 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Programming using Semi-Supervision and Subset Selection
Aug 22, 2020
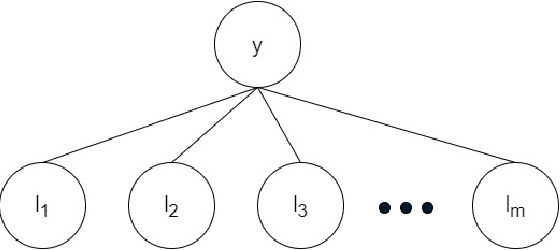
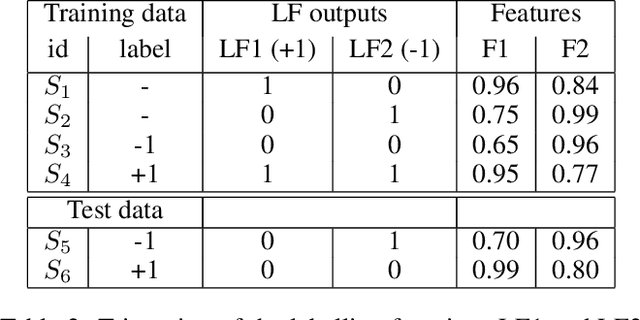
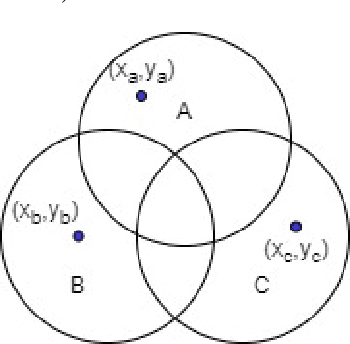
The paradigm of data programming~\cite{bach2019snorkel} has shown a lot of promise in using weak supervision in the form of rules and labelling functions to learn in scenarios where labelled data is not available. Another approach which has shown a lot of promise is that of semi-supervised learning where we augment small amounts of labelled data with a large unlabelled dataset. In this work, we argue that by not using any labelled data, data programming based approaches can yield sub-optimal performance, particularly, in cases when the labelling functions are noisy. The first contribution of this work is to study a framework of joint learning which combines un-supervised consensus from labelling functions with semi-supervised learning and \emph{jointly learns a model} to efficiently use the rules/labelling functions along with semi-supervised loss functions on the feature space. Next, we also study a subset selection approach to \emph{select} the set of examples which can be used as the labelled set. We evaluate our techniques on synthetic data as well as four publicly available datasets and show improvement over state-of-the-art techniques\footnote{Source code of the paper at \url{https://github.com/ayushbits/Semi-Supervised-LFs-Subset-Selection}}.