 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan I Have Your Order? Monte-Carlo Tree Search for Slot Filling Ordering in Diffusion Language Models
Feb 13, 2026While plan-and-infill decoding in Masked Diffusion Models (MDMs) shows promise for mathematical and code reasoning, performance remains highly sensitive to slot infilling order, often yielding substantial output variance. We introduce McDiffuSE, a framework that formulates slot selection as decision making and optimises infilling orders through Monte Carlo Tree Search (MCTS). McDiffuSE uses look-ahead simulations to evaluate partial completions before commitment, systematically exploring the combinatorial space of generation orders. Experiments show an average improvement of 3.2% over autoregressive baselines and 8.0% over baseline plan-and-infill, with notable gains of 19.5% on MBPP and 4.9% on MATH500. Our analysis reveals that while McDiffuSE predominantly follows sequential ordering, incorporating non-sequential generation is essential for maximising performance. We observe that larger exploration constants, rather than increased simulations, are necessary to overcome model confidence biases and discover effective orderings. These findings establish MCTS-based planning as an effective approach for enhancing generation quality in MDMs.
A Survey on Tabular Data Generation: Utility, Alignment, Fidelity, Privacy, and Beyond
Mar 07, 2025Generative modelling has become the standard approach for synthesising tabular data. However, different use cases demand synthetic data to comply with different requirements to be useful in practice. In this survey, we review deep generative modelling approaches for tabular data from the perspective of four types of requirements: utility of the synthetic data, alignment of the synthetic data with domain-specific knowledge, statistical fidelity of the synthetic data distribution compared to the real data distribution, and privacy-preserving capabilities. We group the approaches along two levels of granularity: (i) based on the primary type of requirements they address and (ii) according to the underlying model they utilise. Additionally, we summarise the appropriate evaluation methods for each requirement and the specific characteristics of each model type. Finally, we discuss future directions for the field, along with opportunities to improve the current evaluation methods. Overall, this survey can be seen as a user guide to tabular data generation: helping readers navigate available models and evaluation methods to find those best suited to their needs.
Beyond the convexity assumption: Realistic tabular data generation under quantifier-free real linear constraints
Feb 25, 2025Synthetic tabular data generation has traditionally been a challenging problem due to the high complexity of the underlying distributions that characterise this type of data. Despite recent advances in deep generative models (DGMs), existing methods often fail to produce realistic datapoints that are well-aligned with available background knowledge. In this paper, we address this limitation by introducing Disjunctive Refinement Layer (DRL), a novel layer designed to enforce the alignment of generated data with the background knowledge specified in user-defined constraints. DRL is the first method able to automatically make deep learning models inherently compliant with constraints as expressive as quantifier-free linear formulas, which can define non-convex and even disconnected spaces. Our experimental analysis shows that DRL not only guarantees constraint satisfaction but also improves efficacy in downstream tasks. Notably, when applied to DGMs that frequently violate constraints, DRL eliminates violations entirely. Further, it improves performance metrics by up to 21.4% in F1-score and 20.9% in Area Under the ROC Curve, thus demonstrating its practical impact on data generation.
PiShield: A NeSy Framework for Learning with Requirements
Feb 28, 2024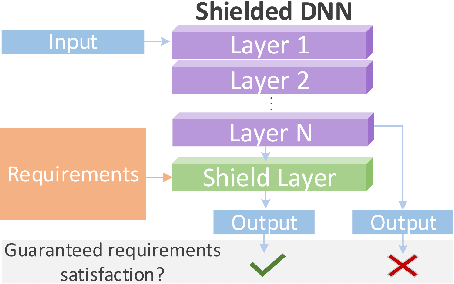
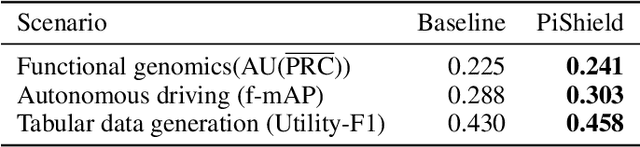

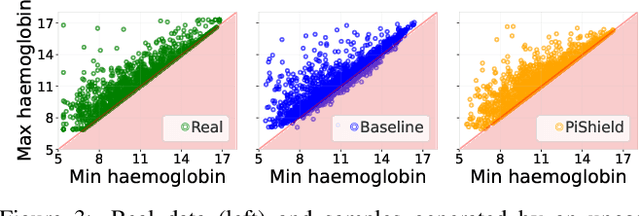
Deep learning models have shown their strengths in various application domains, however, they often struggle to meet safety requirements for their outputs. In this paper, we introduce PiShield, the first framework ever allowing for the integration of the requirements into the neural networks' topology. PiShield guarantees compliance with these requirements, regardless of input. Additionally, it allows for integrating requirements both at inference and/or training time, depending on the practitioners' needs. Given the widespread application of deep learning, there is a growing need for frameworks allowing for the integration of the requirements across various domains. Here, we explore three application scenarios: functional genomics, autonomous driving, and tabular data generation.
Exploiting T-norms for Deep Learning in Autonomous Driving
Feb 17, 2024



