 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Dialogue Dataset Generation using LLM Agents
Jan 30, 2024

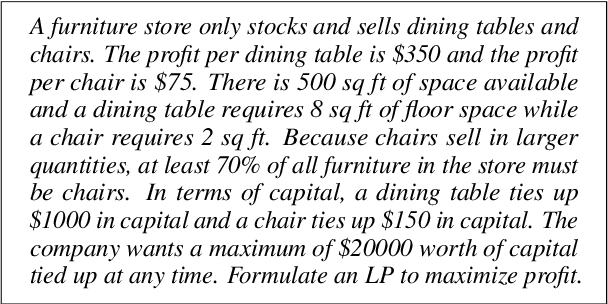
Linear programming (LP) problems are pervasive in real-life applications. However, despite their apparent simplicity, an untrained user may find it difficult to determine the linear model of their specific problem. We envisage the creation of a goal-oriented conversational agent that will engage in conversation with the user to elicit all information required so that a subsequent agent can generate the linear model. In this paper, we present an approach for the generation of sample dialogues that can be used to develop and train such a conversational agent. Using prompt engineering, we develop two agents that "talk" to each other, one acting as the conversational agent, and the other acting as the user. Using a set of text descriptions of linear problems from NL4Opt available to the user only, the agent and the user engage in conversation until the agent has retrieved all key information from the original problem description. We also propose an extrinsic evaluation of the dialogues by assessing how well the summaries generated by the dialogues match the original problem descriptions. We conduct human and automatic evaluations, including an evaluation approach that uses GPT-4 to mimic the human evaluation metrics. The evaluation results show an overall good quality of the dialogues, though research is still needed to improve the quality of the GPT-4 evaluation metrics. The resulting dialogues, including the human annotations of a subset, are available to the research community. The conversational agent used for the generation of the dialogues can be used as a baseline.
MVC: A Multi-Task Vision Transformer Network for COVID-19 Diagnosis from Chest X-ray Images
Sep 30, 2023Medical image analysis using computer-based algorithms has attracted considerable attention from the research community and achieved tremendous progress in the last decade. With recent advances in computing resources and availability of large-scale medical image datasets, many deep learning models have been developed for disease diagnosis from medical images. However, existing techniques focus on sub-tasks, e.g., disease classification and identification, individually, while there is a lack of a unified framework enabling multi-task diagnosis. Inspired by the