 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust CNN Multi-Nested-LSTM Framework with Compound Loss for Patch-based Multi-Push Ultrasound Shear Wave Imaging and Segmentation
Jul 30, 2024



Ultrasound Shear Wave Elastography (SWE) is a noteworthy tool for in-vivo noninvasive tissue pathology assessment. State-of-the-art techniques can generate reasonable estimates of tissue elasticity, but high-quality and noise-resiliency in SWE reconstruction have yet to demonstrate advancements. In this work, we propose a two-stage DL pipeline producing reliable reconstructions and denoise said reconstructions to obtain lower noise prevailing elasticity mappings. The reconstruction network consists of a Resnet3D Encoder to extract temporal context from the sequential multi-push data. The encoded features are sent to multiple Nested CNN LSTMs which process them in a temporal attention-guided windowing basis and map the 3D features to 2D using FFT-attention, which are then decoded into an elasticity map as primary reconstruction. The 2D maps from each multi-push region are merged and cleaned using a dual-decoder denoiser network, which independently denoises foreground and background before fusion. The post-denoiser generates a higher-quality reconstruction and an inclusion-segmentation mask. A multi-objective loss is designed to accommodate the denoising, fusing, and segmentation processes. The method is validated on sequential multi-push SWE motion data with multiple overlapping regions. A patch-based training procedure is introduced with network modifications to handle data scarcity. Evaluations produce 32.66dB PSNR, 43.19dB CNR in noisy simulation, and 22.44dB PSNR, 36.88dB CNR in experimental data, across all test samples. Moreover, IoUs (0.909 and 0.781) were quite satisfactory in the datasets. After comparing with other reported deep-learning approaches, our method proves quantitatively and qualitatively superior in dealing with noise influences in SWE data. From a performance point of view, our deep-learning pipeline has the potential to become utilitarian in the clinical domain.
BdSLW60: A Word-Level Bangla Sign Language Dataset
Feb 13, 2024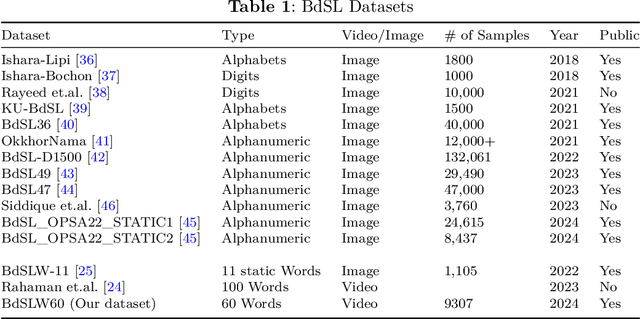

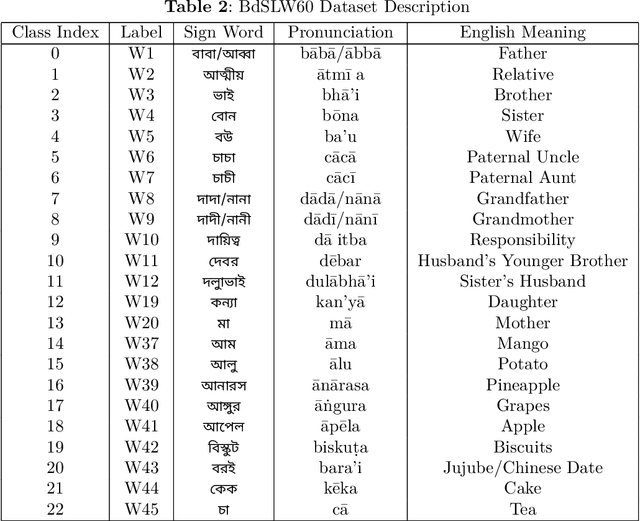

Sign language discourse is an essential mode of daily communication for the deaf and hard-of-hearing people. However, research on Bangla Sign Language (BdSL) faces notable limitations, primarily due to the lack of datasets. Recognizing wordlevel signs in BdSL (WL-BdSL) presents a multitude of challenges, including the need for well-annotated datasets, capturing the dynamic nature of sign gestures from facial or hand landmarks, developing suitable machine learning or deep learning-based models with substantial video samples, and so on. In this paper, we address these challenges by creating a comprehensive BdSL word-level dataset named BdSLW60 in an unconstrained and natural setting, allowing positional and temporal variations and allowing sign users to change hand dominance freely. The dataset encompasses 60 Bangla sign words, with a significant scale of 9307 video trials provided by 18 signers under the supervision of a sign language professional. The dataset was rigorously annotated and cross-checked by 60 annotators. We also introduced a unique approach of a relative quantization-based key frame encoding technique for landmark based sign gesture recognition. We report the benchmarking of our BdSLW60 dataset using the Support Vector Machine (SVM) with testing accuracy up to 67.6% and an attention-based bi-LSTM with testing accuracy up to 75.1%. The dataset is available at https://www.kaggle.com/datasets/hasaniut/bdslw60 and the code base is accessible from https://github.com/hasanssl/BdSLW60_Code.
