 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Euclidean and Hyperbolic Embeddings on the WordNet Nouns Hypernymy Graph
Sep 15, 2021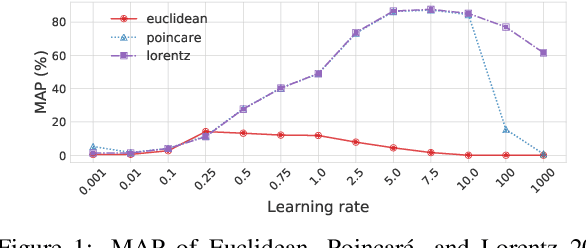
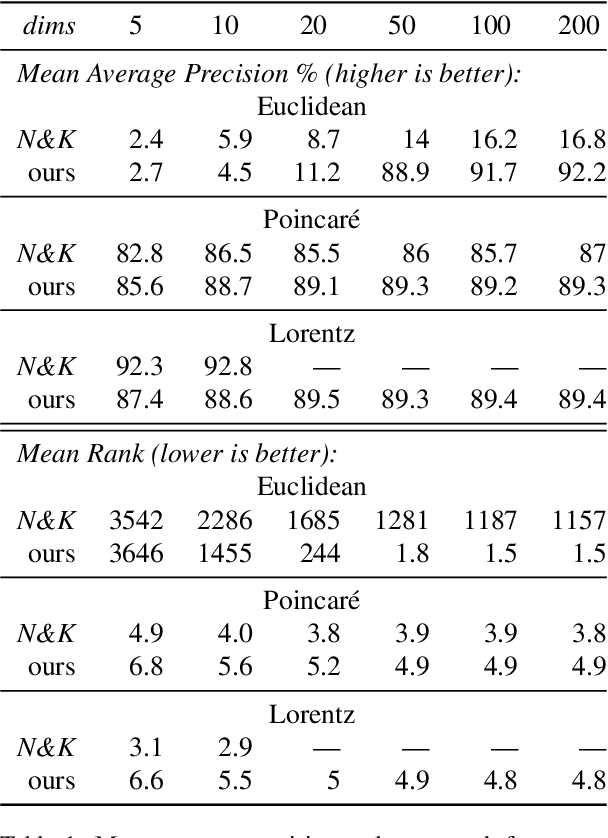

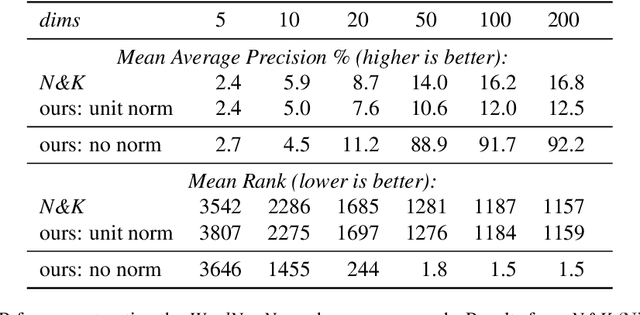
Nickel and Kiela (2017) present a new method for embedding tree nodes in the Poincare ball, and suggest that these hyperbolic embeddings are far more effective than Euclidean embeddings at embedding nodes in large, hierarchically structured graphs like the WordNet nouns hypernymy tree. This is especially true in low dimensions (Nickel and Kiela, 2017, Table 1). In this work, we seek to reproduce their experiments on embedding and reconstructing the WordNet nouns hypernymy graph. Counter to what they report, we find that Euclidean embeddings are able to represent this tree at least as well as Poincare embeddings, when allowed at least 50 dimensions. We note that this does not diminish the significance of their work given the impressive performance of hyperbolic embeddings in very low-dimensional settings. However, given the wide influence of their work, our aim here is to present an updated and more accurate comparison between the Euclidean and hyperbolic embeddings.