capability of Vision Transformers in both local and global representation learning, we propose in this paper a new method, namely Multi-task Vision Transformer (MVC) for simultaneously classifying chest X-ray images and identifying affected regions from the input data. Our method is built upon the Vision Transformer but extends its learning capability in a multi-task setting. We evaluated our proposed method and compared it with existing baselines on a benchmark dataset of COVID-19 chest X-ray images. Experimental results verified the superiority of the proposed method over the baselines on both the image classification and affected region identification tasks.
Optimising complexity of CNN models for resource constrained devices: QRS detection case study
Jan 23, 2023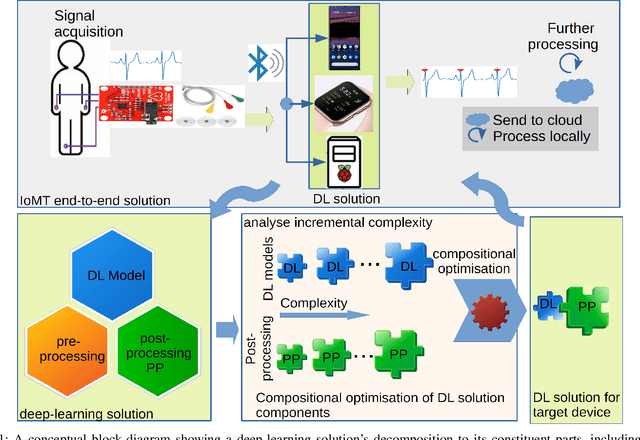
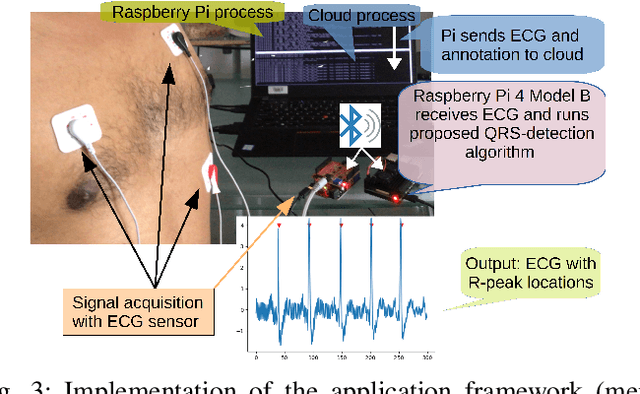
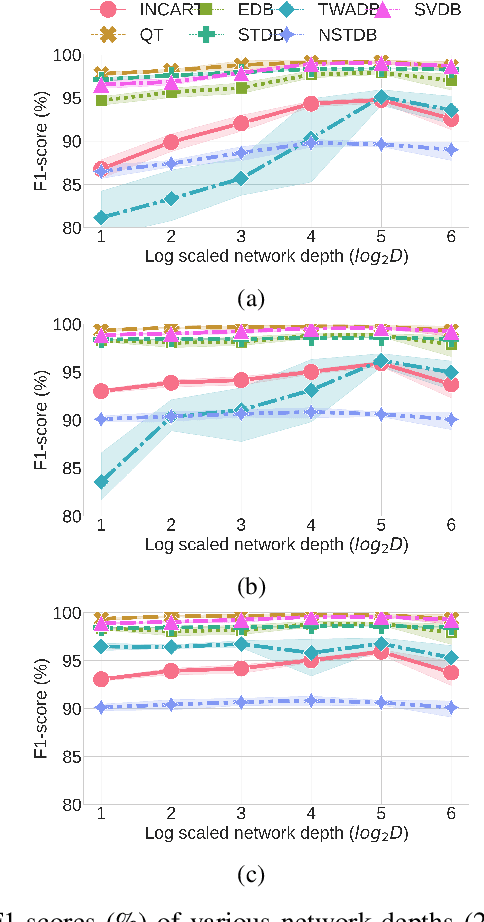
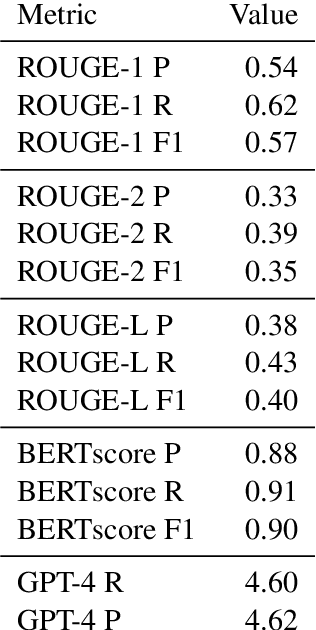
Traditional DL models are complex and resource hungry and thus, care needs to be taken in designing Internet of (medical) things (IoT, or IoMT) applications balancing efficiency-complexity trade-off. Recent IoT solutions tend to avoid using deep-learning methods due to such complexities, and rather classical filter-based methods are commonly used. We hypothesize that a shallow CNN model can offer satisfactory level of performance in combination by leveraging other essential solution-components, such as post-processing that is suitable for resource constrained environment. In an IoMT application context, QRS-detection and R-peak localisation from ECG signal as a case study, the complexities of CNN models and post-processing were varied to identify a set of combinations suitable for a range of target resource-limited environments. To the best of our knowledge, finding a deploy-able configuration, by incrementally increasing the CNN model complexity, as required to match the target's resource capacity, and leveraging the strength of post-processing, is the first of its kind. The results show that a shallow 2-layer CNN with a suitable post-processing can achieve $>$90\% F1-score, and the scores continue to improving for 8-32 layer CNNs, which can be used to profile target constraint environment. The outcome shows that it is possible to design an optimal DL solution with known target performance characteristics and resource (computing capacity, and memory) constraints.
