 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArkTS-CodeSearch: A Open-Source ArkTS Dataset for Code Retrieval
Feb 05, 2026ArkTS is a core programming language in the OpenHarmony ecosystem, yet research on ArkTS code intelligence is hindered by the lack of public datasets and evaluation benchmarks. This paper presents a large-scale ArkTS dataset constructed from open-source repositories, targeting code retrieval and code evaluation tasks. We design a single-search task, where natural language comments are used to retrieve corresponding ArkTS functions. ArkTS repositories are crawled from GitHub and Gitee, and comment-function pairs are extracted using tree-sitter-arkts, followed by cross-platform deduplication and statistical analysis of ArkTS function types. We further evaluate all existing open-source code embedding models on the single-search task and perform fine-tuning using both ArkTS and TypeScript training datasets, resulting in a high-performing model for ArkTS code understanding. This work establishes the first systematic benchmark for ArkTS code retrieval. Both the dataset and our fine-tuned model will be released publicly and are available at https://huggingface.co/hreyulog/embedinggemma_arkts and https://huggingface.co/datasets/hreyulog/arkts-code-docstring,establishing the first systematic benchmark for ArkTS code retrieval.
CodeR: Issue Resolving with Multi-Agent and Task Graphs
Jun 03, 2024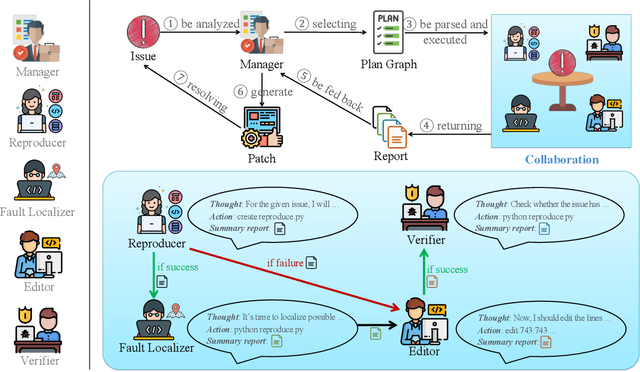
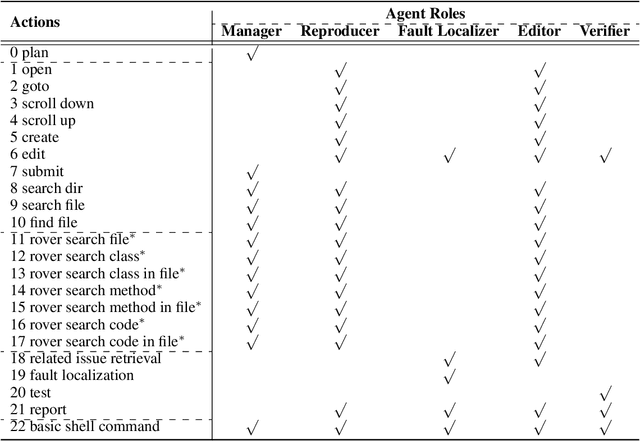

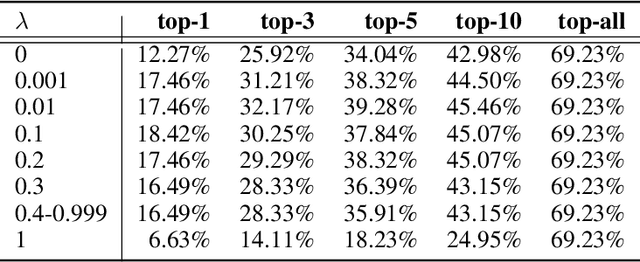
GitHub issue resolving recently has attracted significant attention from academia and industry. SWE-bench is proposed to measure the performance in resolving issues. In this paper, we propose CodeR, which adopts a multi-agent framework and pre-defined task graphs to Repair & Resolve reported bugs and add new features within code Repository. On SWE-bench lite, CodeR is able to solve 28.00% of issues, in the case of submitting only once for each issue. We examine the performance impact of each design of CodeR and offer insights to advance this research direction.