Analyzing ASR pretraining for low-resource speech-to-text translation
Oct 23, 2019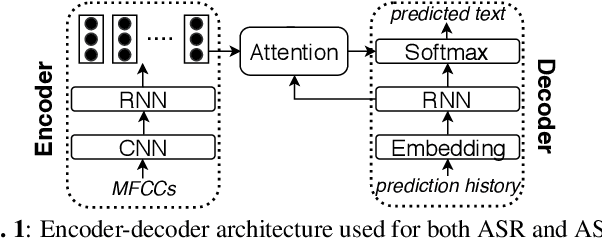
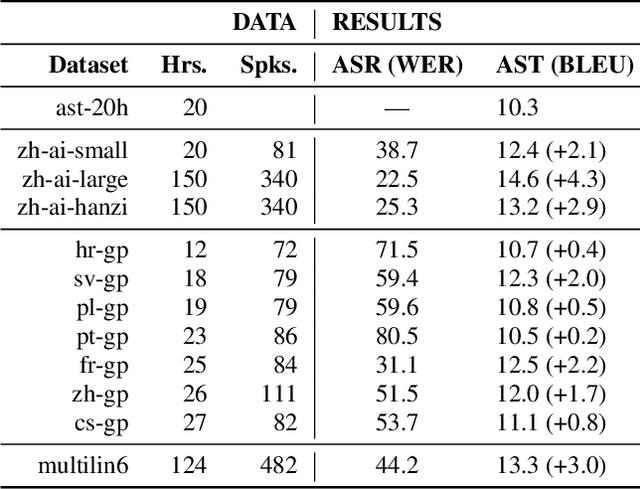
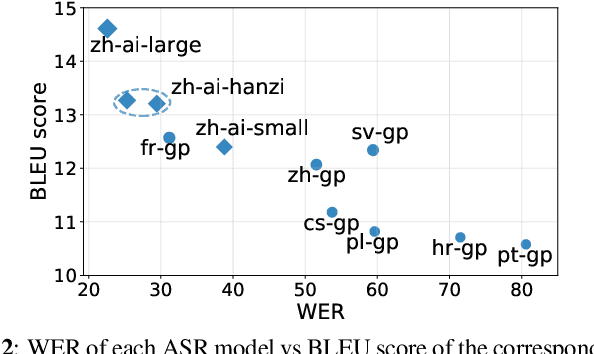
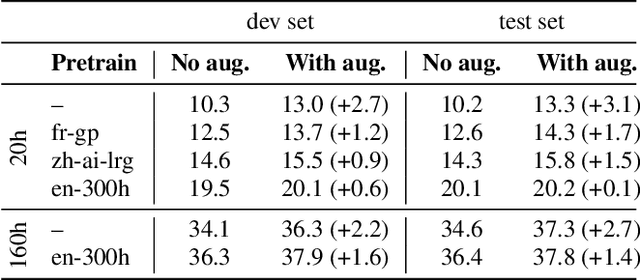
Previous work has shown that for low-resource source languages, automatic speech-to-text translation (AST) can be improved by pretraining an end-to-end model on automatic speech recognition (ASR) data from a high-resource language. However, it is not clear what factors --e.g., language relatedness or size of the pretraining data-- yield the biggest improvements, or whether pretraining can be effectively combined with other methods such as data augmentation. Here, we experiment with pretraining on datasets of varying sizes, including languages related and unrelated to the AST source language. We find that the best predictor of final AST performance is the word error rate of the pretrained ASR model, and that differences in ASR/AST performance correlate with how phonetic information is encoded in the later RNN layers of our model. We also show that pretraining and data augmentation yield complementary benefits for AST.
Classifying topics in speech when all you have is crummy translations
Aug 29, 2019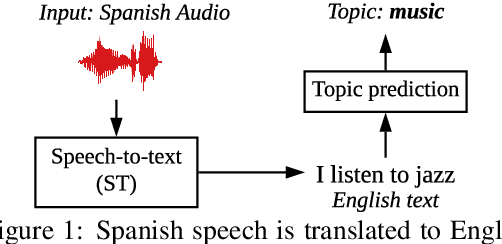


Given a large amount of unannotated speech in a language with few resources, can we classify the speech utterances by topic? We show that this is possible if text translations are available for just a small amount of speech (less than 20 hours), using a recent model for direct speech-to-text translation. While the translations are poor, they are still good enough to correctly classify 1-minute speech segments over 70% of the time - a 20% improvement over a majority-class baseline. Such a system might be useful for humanitarian applications like crisis response, where incoming speech must be quickly assessed for further action.