Learning post-processing for QRS detection using Recurrent Neural Network
Oct 07, 2021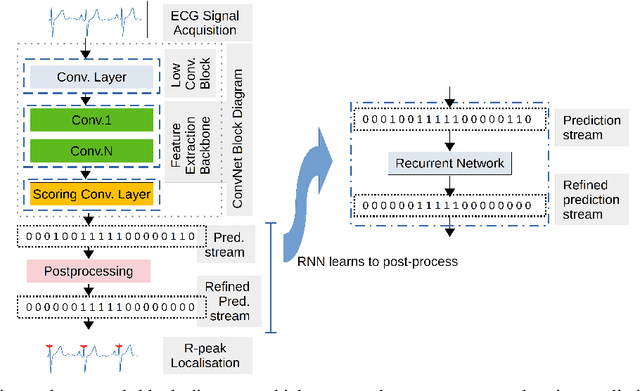
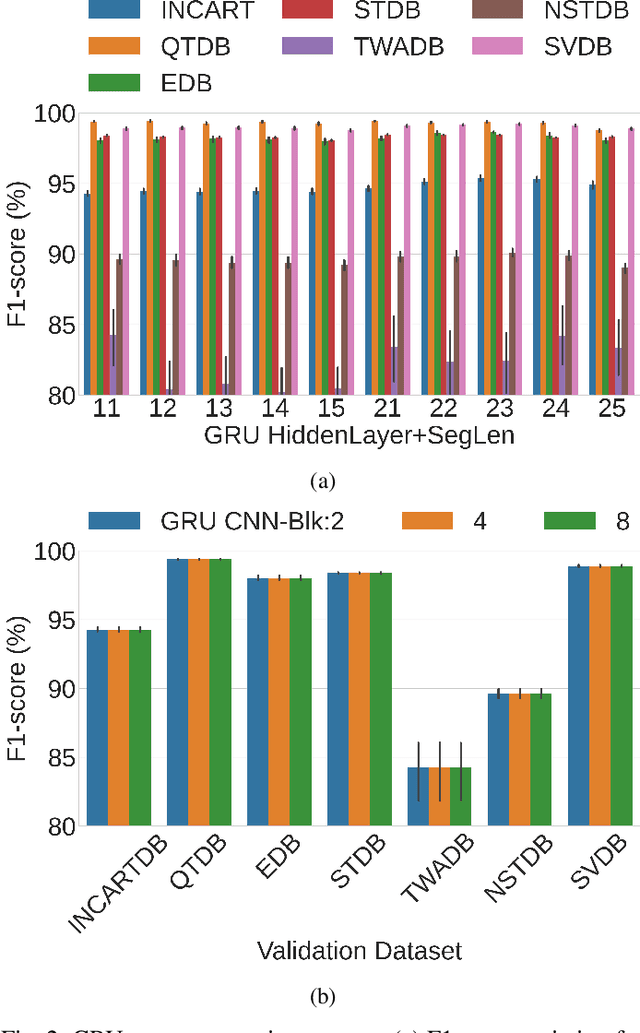
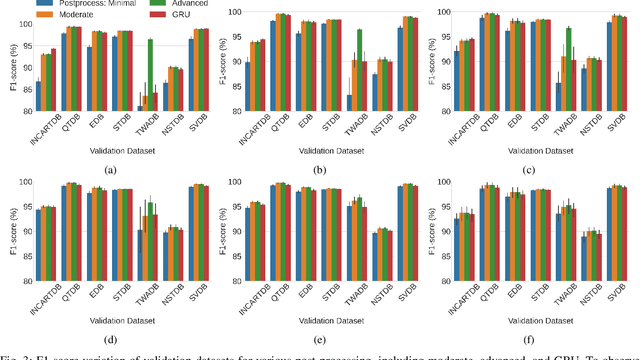
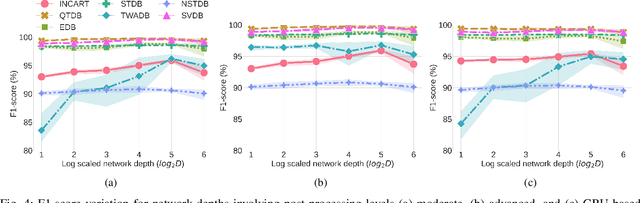
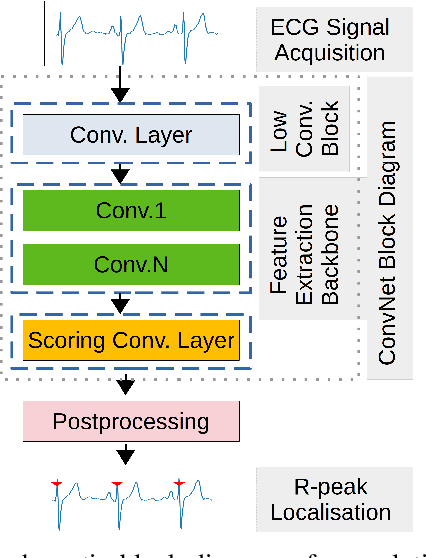
Deep-learning based QRS-detection algorithms often require essential post-processing to refine the prediction streams for R-peak localisation. The post-processing performs signal-processing tasks from as simple as, removing isolated 0s or 1s in the prediction-stream to sophisticated steps, which require domain-specific knowledge, including the minimum threshold of a QRS-complex extent or R-R interval. Often these thresholds vary among QRS-detection studies and are empirically determined for the target dataset, which may have implications if the target dataset differs. Moreover, these studies, in general, fail to identify the relative strengths of deep-learning models and post-processing to weigh them appropriately. This study classifies post-processing, as found in the QRS-detection literature, into two levels - moderate, and advanced - and advocates that the thresholds be learned by an appropriate deep-learning module, called a Gated Recurrent Unit (GRU), to avoid explicitly setting post-processing thresholds. This is done by utilising the same philosophy of shifting from hand-crafted feature-engineering to deep-learning-based feature-extraction. The results suggest that GRU learns the post-processing level and the QRS detection performance using GRU-based post-processing marginally follows the domain-specific manual