 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeR: Issue Resolving with Multi-Agent and Task Graphs
Jun 03, 2024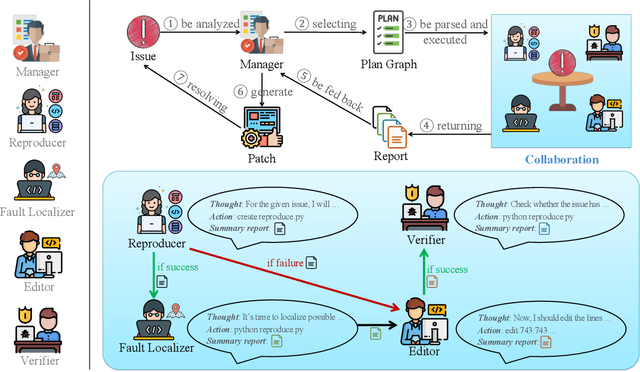
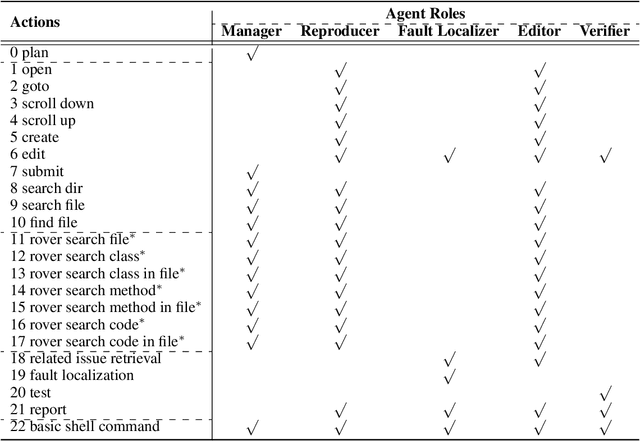

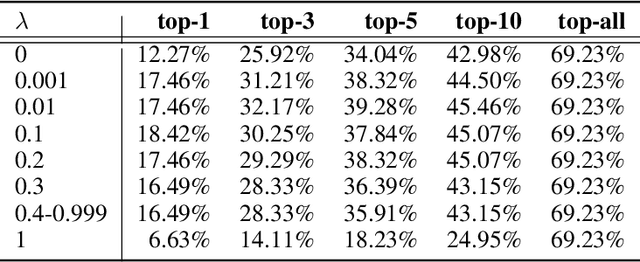
GitHub issue resolving recently has attracted significant attention from academia and industry. SWE-bench is proposed to measure the performance in resolving issues. In this paper, we propose CodeR, which adopts a multi-agent framework and pre-defined task graphs to Repair & Resolve reported bugs and add new features within code Repository. On SWE-bench lite, CodeR is able to solve 28.00% of issues, in the case of submitting only once for each issue. We examine the performance impact of each design of CodeR and offer insights to advance this research direction.
Evaluating and Mitigating Linguistic Discrimination in Large Language Models
Apr 29, 2024By training on text in various languages, large language models (LLMs) typically possess multilingual support and demonstrate remarkable capabilities in solving tasks described in different languages. However, LLMs can exhibit linguistic discrimination due to the uneven distribution of training data across languages. That is, LLMs are hard to keep the consistency of responses when faced with the same task but depicted in different languages. In this study, we first explore the consistency in the LLMs' outputs responding to queries in various languages from two aspects: safety and quality. We conduct this analysis with two datasets (AdvBench and NQ) based on four LLMs (Llama2-13b, Gemma-7b, GPT-3.5-turbo and Gemini-pro). The results show that LLMs exhibit stronger human alignment capabilities with queries in English, French, Russian, and Spanish (only 1.04\% of harmful queries successfully jailbreak on average) compared to queries in Bengali, Georgian, Nepali and Maithili (27.7\% of harmful queries jailbreak successfully on average). Moreover, for queries in English, Danish, Czech and Slovenian, LLMs tend to produce responses with a higher quality (with 0.1494 $F_1$ score on average) compared to the other languages. Upon these findings, we propose LDFighter, a similarity-based voting, to mitigate the linguistic discrimination in LLMs. LDFighter ensures consistent service for different language speakers. We evaluate LDFighter with both benign queries and harmful queries. The results show that LDFighter not only significantly reduces the jailbreak success rate but also improve the response quality on average, demonstrating its effectiveness.
