 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SWAG Algorithm; a Mathematical Approach that Outperforms Traditional Deep Learning. Theory and Implementation
Nov 28, 2018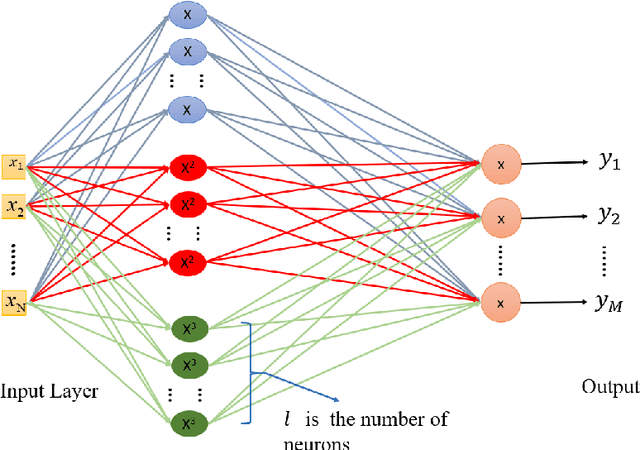
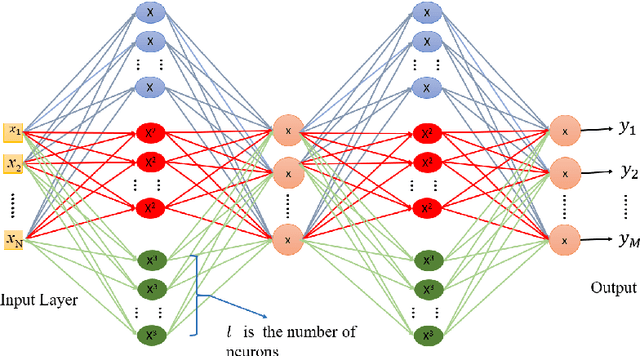

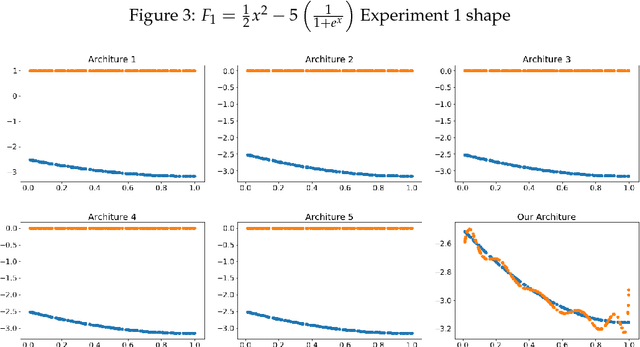
The performance of artificial neural networks (ANNs) is influenced by weight initialization, the nature of activation functions, and their architecture. There is a wide range of activation functions that are traditionally used to train a neural network, e.g. sigmoid, tanh, and Rectified Linear Unit (ReLU). A widespread practice is to use the same type of activation function in all neurons in a given layer. In this manuscript, we present a type of neural network in which the activation functions in every layer form a polynomial basis; we name this method SWAG after the initials of the last names of the authors. We tested SWAG on three complex highly non-linear functions as well as the MNIST handwriting data set. SWAG outperforms and converges faster than the state of the art performance in fully connected neural networks. Given the low computational complexity of SWAG, and the fact that it was capable of solving problems current architectures cannot, it has the potential to change the way that we approach deep learning.
Text Summarization Techniques: A Brief Survey
Jul 28, 2017In recent years, there has been a explosion in the amount of text data from a variety of sources. This volume of text is an invaluable source of information and knowledge which needs to be effectively summarized to be useful. In this review, the main approaches to automatic text summarization are described. We review the different processes for summarization and describe the effectiveness and shortcomings of the different methods.