post-processing, without requiring usage of domain-specific threshold parameters. To the best of our knowledge, the use of GRU to learn QRS-detection post-processing from CNN model generated prediction streams is the first of its kind. The outcome was used to recommend a modular design for a QRS-detection system, where the level of complexity of the CNN model and post-processing can be tuned based on the deployment environment.
Knowledge engineering mixed-integer linear programming: constraint typology
Feb 20, 2021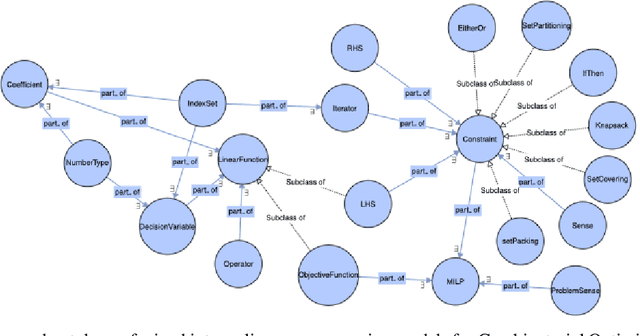
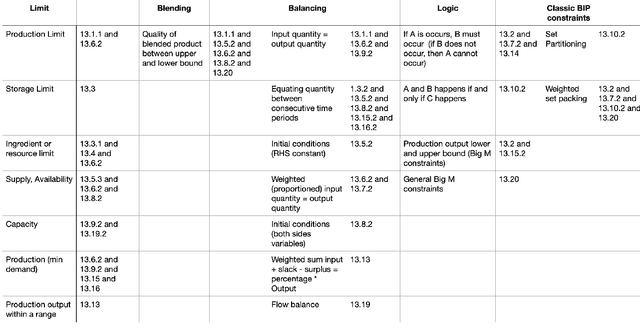
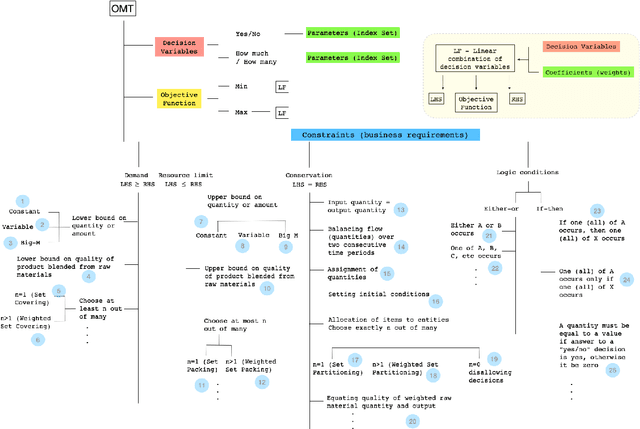
In this paper, we investigate the constraint typology of mixed-integer linear programming MILP formulations. MILP is a commonly used mathematical programming technique for modelling and solving real-life scheduling, routing, planning, resource allocation, timetabling optimization problems, providing optimized business solutions for industry sectors such as: manufacturing, agriculture, defence, healthcare, medicine, energy, finance, and transportation. Despite the numerous real-life Combinatorial Optimization Problems found and solved, and millions yet to be discovered and formulated, the number of types of constraints, the building blocks of a MILP, is relatively much smaller. In the search of a suitable machine readable knowledge representation for MILPs, we propose an optimization modelling tree built based upon an MILP ontology that can be used as a guidance for automated systems to elicit an MILP model from end-users on their combinatorial business optimization problems.