Repairing Adversarial Texts through Perturbation
Dec 29, 2021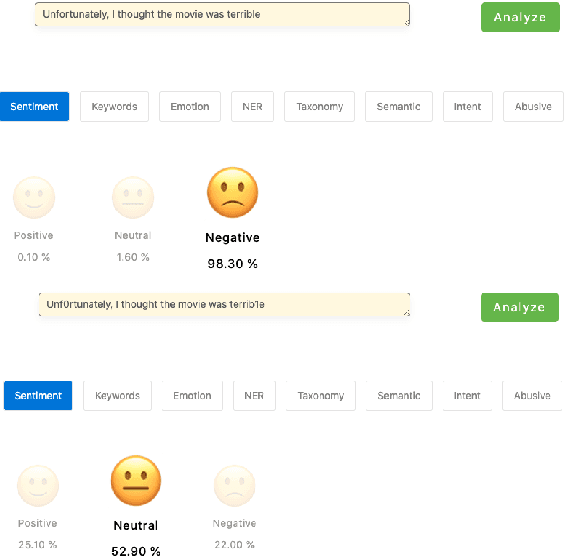
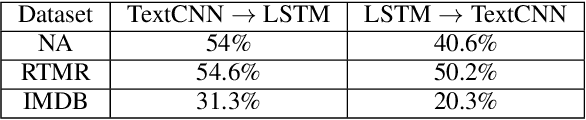
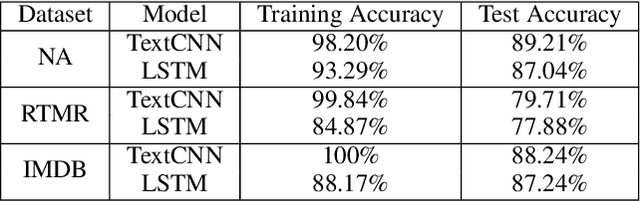
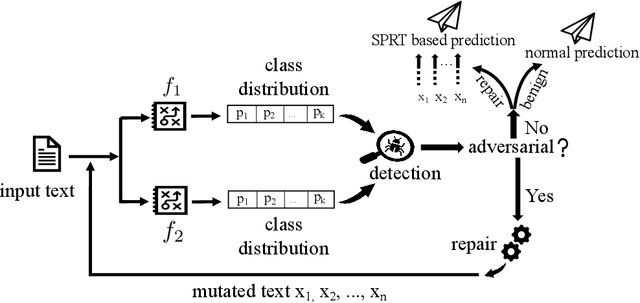
It is known that neural networks are subject to attacks through adversarial perturbations, i.e., inputs which are maliciously crafted through perturbations to induce wrong predictions. Furthermore, such attacks are impossible to eliminate, i.e., the adversarial perturbation is still possible after applying mitigation methods such as adversarial training. Multiple approaches have been developed to detect and reject such adversarial inputs, mostly in the image domain. Rejecting suspicious inputs however may not be always feasible or ideal. First, normal inputs may be rejected due to false alarms generated by the detection algorithm. Second, denial-of-service attacks may be conducted by feeding such systems with adversarial inputs. To address the gap, in this work, we propose an approach to automatically repair adversarial texts at runtime. Given a text which is suspected to be adversarial, we novelly apply multiple adversarial perturbation methods in a positive way to identify a repair, i.e., a slightly mutated but semantically equivalent text that the neural network correctly classifies. Our approach has been experimented with multiple models trained for natural language processing tasks and the results show that our approach is effective, i.e., it successfully repairs about 80\% of the adversarial texts. Furthermore, depending on the applied perturbation method, an adversarial text could be repaired in as short as one second on average.