Optimising complexity of CNN models for resource constrained devices: QRS detection case study
Jan 23, 2023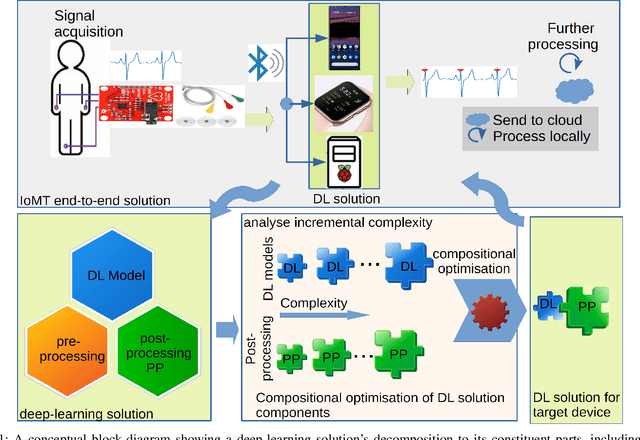
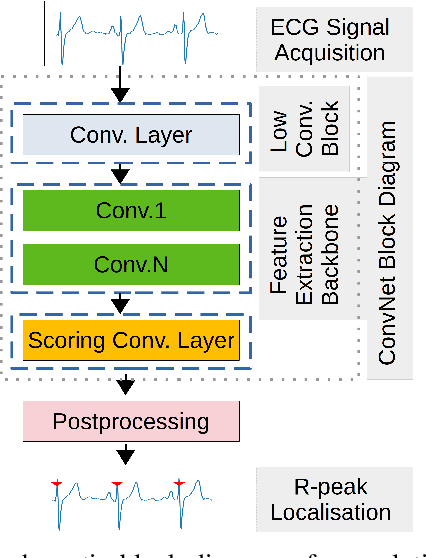
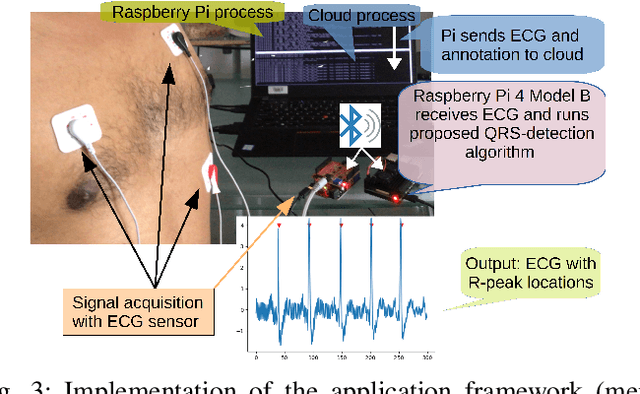
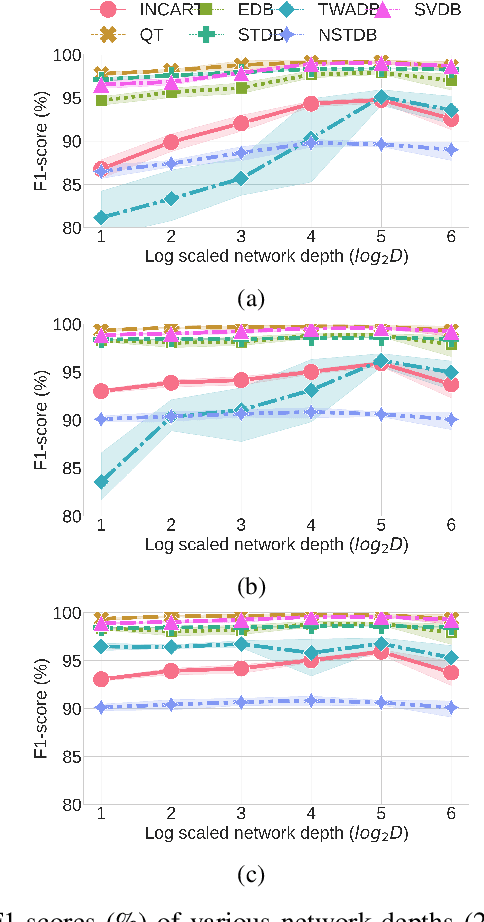
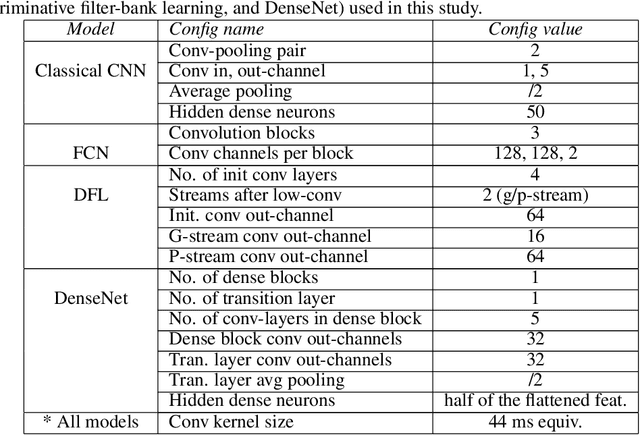
Traditional DL models are complex and resource hungry and thus, care needs to be taken in designing Internet of (medical) things (IoT, or IoMT) applications balancing efficiency-complexity trade-off. Recent IoT solutions tend to avoid using deep-learning methods due to such complexities, and rather classical filter-based methods are commonly used. We hypothesize that a shallow CNN model can offer satisfactory level of performance in combination by leveraging other essential solution-components, such as post-processing that is suitable for resource constrained environment. In an IoMT application context, QRS-detection and R-peak localisation from ECG signal as a case study, the complexities of CNN models and post-processing were varied to identify a set of combinations suitable for a range of target resource-limited environments. To the best of our knowledge, finding a deploy-able configuration, by incrementally increasing the CNN model complexity, as required to match the target's resource capacity, and leveraging the strength of post-processing, is the first of its kind. The results show that a shallow 2-layer CNN with a suitable post-processing can achieve $>$90\% F1-score, and the scores continue to improving for 8-32 layer CNNs, which can be used to profile target constraint environment. The outcome shows that it is possible to design an optimal DL solution with known target performance characteristics and resource (computing capacity, and memory) constraints.