Pre-training on high-resource speech recognition improves low-resource speech-to-text translation
Sep 05, 2018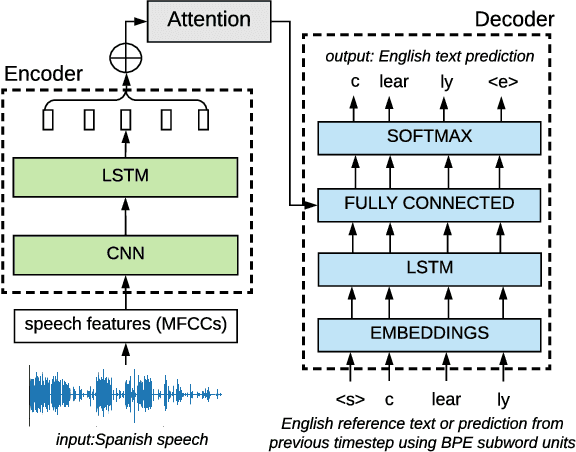

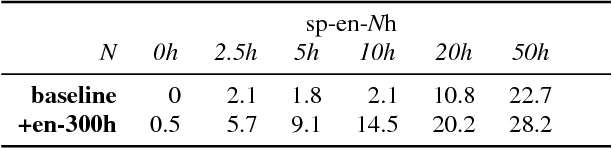
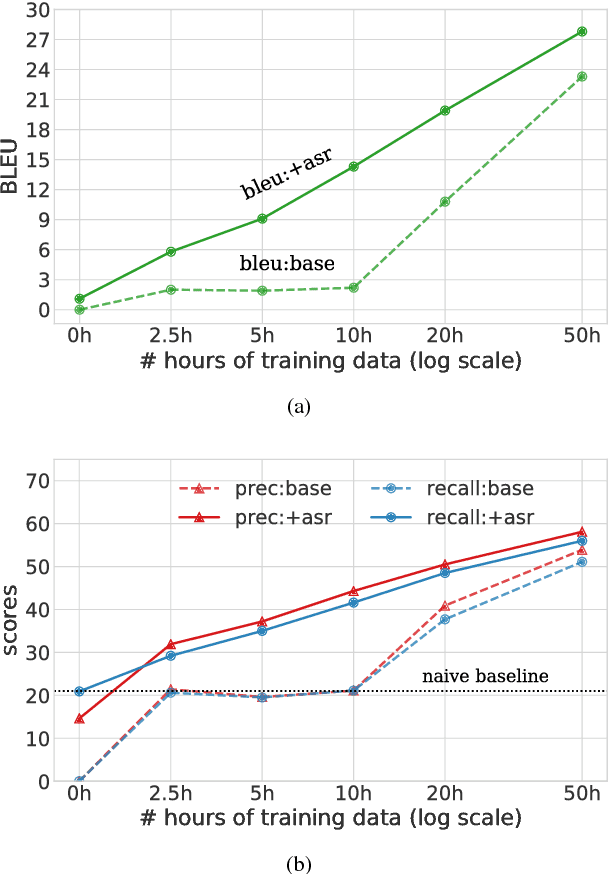
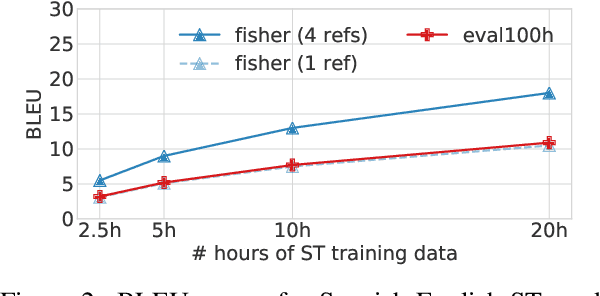
We present a simple approach to improve direct speech-to-text translation (ST) when the source language is low-resource: we pre-train the model on a high-resource automatic speech recognition (ASR) task, and then fine-tune its parameters for ST. We demonstrate that our approach is effective by pre-training on 300 hours of English ASR data to improve Spanish-English ST from 10.8 to 20.2 BLEU when only 20 hours of Spanish-English ST training data is available. Through an ablation study, we find that the pre-trained encoder (acoustic model) accounts for most of the improvement, which is surprising since the shared language in these tasks is the target language (text), and not the source language (audio). Applying this insight, we show that pre-training on ASR helps ST even when the ASR language differs from both source and target ST languages: pre-training on French ASR also improves Spanish-English ST. Finally, we show that the approach improves a true low-resource task: pre-training on a combination of English ASR and French ASR improves Mboshi-French ST, where only 4 hours of data are available, from 3.5 to 7.1 BLEU.