Automatic Fairness Testing of Neural Classifiers through Adversarial Sampling
Jul 29, 2021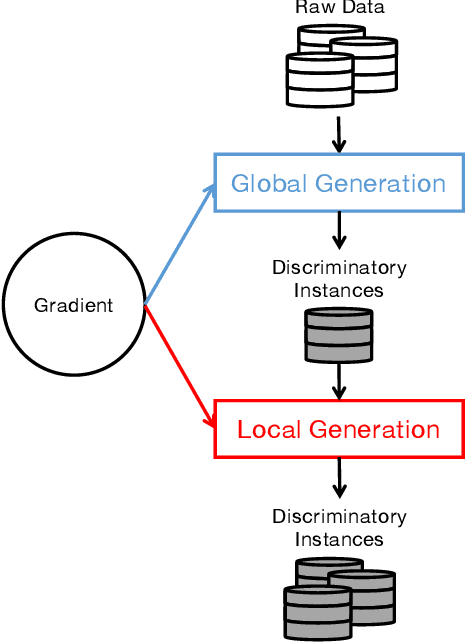

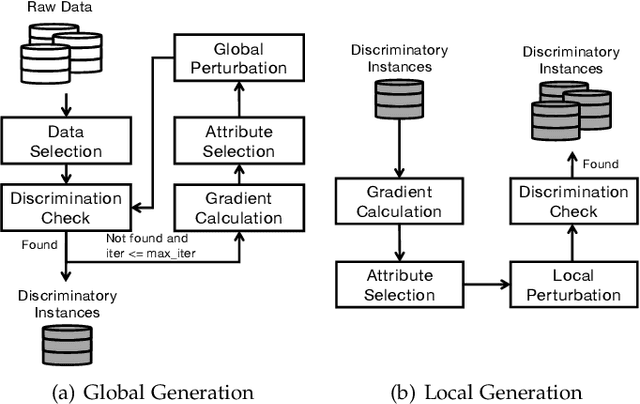
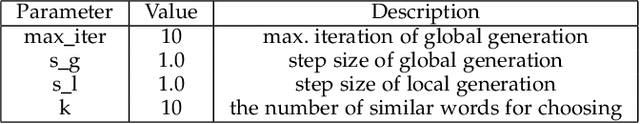
Although deep learning has demonstrated astonishing performance in many applications, there are still concerns about its dependability. One desirable property of deep learning applications with societal impact is fairness (i.e., non-discrimination). Unfortunately, discrimination might be intrinsically embedded into the models due to the discrimination in the training data. As a countermeasure, fairness testing systemically identifies discriminatory samples, which can be used to retrain the model and improve the model's fairness. Existing fairness testing approaches however have two major limitations. Firstly, they only work well on traditional machine learning models and have poor performance (e.g., effectiveness and efficiency) on deep learning models. Secondly, they only work on simple structured (e.g., tabular) data and are not applicable for domains such as text. In this work, we bridge the gap by proposing a scalable and effective approach for systematically searching for discriminatory samples while extending existing fairness testing approaches to address a more challenging domain, i.e., text classification. Compared with state-of-the-art methods, our approach only employs lightweight procedures like gradient computation and clustering, which is significantly more scalable and effective. Experimental results show that on average, our approach explores the search space much more effectively (9.62 and 2.38 times more than the state-of-the-art methods respectively on tabular and text datasets) and generates much more discriminatory samples (24.95 and 2.68 times) within a same reasonable time. Moreover, the retrained models reduce discrimination by 57.2% and 60.2% respectively on average.
