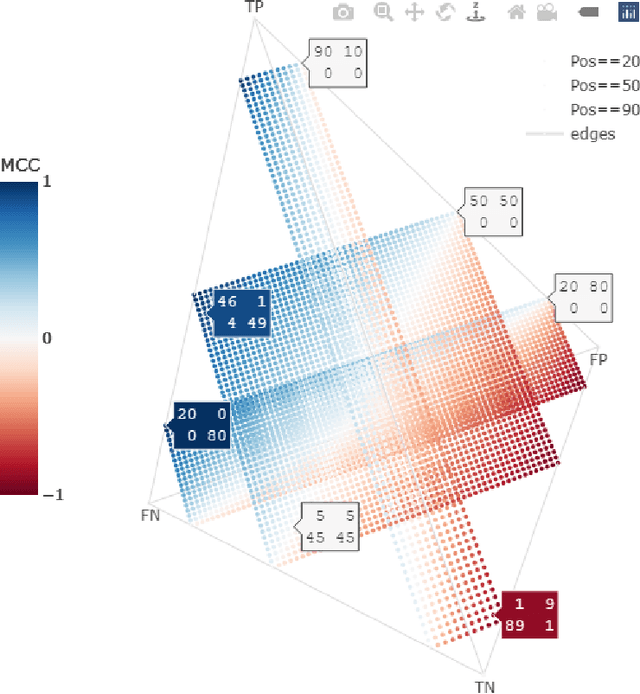
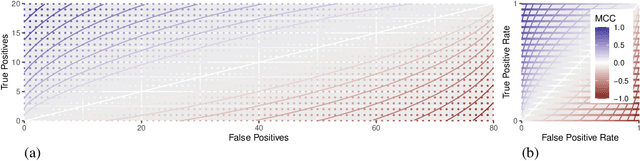
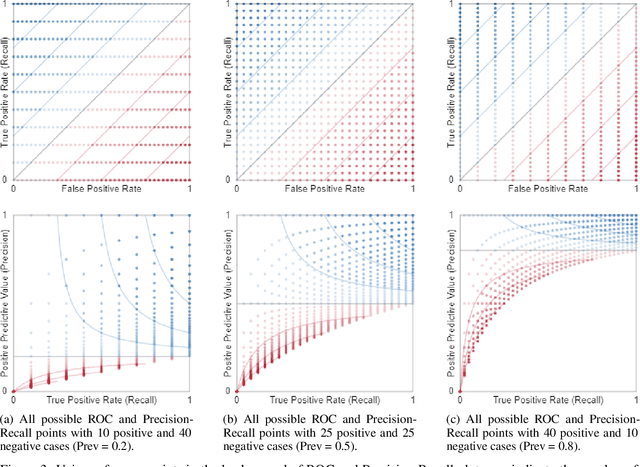
There are strong incentives to build models that demonstrate outstanding predictive performance on various datasets and benchmarks. We believe these incentives risk a narrow focus on models and on the performance metrics used to evaluate and compare them -- resulting in a growing body of literature to evaluate and compare metrics. This paper strives for a more balanced perspective on classifier performance metrics by highlighting their distributions under different models of uncertainty and showing how this uncertainty can easily eclipse differences in the empirical performance of classifiers. We begin by emphasising the fundamentally discrete nature of empirical confusion matrices and show how binary matrices can be meaningfully represented in a three dimensional compositional lattice, whose cross-sections form the basis of the space of receiver operating characteristic (ROC) curves. We develop equations, animations and interactive visualisations of the contours of performance metrics within (and beyond) this ROC space, showing how some are affected by class imbalance. We provide interactive visualisations that show the discrete posterior predictive probability mass functions of true and false positive rates in ROC space, and how these relate to uncertainty in performance metrics such as Balanced Accuracy (BA) and the Matthews Correlation Coefficient (MCC). Our hope is that these insights and visualisations will raise greater awareness of the substantial uncertainty in performance metric estimates that can arise when classifiers are evaluated on empirical datasets and benchmarks, and that classification model performance claims should be tempered by this understanding.