 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024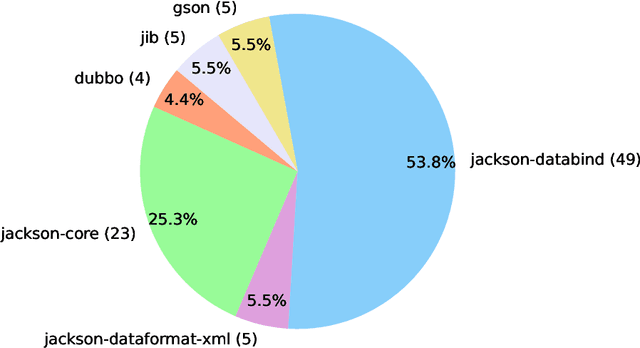



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
CodeR: Issue Resolving with Multi-Agent and Task Graphs
Jun 03, 2024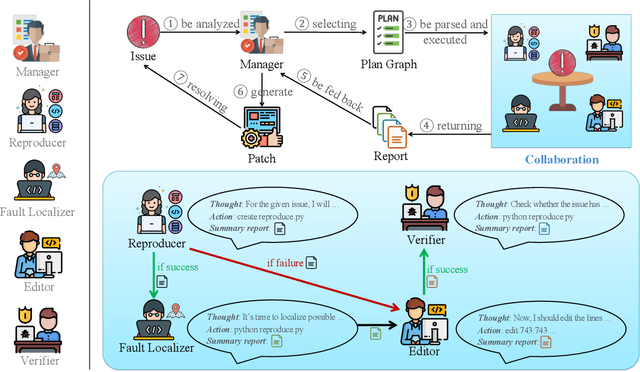
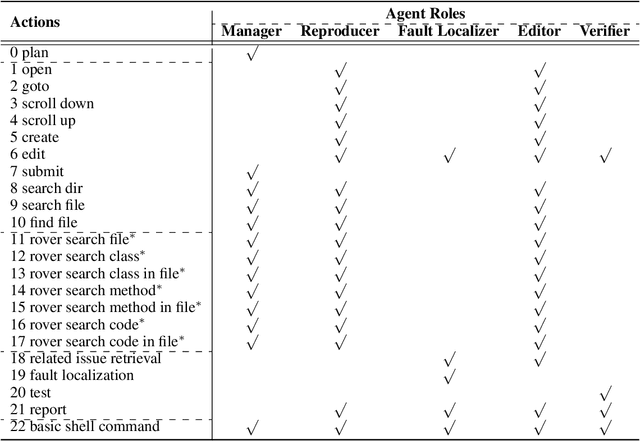

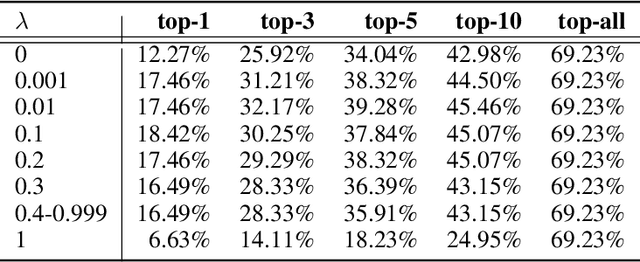
GitHub issue resolving recently has attracted significant attention from academia and industry. SWE-bench is proposed to measure the performance in resolving issues. In this paper, we propose CodeR, which adopts a multi-agent framework and pre-defined task graphs to Repair & Resolve reported bugs and add new features within code Repository. On SWE-bench lite, CodeR is able to solve 28.00% of issues, in the case of submitting only once for each issue. We examine the performance impact of each design of CodeR and offer insights to advance this research direction.
PanGu-Coder2: Boosting Large Language Models for Code with Ranking Feedback
Jul 27, 2023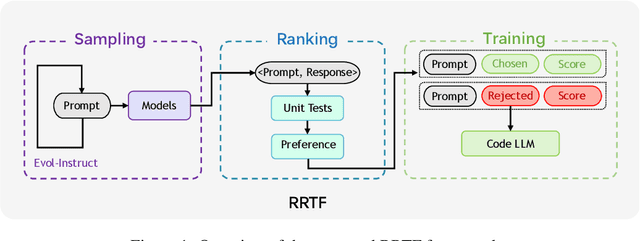

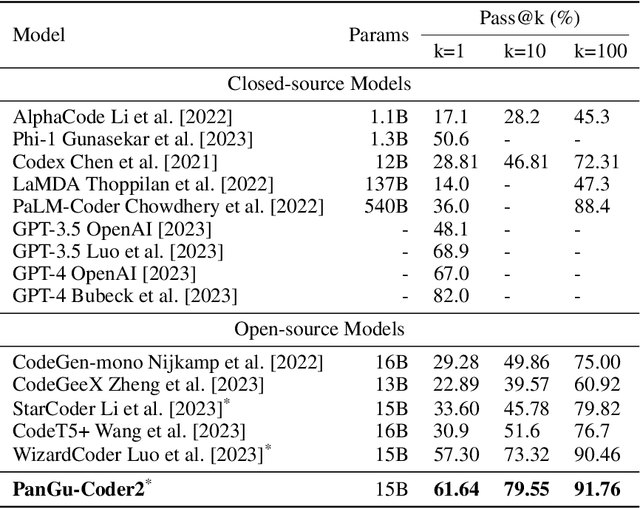
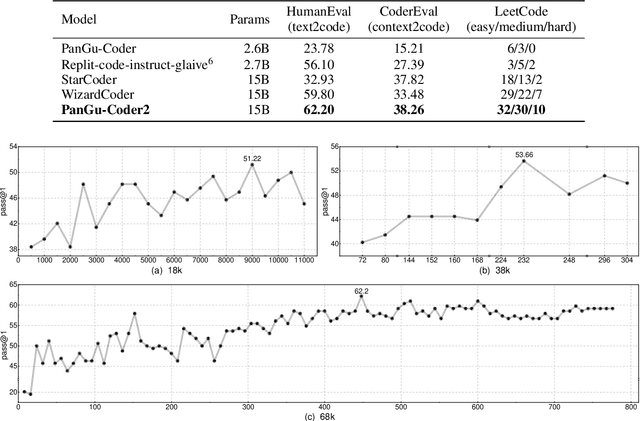
Large Language Models for Code (Code LLM) are flourishing. New and powerful models are released on a weekly basis, demonstrating remarkable performance on the code generation task. Various approaches have been proposed to boost the code generation performance of pre-trained Code LLMs, such as supervised fine-tuning, instruction tuning, reinforcement learning, etc. In this paper, we propose a novel RRTF (Rank Responses to align Test&Teacher Feedback) framework, which can effectively and efficiently boost pre-trained large language models for code generation. Under this framework, we present PanGu-Coder2, which achieves 62.20% pass@1 on the OpenAI HumanEval benchmark. Furthermore, through an extensive evaluation on CoderEval and LeetCode benchmarks, we show that PanGu-Coder2 consistently outperforms all previous Code LLMs.