A Knowledge Representation Approach to Automated Mathematical Modelling
Nov 12, 2020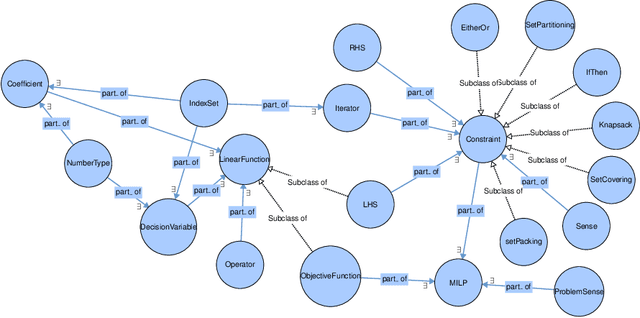
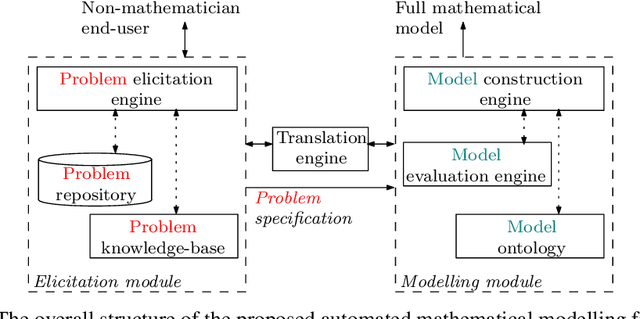
Mathematicians formulate complex mathematical models based on user requirements to solve a diverse range of problems in different domains. These models are, in most cases, represented through several mathematical equations and constraints. This modelling task comprises several time-intensive processes that require both mathematical expertise and (problem) domain knowledge. In an attempt to automate these processes, we have developed an ontology for Mixed Integer Linear Programming (MILP) problems to formulate expert mathematician knowledge and in this paper, we show how this new ontology can be utilized for modelling a relatively straightforward MILP problem, a Machine Scheduling example. We also show that more complex MILP problems, such as the Asymmetric Travelling Salesman Problem (ATSP), however, are not readily amenable to simple elicitation of user requirements and the utilization of the proposed mathematical model ontology. Therefore, an automatic mathematical modelling framework is proposed for such complex MILP problems, which includes a problem (requirement) elicitation module connected to a model extraction module through a translation engine that bridges between the non-expert problem domain and the expert mathematical model domain. This framework is argued to have the necessary components to effectively tackle the automation of modelling task of the more intricate MILP problems such as the ATSP.