Towards Repairing Neural Networks Correctly
Dec 03, 2020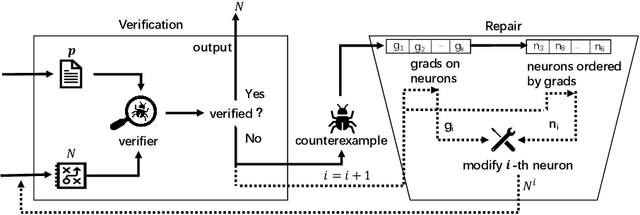
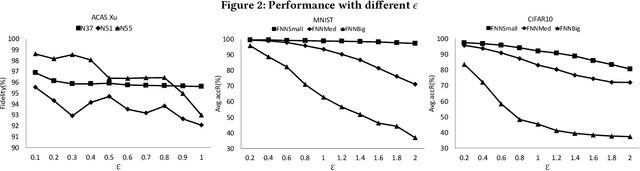
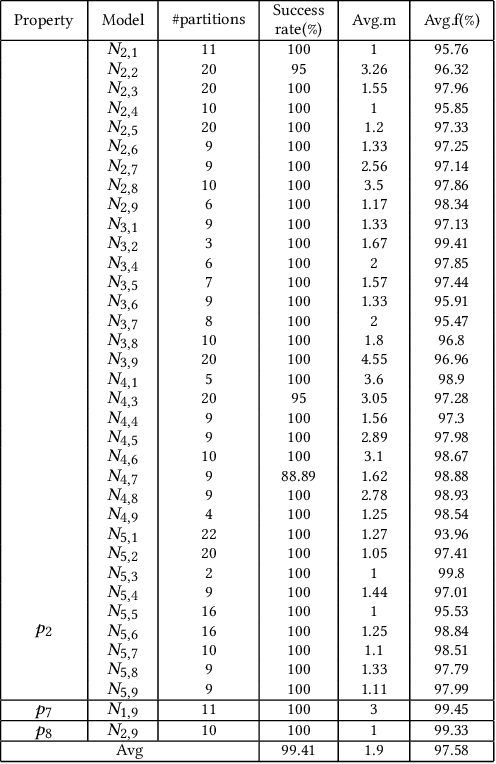
Neural networks are increasingly applied to support decision making in safety-critical applications (like autonomous cars, unmanned aerial vehicles and face recognition based authentication). While many impressive static verification techniques have been proposed to tackle the correctness problem of neural networks, it is possible that static verification may never be sufficiently scalable to handle real-world neural networks. In this work, we propose a runtime verification method to ensure the correctness of neural networks. Given a neural network and a desirable safety property, we adopt state-of-the-art static verification techniques to identify strategically locations to introduce additional gates which "correct" neural network behaviors at runtime. Experiment results show that our approach effectively generates neural networks which are guaranteed to satisfy the properties, whilst being consistent with the original neural network most of the time.
Analyzing Recurrent Neural Network by Probabilistic Abstraction
Sep 22, 2019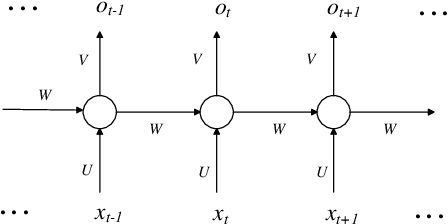

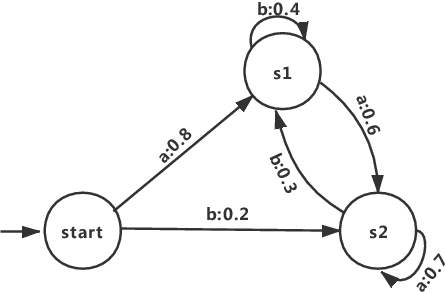
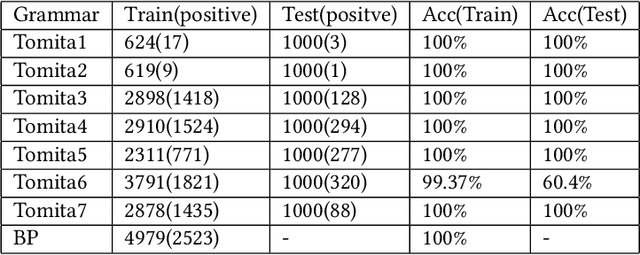
Neural network is becoming the dominant approach for solving many real-world problems like computer vision and natural language processing due to its exceptional performance as an end-to-end solution. However, deep learning models are complex and work in a black-box manner in general. This hinders humans from understanding how such systems make decisions or analyzing them using traditional software analysis techniques like testing and verification. To solve this problem and bridge the gap, several recent approaches have proposed to extract simple models in the form of finite-state automata or weighted automata for human understanding and reasoning. The results are however not encouraging due to multiple reasons like low accuracy and scalability issue. In this work, we propose to extract models in the form of probabilistic automata from recurrent neural network models instead. Our work distinguishes itself from existing approaches in two important ways. One is that we extract probabilistic models to compensate for the limited expressiveness of simple models (compared to that of deep neural networks). This is inspired by the observation that human reasoning is often `probabilistic'. The other is that we identify the right level of abstraction based on hierarchical clustering so that the models are extracted in a task-specific way. We conducted experiments on several real-world datasets using state-of-the-art RNN architectures including GRU and LSTM. The result shows that our approach improves existing model extraction approaches significantly and can produce simple models which accurately mimic the original models.