Low-Resource Speech-to-Text Translation
Jun 18, 2018
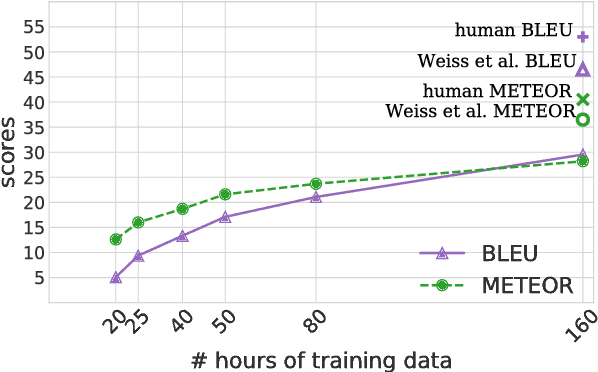
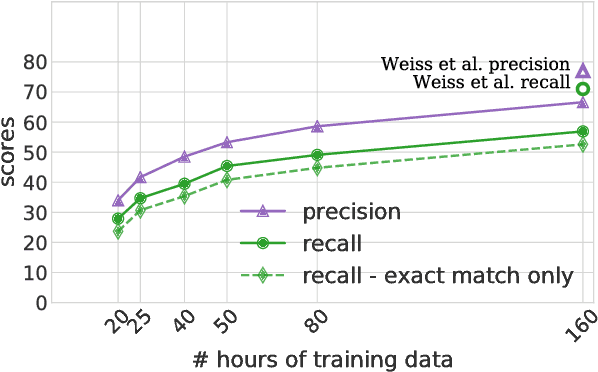

Speech-to-text translation has many potential applications for low-resource languages, but the typical approach of cascading speech recognition with machine translation is often impossible, since the transcripts needed to train a speech recognizer are usually not available for low-resource languages. Recent work has found that neural encoder-decoder models can learn to directly translate foreign speech in high-resource scenarios, without the need for intermediate transcription. We investigate whether this approach also works in settings where both data and computation are limited. To make the approach efficient, we make several architectural changes, including a change from character-level to word-level decoding. We find that this choice yields crucial speed improvements that allow us to train with fewer computational resources, yet still performs well on frequent words. We explore models trained on between 20 and 160 hours of data, and find that although models trained on less data have considerably lower BLEU scores, they can still predict words with relatively high precision and recall---around 50% for a model trained on 50 hours of data, versus around 60% for the full 160 hour model. Thus, they may still be useful for some low-resource scenarios.