Choosing a sampling frequency for ECG QRS detection using convolutional networks
Jul 04, 2020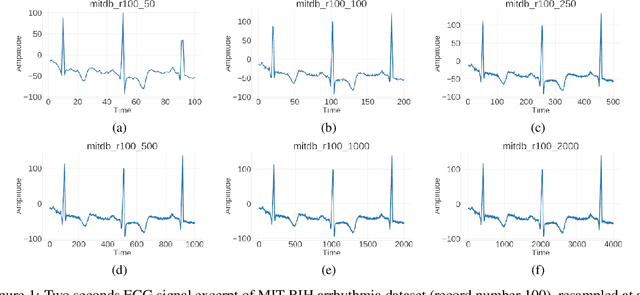
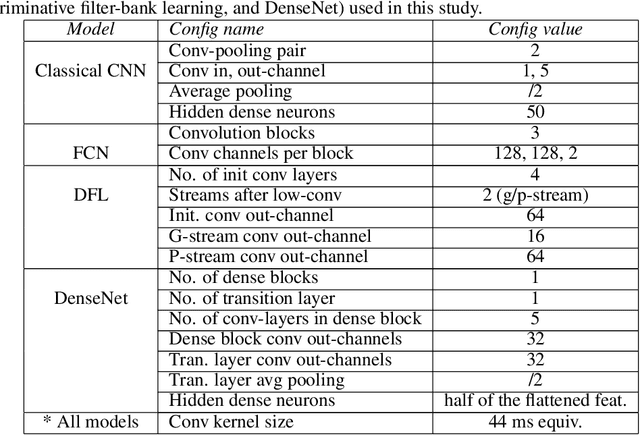
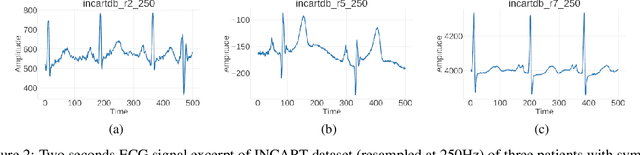
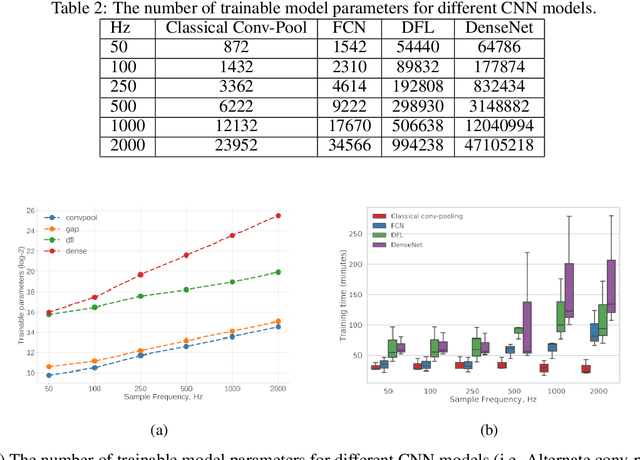
Automated QRS detection methods depend on the ECG data which is sampled at a certain frequency, irrespective of filter-based traditional methods or convolutional network (CNN) based deep learning methods. These methods require a selection of the sampling frequency at which they operate in the very first place. While working with data from two different datasets, which are sampled at different frequencies, often, data from both the datasets may need to resample at a common target frequency, which may be the frequency of either of the datasets or could be a different one. However, choosing data sampled at a certain frequency may have an impact on the model's generalisation capacity, and complexity. There exist some studies that investigate the effects of ECG sample frequencies on traditional filter-based methods, however, an extensive study of the effect of ECG sample frequency on deep learning-based models (convolutional networks), exploring their generalisability and complexity is yet to be explored. This experimental research investigates the impact of six different sample frequencies (50, 100, 250, 500, 1000, and 2000Hz) on four different convolutional network-based models' generalisability and complexity in order to form a basis to decide on an appropriate sample frequency for the QRS detection task for a particular performance requirement. Intra-database tests report an accuracy improvement no more than approximately 0.6\% from 100Hz to 250Hz and the shorter interquartile range for those two frequencies for all CNN-based models. The findings reveal that convolutional network-based deep learning models are capable of scoring higher levels of detection accuracies on ECG signals sampled at frequencies as low as 100Hz or 250Hz while maintaining lower model complexity (number of trainable parameters and training time).
