Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying topics in speech when all you have is crummy translations
Paper and Code
Aug 29, 2019

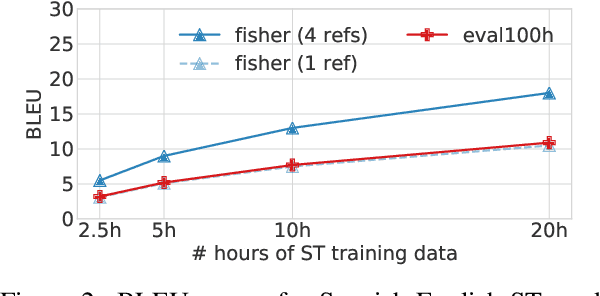

Given a large amount of unannotated speech in a language with few resources, can we classify the speech utterances by topic? We show that this is possible if text translations are available for just a small amount of speech (less than 20 hours), using a recent model for direct speech-to-text translation. While the translations are poor, they are still good enough to correctly classify 1-minute speech segments over 70% of the time - a 20% improvement over a majority-class baseline. Such a system might be useful for humanitarian applications like crisis response, where incoming speech must be quickly assessed for further action.
View paper on