 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBdSLW401: Transformer-Based Word-Level Bangla Sign Language Recognition Using Relative Quantization Encoding (RQE)
Mar 04, 2025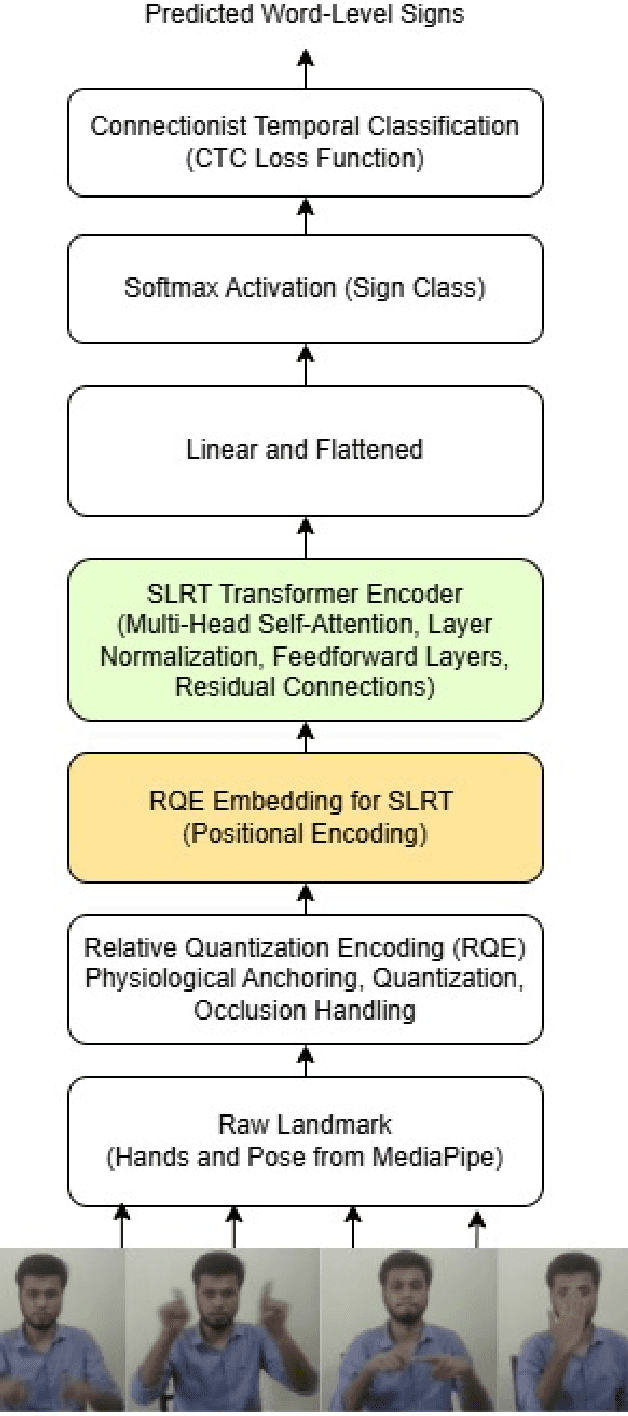
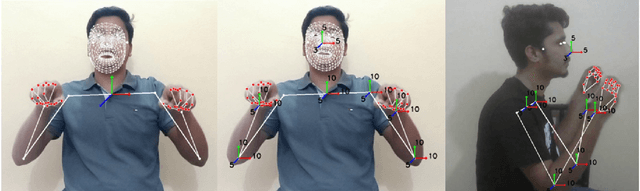
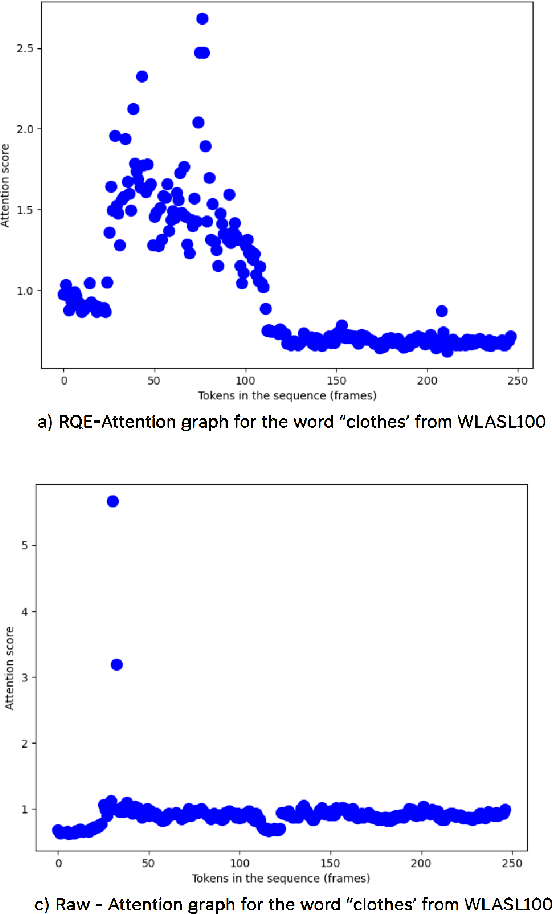

Sign language recognition (SLR) for low-resource languages like Bangla suffers from signer variability, viewpoint variations, and limited annotated datasets. In this paper, we present BdSLW401, a large-scale, multi-view, word-level Bangla Sign Language (BdSL) dataset with 401 signs and 102,176 video samples from 18 signers in front and lateral views. To improve transformer-based SLR, we introduce Relative Quantization Encoding (RQE), a structured embedding approach anchoring landmarks to physiological reference points and quantize motion trajectories. RQE improves attention allocation by decreasing spatial variability, resulting in 44.3% WER reduction in WLASL100, 21.0% in SignBD-200, and significant gains in BdSLW60 and SignBD-90. However, fixed quantization becomes insufficient on large-scale datasets (e.g., WLASL2000), indicating the need for adaptive encoding strategies. Further, RQE-SF, an extended variant that stabilizes shoulder landmarks, achieves improvements in pose consistency at the cost of small trade-offs in lateral view recognition. The attention graphs prove that RQE improves model interpretability by focusing on the major articulatory features (fingers, wrists) and the more distinctive frames instead of global pose changes. Introducing BdSLW401 and demonstrating the effectiveness of RQE-enhanced structured embeddings, this work advances transformer-based SLR for low-resource languages and sets a benchmark for future research in this area.