Deep learning has been at the core of the autonomous driving field development, due to the neural networks' success in finding patterns in raw data and turning them into accurate predictions. Moreover, recent neuro-symbolic works have shown that incorporating the available background knowledge about the problem at hand in the loss function via t-norms can further improve the deep learning models' performance. However, t-norm-based losses may have very high memory requirements and, thus, they may be impossible to apply in complex application domains like autonomous driving. In this paper, we show how it is possible to define memory-efficient t-norm-based losses, allowing for exploiting t-norms for the task of event detection in autonomous driving. We conduct an extensive experimental analysis on the ROAD-R dataset and show (i) that our proposal can be implemented and run on GPUs with less than 25 GiB of available memory, while standard t-norm-based losses are estimated to require more than 100 GiB, far exceeding the amount of memory normally available, (ii) that t-norm-based losses improve performance, especially when limited labelled data are available, and (iii) that t-norm-based losses can further improve performance when exploited on both labelled and unlabelled data.
How Realistic Is Your Synthetic Data? Constraining Deep Generative Models for Tabular Data
Feb 07, 2024



Deep Generative Models (DGMs) have been shown to be powerful tools for generating tabular data, as they have been increasingly able to capture the complex distributions that characterize them. However, to generate realistic synthetic data, it is often not enough to have a good approximation of their distribution, as it also requires compliance with constraints that encode essential background knowledge on the problem at hand. In this paper, we address this limitation and show how DGMs for tabular data can be transformed into Constrained Deep Generative Models (C-DGMs), whose generated samples are guaranteed to be compliant with the given constraints. This is achieved by automatically parsing the constraints and transforming them into a Constraint Layer (CL) seamlessly integrated with the DGM. Our extensive experimental analysis with various DGMs and tasks reveals that standard DGMs often violate constraints, some exceeding $95\%$ non-compliance, while their corresponding C-DGMs are never non-compliant. Then, we quantitatively demonstrate that, at training time, C-DGMs are able to exploit the background knowledge expressed by the constraints to outperform their standard counterparts with up to $6.5\%$ improvement in utility and detection. Further, we show how our CL does not necessarily need to be integrated at training time, as it can be also used as a guardrail at inference time, still producing some improvements in the overall performance of the models. Finally, we show that our CL does not hinder the sample generation time of the models.
ROAD-R: The Autonomous Driving Dataset with Logical Requirements
Oct 05, 2022



Neural networks have proven to be very powerful at computer vision tasks. However, they often exhibit unexpected behaviours, violating known requirements expressing background knowledge. This calls for models (i) able to learn from the requirements, and (ii) guaranteed to be compliant with the requirements themselves. Unfortunately, the development of such models is hampered by the lack of datasets equipped with formally specified requirements. In this paper, we introduce the ROad event Awareness Dataset with logical Requirements (ROAD-R), the first publicly available dataset for autonomous driving with requirements expressed as logical constraints. Given ROAD-R, we show that current state-of-the-art models often violate its logical constraints, and that it is possible to exploit them to create models that (i) have a better performance, and (ii) are guaranteed to be compliant with the requirements themselves.
Recurrently Estimating Reflective Symmetry Planes from Partial Pointclouds
Jun 30, 2021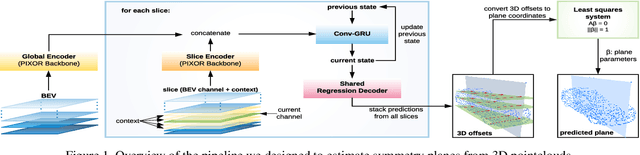



Many man-made objects are characterised by a shape that is symmetric along one or more planar directions. Estimating the location and orientation of such symmetry planes can aid many tasks such as estimating the overall orientation of an object of interest or performing shape completion, where a partial scan of an object is reflected across the estimated symmetry plane in order to obtain a more detailed shape. Many methods processing 3D data rely on expensive 3D convolutions. In this paper we present an alternative novel encoding that instead slices the data along the height dimension and passes it sequentially to a 2D convolutional recurrent regression scheme. The method also comprises a differentiable least squares step, allowing for end-to-end accurate and fast processing of both full and partial scans of symmetric objects. We use this approach to efficiently handle 3D inputs to design a method to estimate planar reflective symmetries. We show that our approach has an accuracy comparable to state-of-the-art techniques on the task of planar reflective symmetry estimation on full synthetic objects. Additionally, we show that it can be deployed on partial scans of objects in a real-world pipeline to improve the outputs of a 3D object detector.