 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly supervised spoken term discovery using cross-lingual side information
Paper and Code
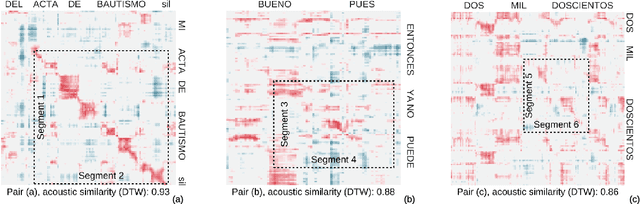


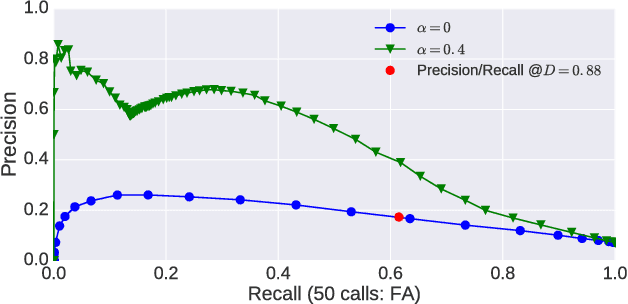
Recent work on unsupervised term discovery (UTD) aims to identify and cluster repeated word-like units from audio alone. These systems are promising for some very low-resource languages where transcribed audio is unavailable, or where no written form of the language exists. However, in some cases it may still be feasible (e.g., through crowdsourcing) to obtain (possibly noisy) text translations of the audio. If so, this information could be used as a source of side information to improve UTD. Here, we present a simple method for rescoring the output of a UTD system using text translations, and test it on a corpus of Spanish audio with English translations. We show that it greatly improves the average precision of the results over a wide range of system configurations and data preprocessing methods.