Learning post-processing for QRS detection using Recurrent Neural Network
Oct 07, 2021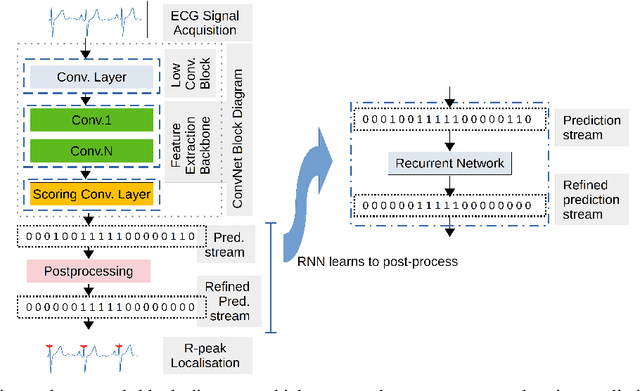
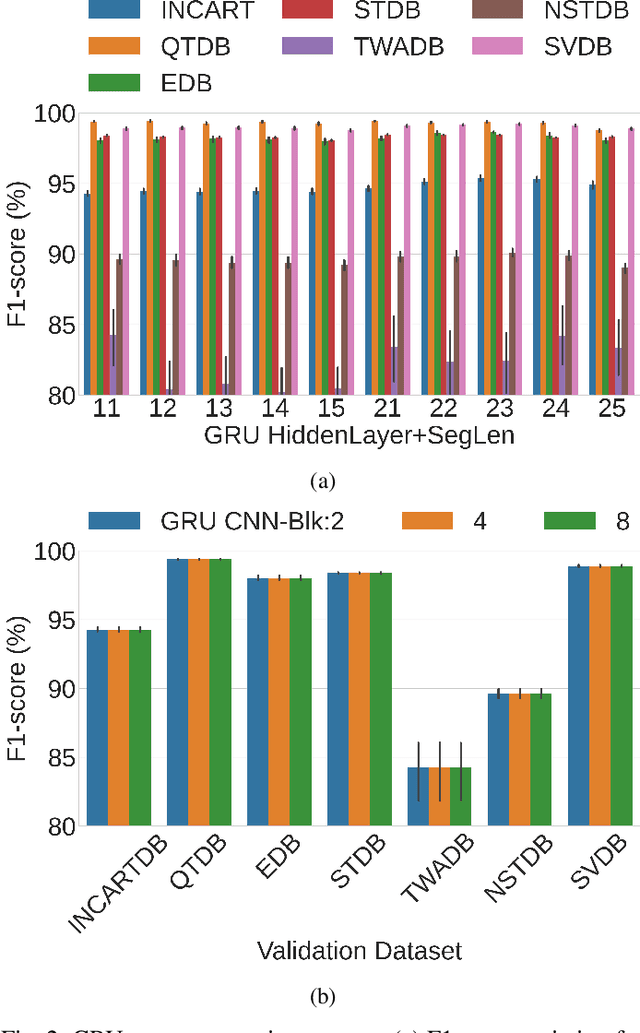
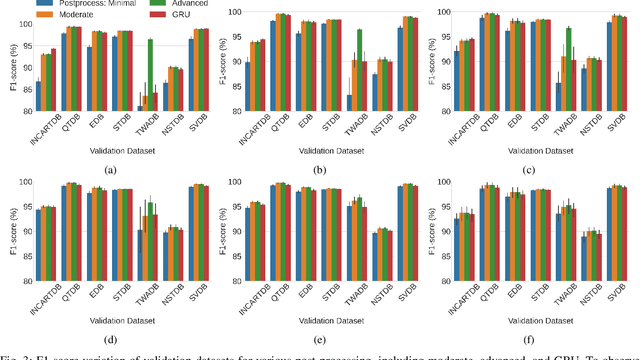
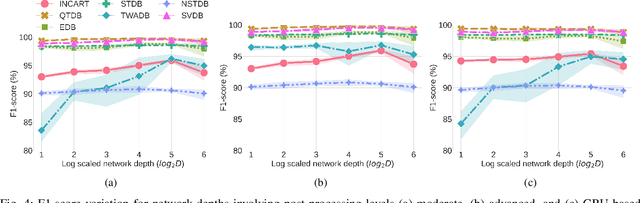
Deep-learning based QRS-detection algorithms often require essential post-processing to refine the prediction streams for R-peak localisation. The post-processing performs signal-processing tasks from as simple as, removing isolated 0s or 1s in the prediction-stream to sophisticated steps, which require domain-specific knowledge, including the minimum threshold of a QRS-complex extent or R-R interval. Often these thresholds vary among QRS-detection studies and are empirically determined for the target dataset, which may have implications if the target dataset differs. Moreover, these studies, in general, fail to identify the relative strengths of deep-learning models and post-processing to weigh them appropriately. This study classifies post-processing, as found in the QRS-detection literature, into two levels - moderate, and advanced - and advocates that the thresholds be learned by an appropriate deep-learning module, called a Gated Recurrent Unit (GRU), to avoid explicitly setting post-processing thresholds. This is done by utilising the same philosophy of shifting from hand-crafted feature-engineering to deep-learning-based feature-extraction. The results suggest that GRU learns the post-processing level and the QRS detection performance using GRU-based post-processing marginally follows the domain-specific manual post-processing, without requiring usage of domain-specific threshold parameters. To the best of our knowledge, the use of GRU to learn QRS-detection post-processing from CNN model generated prediction streams is the first of its kind. The outcome was used to recommend a modular design for a QRS-detection system, where the level of complexity of the CNN model and post-processing can be tuned based on the deployment environment.
