 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Potential of Conversational Test Suite Based Program Repair on SWE-bench
Oct 06, 2024Automatic program repair at project level may open yet to be seen opportunities in various fields of human activity. Since the SWE-Bench challenge was presented, we have seen numerous of solutions. Patch generation is a part of program repair, and test suite-based conversational patch generation has proven its effectiveness. However, the potential of conversational patch generation has not yet specifically estimated on SWE-Bench. This study reports experimental results aimed at evaluating the individual effectiveness of conversational patch generation on problems from SWE-Bench. The experiments show that a simple conversational pipeline based on LLaMA 3.1 70B can generate valid patches in 47\% of cases, which is comparable to the state-of-the-art in program repair on SWE-Bench.
CodeR: Issue Resolving with Multi-Agent and Task Graphs
Jun 03, 2024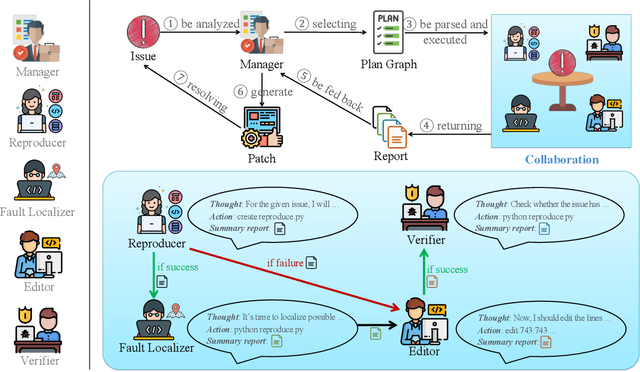
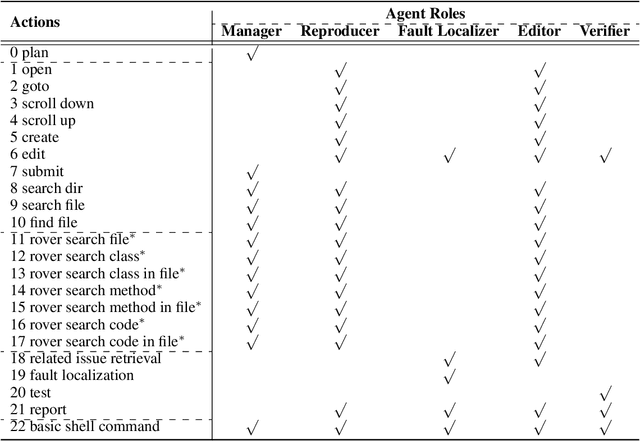

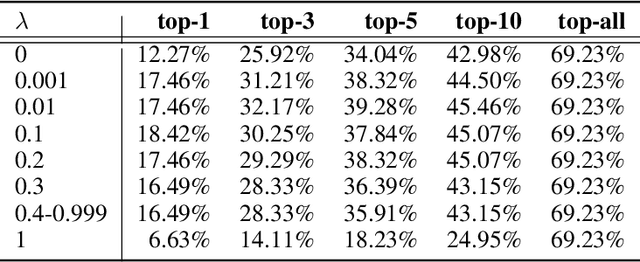
GitHub issue resolving recently has attracted significant attention from academia and industry. SWE-bench is proposed to measure the performance in resolving issues. In this paper, we propose CodeR, which adopts a multi-agent framework and pre-defined task graphs to Repair & Resolve reported bugs and add new features within code Repository. On SWE-bench lite, CodeR is able to solve 28.00% of issues, in the case of submitting only once for each issue. We examine the performance impact of each design of CodeR and offer insights to advance this research direction.
Finetuning Large Language Models for Vulnerability Detection
Jan 30, 2024This paper presents the results of finetuning large language models (LLMs) for the task of detecting vulnerabilities in source code. We leverage WizardCoder, a recent improvement of the state-of-the-art LLM StarCoder, and adapt it for vulnerability detection through further finetuning. To accelerate training, we modify WizardCoder's training procedure, also we investigate optimal training regimes. For the imbalanced dataset with many more negative examples than positive, we also explore different techniques to improve classification performance. The finetuned WizardCoder model achieves improvement in ROC AUC and F1 measures on balanced and imbalanced vulnerability datasets over CodeBERT-like model, demonstrating the effectiveness of adapting pretrained LLMs for vulnerability detection in source code. The key contributions are finetuning the state-of-the-art code LLM, WizardCoder, increasing its training speed without the performance harm, optimizing the training procedure and regimes, handling class imbalance, and improving performance on difficult vulnerability detection datasets. This demonstrates the potential for transfer learning by finetuning large pretrained language models for specialized source code analysis tasks.
Evaluation of ChatGPT Model for Vulnerability Detection
Apr 12, 2023In this technical report, we evaluated the performance of the ChatGPT and GPT-3 models for the task of vulnerability detection in code. Our evaluation was conducted on our real-world dataset, using binary and multi-label classification tasks on CWE vulnerabilities. We decided to evaluate the model because it has shown good performance on other code-based tasks, such as solving programming challenges and understanding code at a high level. However, we found that the ChatGPT model performed no better than a dummy classifier for both binary and multi-label classification tasks for code vulnerability detection.