Towards speech-to-text translation without speech recognition
Feb 13, 2017
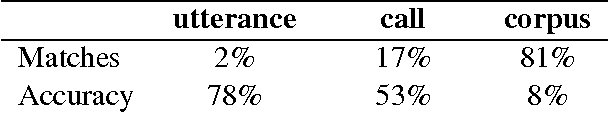

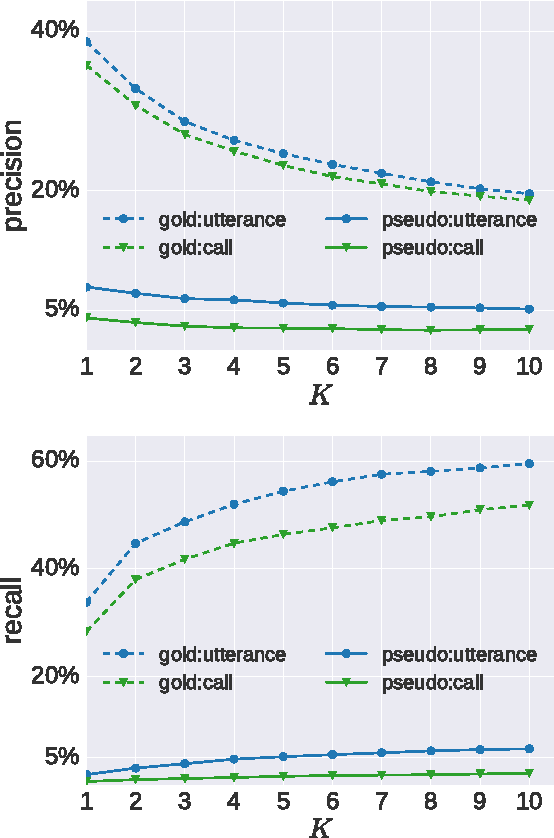
We explore the problem of translating speech to text in low-resource scenarios where neither automatic speech recognition (ASR) nor machine translation (MT) are available, but we have training data in the form of audio paired with text translations. We present the first system for this problem applied to a realistic multi-speaker dataset, the CALLHOME Spanish-English speech translation corpus. Our approach uses unsupervised term discovery (UTD) to cluster repeated patterns in the audio, creating a pseudotext, which we pair with translations to create a parallel text and train a simple bag-of-words MT model. We identify the challenges faced by the system, finding that the difficulty of cross-speaker UTD results in low recall, but that our system is still able to correctly translate some content words in test data.
Weakly supervised spoken term discovery using cross-lingual side information
Sep 21, 2016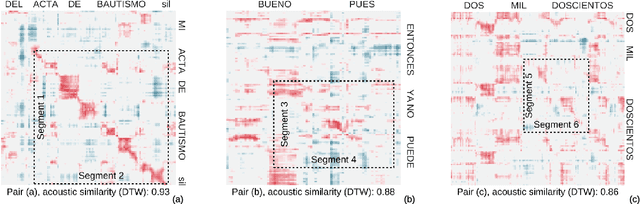


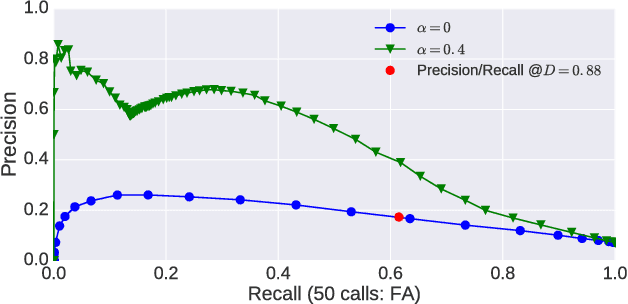
Recent work on unsupervised term discovery (UTD) aims to identify and cluster repeated word-like units from audio alone. These systems are promising for some very low-resource languages where transcribed audio is unavailable, or where no written form of the language exists. However, in some cases it may still be feasible (e.g., through crowdsourcing) to obtain (possibly noisy) text translations of the audio. If so, this information could be used as a source of side information to improve UTD. Here, we present a simple method for rescoring the output of a UTD system using text translations, and test it on a corpus of Spanish audio with English translations. We show that it greatly improves the average precision of the results over a wide range of system configurations and data preprocessing methods.