Choosing a sampling frequency for ECG QRS detection using convolutional networks
Jul 04, 2020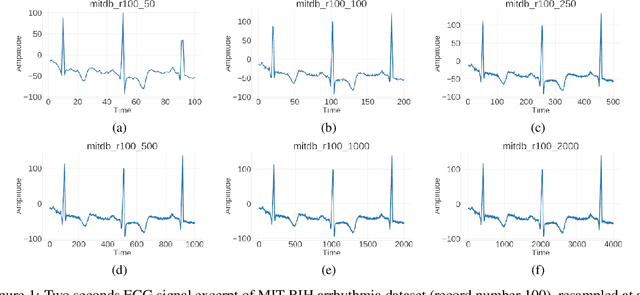
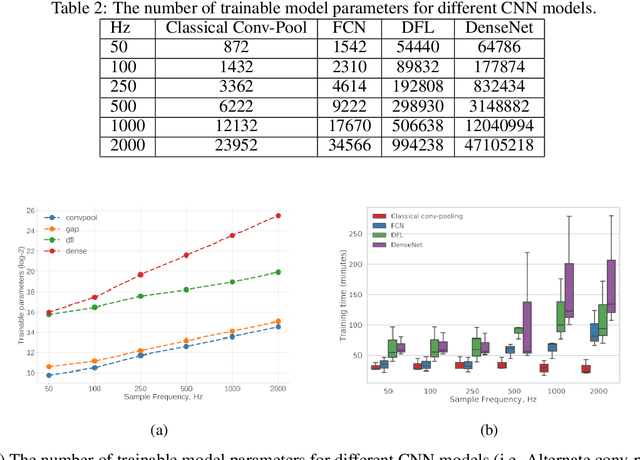
Automated QRS detection methods depend on the ECG data which is sampled at a certain frequency, irrespective of filter-based traditional methods or convolutional network (CNN) based deep learning methods. These methods require a selection of the sampling frequency at which they operate in the very first place. While working with data from two different datasets, which are sampled at different frequencies, often, data from both the datasets may need to resample at a common target frequency, which may be the frequency of either of the datasets or could be a different one. However, choosing data sampled at a certain frequency may have an impact on the model's generalisation capacity, and complexity. There exist some studies that investigate the effects of ECG sample frequencies on traditional filter-based methods, however, an extensive study of the effect of ECG sample frequency on deep learning-based models (convolutional networks), exploring their generalisability and complexity is yet to be explored. This experimental research investigates the impact of six different sample frequencies (50, 100, 250, 500, 1000, and 2000Hz) on four different convolutional network-based models' generalisability and complexity in order to form a basis to decide on an appropriate sample frequency for the QRS detection task for a particular performance requirement. Intra-database tests report an accuracy improvement no more than approximately 0.6\% from 100Hz to 250Hz and the shorter interquartile range for those two frequencies for all CNN-based models. The findings reveal that convolutional network-based deep learning models are capable of scoring higher levels of detection accuracies on ECG signals sampled at frequencies as low as 100Hz or 250Hz while maintaining lower model complexity (number of trainable parameters and training time).