Adversarial Sample Detection for Deep Neural Network through Model Mutation Testing
Jan 18, 2019
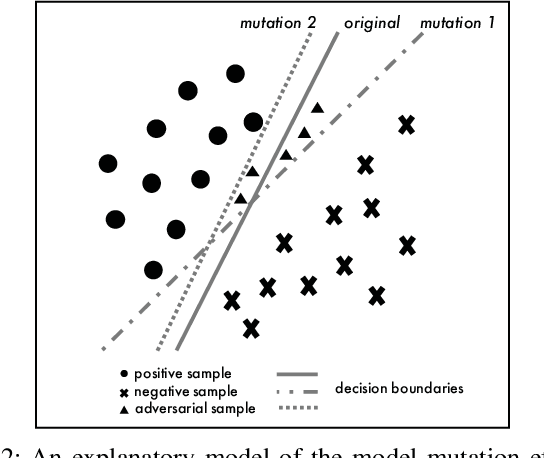
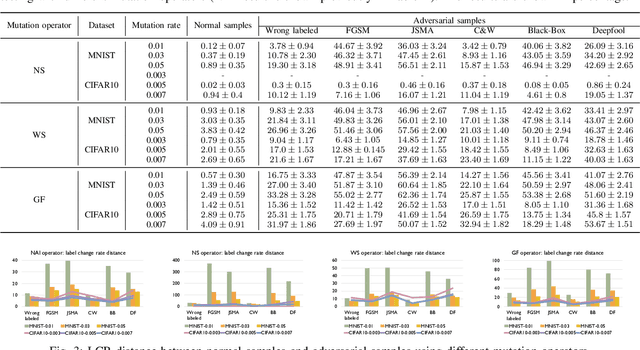
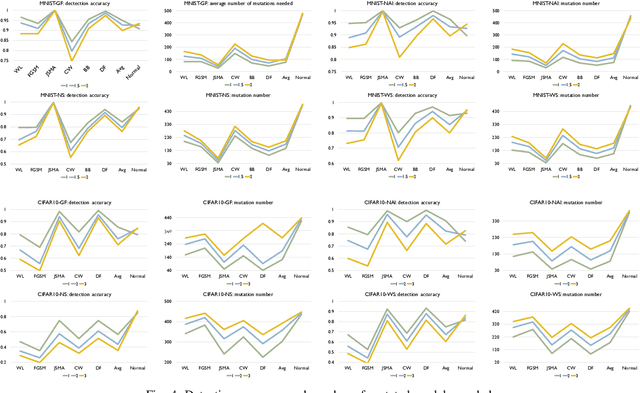
Deep neural networks (DNN) have been shown to be useful in a wide range of applications. However, they are also known to be vulnerable to adversarial samples. By transforming a normal sample with some carefully crafted human imperceptible perturbations, even highly accurate DNN make wrong decisions. Multiple defense mechanisms have been proposed which aim to hinder the generation of such adversarial samples. However, a recent work show that most of them are ineffective. In this work, we propose an alternative approach to detect adversarial samples at runtime. Our main observation is that adversarial samples are much more sensitive than normal samples if we impose random mutations on the DNN. We thus first propose a measure of `sensitivity' and show empirically that normal samples and adversarial samples have distinguishable sensitivity. We then integrate statistical hypothesis testing and model mutation testing to check whether an input sample is likely to be normal or adversarial at runtime by measuring its sensitivity. We evaluated our approach on the MNIST and CIFAR10 datasets. The results show that our approach detects adversarial samples generated by state-of-the-art attacking methods efficiently and accurately.