BdSLW60: A Word-Level Bangla Sign Language Dataset
Feb 13, 2024


Sign language discourse is an essential mode of daily communication for the deaf and hard-of-hearing people. However, research on Bangla Sign Language (BdSL) faces notable limitations, primarily due to the lack of datasets. Recognizing wordlevel signs in BdSL (WL-BdSL) presents a multitude of challenges, including the need for well-annotated datasets, capturing the dynamic nature of sign gestures from facial or hand landmarks, developing suitable machine learning or deep learning-based models with substantial video samples, and so on. In this paper, we address these challenges by creating a comprehensive BdSL word-level dataset named BdSLW60 in an unconstrained and natural setting, allowing positional and temporal variations and allowing sign users to change hand dominance freely. The dataset encompasses 60 Bangla sign words, with a significant scale of 9307 video trials provided by 18 signers under the supervision of a sign language professional. The dataset was rigorously annotated and cross-checked by 60 annotators. We also introduced a unique approach of a relative quantization-based key frame encoding technique for landmark based sign gesture recognition. We report the benchmarking of our BdSLW60 dataset using the Support Vector Machine (SVM) with testing accuracy up to 67.6% and an attention-based bi-LSTM with testing accuracy up to 75.1%. The dataset is available at https://www.kaggle.com/datasets/hasaniut/bdslw60 and the code base is accessible from https://github.com/hasanssl/BdSLW60_Code.
VIS-iTrack: Visual Intention through Gaze Tracking using Low-Cost Webcam
Feb 05, 2022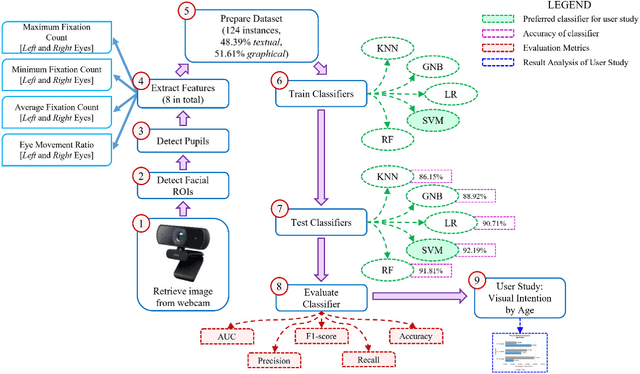
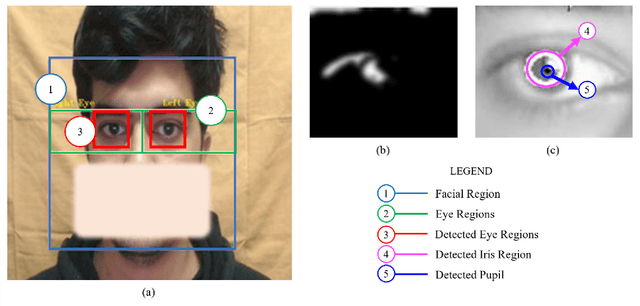
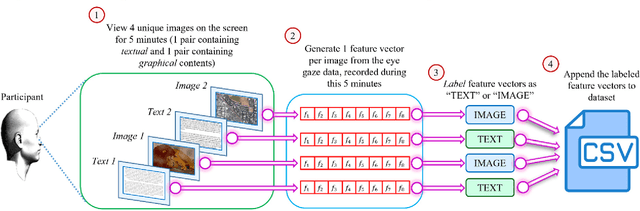
Human intention is an internal, mental characterization for acquiring desired information. From interactive interfaces containing either textual or graphical information, intention to perceive desired information is subjective and strongly connected with eye gaze. In this work, we determine such intention by analyzing real-time eye gaze data with a low-cost regular webcam. We extracted unique features (e.g., Fixation Count, Eye Movement Ratio) from the eye gaze data of 31 participants to generate a dataset containing 124 samples of visual intention for perceiving textual or graphical information, labeled as either TEXT or IMAGE, having 48.39% and 51.61% distribution, respectively. Using this dataset, we analyzed 5 classifiers, including Support Vector Machine (SVM) (Accuracy: 92.19%). Using the trained SVM, we investigated the variation of visual intention among 30 participants, distributed in 3 age groups, and found out that young users were more leaned towards graphical contents whereas older adults felt more interested in textual ones. This finding suggests that real-time eye gaze data can be a potential source of identifying visual intention, analyzing which intention aware interactive interfaces can be designed and developed to facilitate human cognition.