Robust artificial neural networks and outlier detection. Technical report
Oct 02, 2011
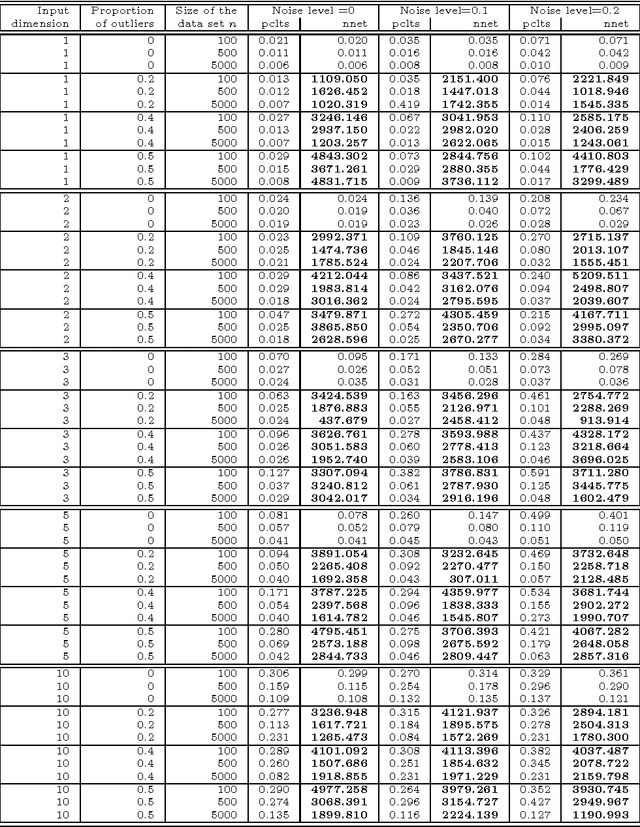
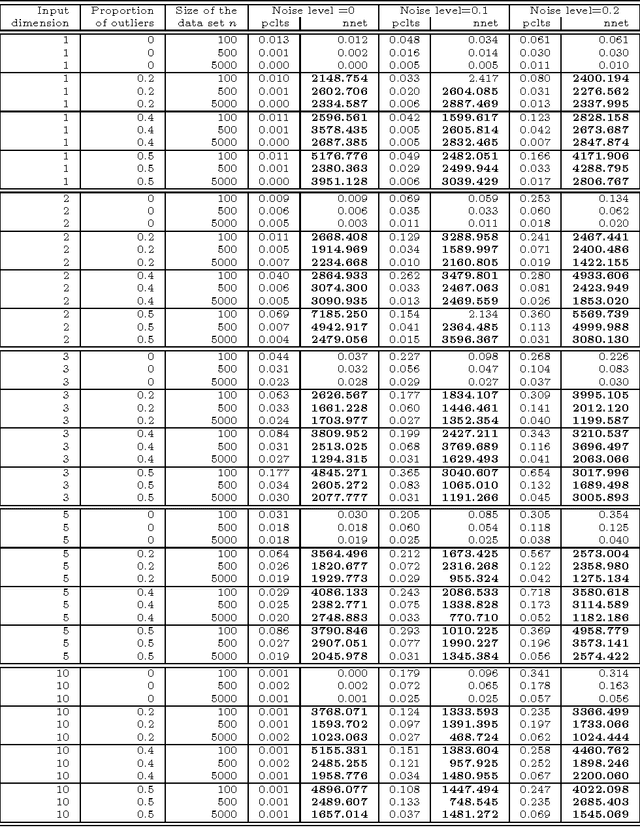
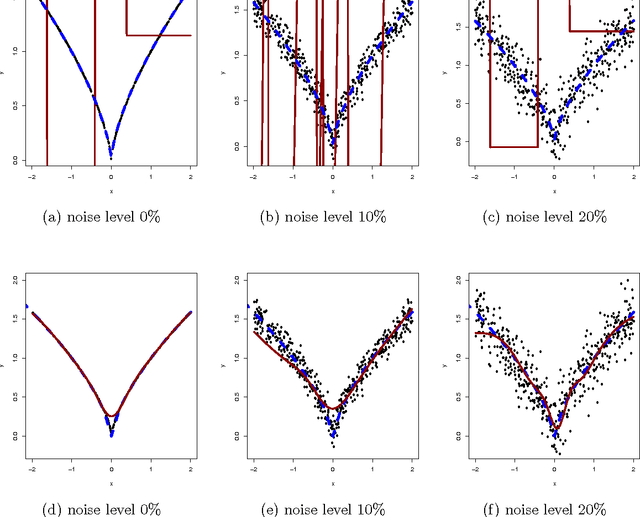
Large outliers break down linear and nonlinear regression models. Robust regression methods allow one to filter out the outliers when building a model. By replacing the traditional least squares criterion with the least trimmed squares criterion, in which half of data is treated as potential outliers, one can fit accurate regression models to strongly contaminated data. High-breakdown methods have become very well established in linear regression, but have started being applied for non-linear regression only recently. In this work, we examine the problem of fitting artificial neural networks to contaminated data using least trimmed squares criterion. We introduce a penalized least trimmed squares criterion which prevents unnecessary removal of valid data. Training of ANNs leads to a challenging non-smooth global optimization problem. We compare the efficiency of several derivative-free optimization methods in solving it, and show that our approach identifies the outliers correctly when ANNs are used for nonlinear regression.