 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBdSLW401: Transformer-Based Word-Level Bangla Sign Language Recognition Using Relative Quantization Encoding (RQE)
Mar 04, 2025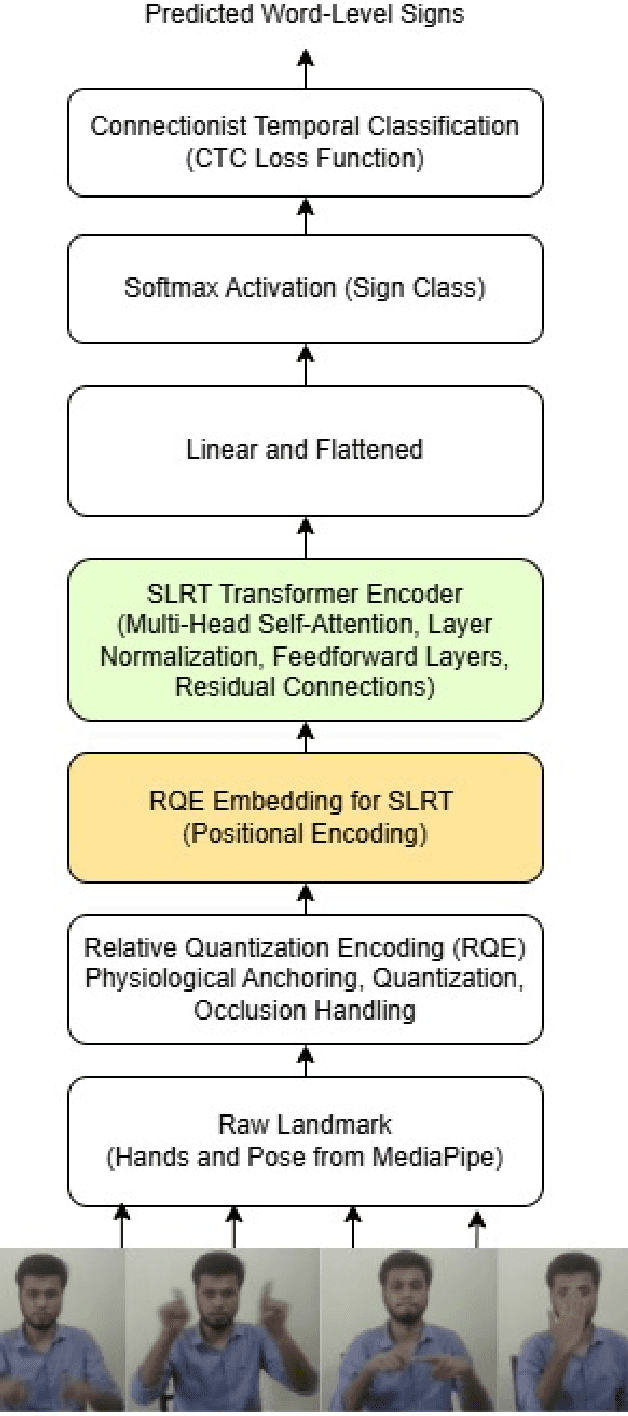
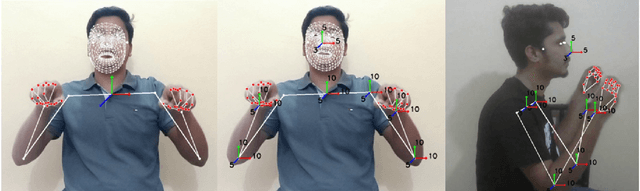
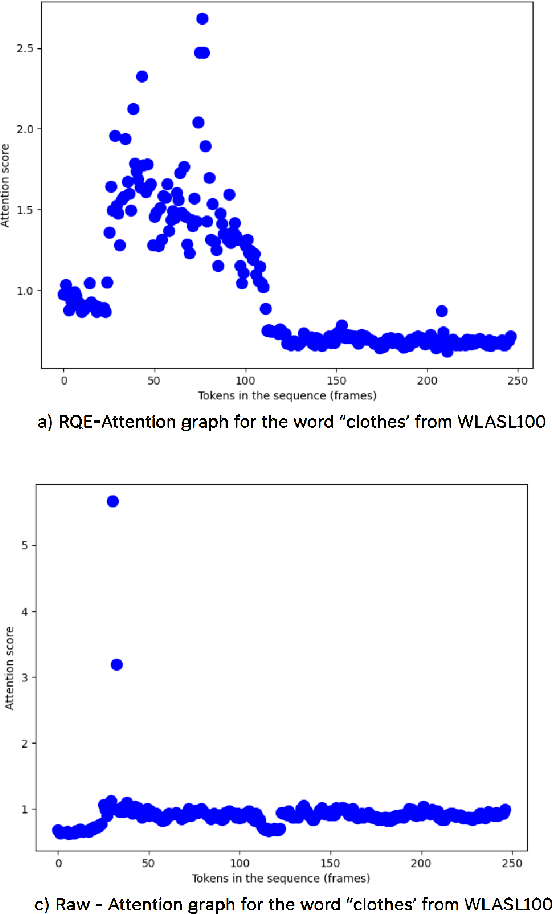

Sign language recognition (SLR) for low-resource languages like Bangla suffers from signer variability, viewpoint variations, and limited annotated datasets. In this paper, we present BdSLW401, a large-scale, multi-view, word-level Bangla Sign Language (BdSL) dataset with 401 signs and 102,176 video samples from 18 signers in front and lateral views. To improve transformer-based SLR, we introduce Relative Quantization Encoding (RQE), a structured embedding approach anchoring landmarks to physiological reference points and quantize motion trajectories. RQE improves attention allocation by decreasing spatial variability, resulting in 44.3% WER reduction in WLASL100, 21.0% in SignBD-200, and significant gains in BdSLW60 and SignBD-90. However, fixed quantization becomes insufficient on large-scale datasets (e.g., WLASL2000), indicating the need for adaptive encoding strategies. Further, RQE-SF, an extended variant that stabilizes shoulder landmarks, achieves improvements in pose consistency at the cost of small trade-offs in lateral view recognition. The attention graphs prove that RQE improves model interpretability by focusing on the major articulatory features (fingers, wrists) and the more distinctive frames instead of global pose changes. Introducing BdSLW401 and demonstrating the effectiveness of RQE-enhanced structured embeddings, this work advances transformer-based SLR for low-resource languages and sets a benchmark for future research in this area.