 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Clustering with OWA-based Linkages, the Lance-Williams Formula, and Dendrogram Inversions
Mar 10, 2023Agglomerative hierarchical clustering based on Ordered Weighted Averaging (OWA) operators not only generalises the single, complete, and average linkages, but also includes intercluster distances based on a few nearest or farthest neighbours, trimmed and winsorised means of pairwise point similarities, amongst many others. We explore the relationships between the famous Lance-Williams update formula and the extended OWA-based linkages with weights generated via infinite coefficient sequences. Furthermore, we provide some conditions for the weight generators to guarantee the resulting dendrograms to be free from unaesthetic inversions.
Weakly monotone averaging functions
Aug 02, 2014Monotonicity with respect to all arguments is fundamental to the definition of aggregation functions. It is also a limiting property that results in many important non-monotonic averaging functions being excluded from the theoretical framework. This work proposes a definition for weakly monotonic averaging functions, studies some properties of this class of functions and proves that several families of important non-monotonic means are actually weakly monotonic averaging functions. Specifically we provide sufficient conditions for weak monotonicity of the Lehmer mean and generalised mixture operators. We establish weak monotonicity of several robust estimators of location and conditions for weak monotonicity of a large class of penalty-based aggregation functions. These results permit a proof of the weak monotonicity of the class of spatial-tonal filters that include important members such as the bilateral filter and anisotropic diffusion. Our concept of weak monotonicity provides a sound theoretical and practical basis by which (monotone) aggregation functions and non-monotone averaging functions can be related within the same framework, allowing us to bridge the gap between these previously disparate areas of research.
Robust artificial neural networks and outlier detection. Technical report
Oct 02, 2011
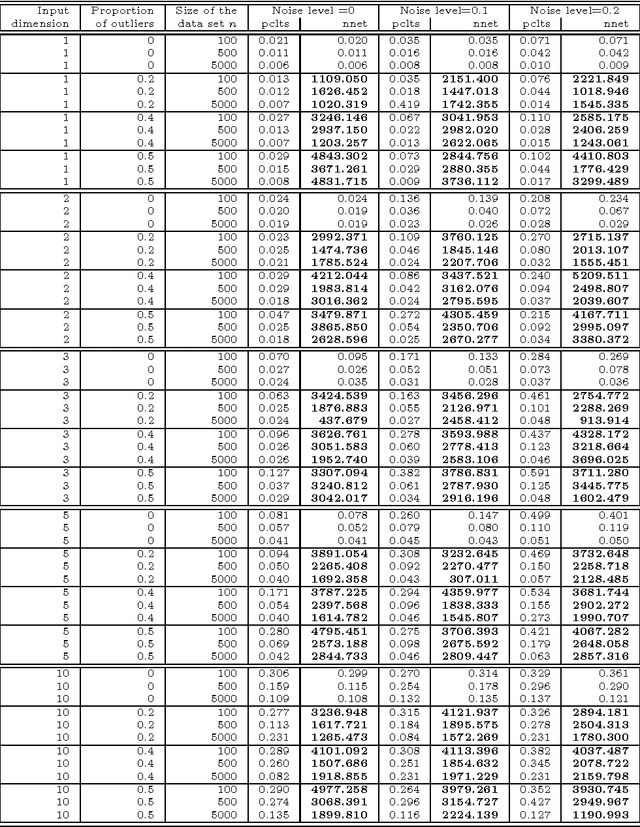
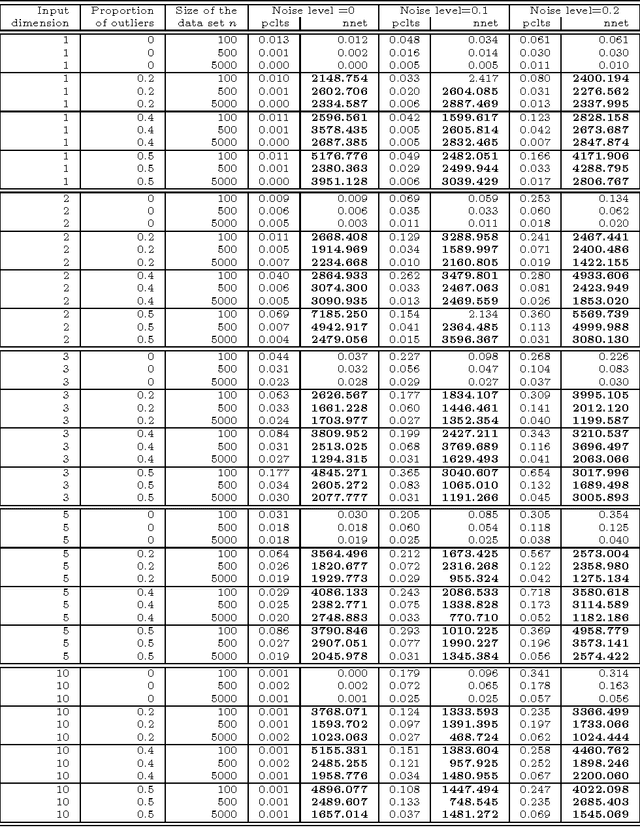
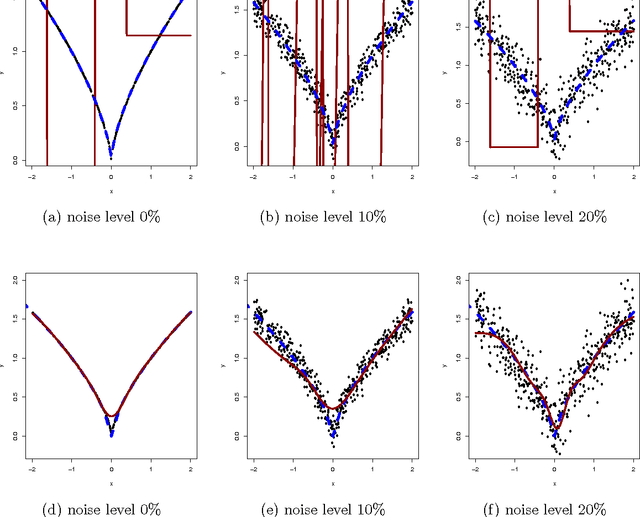
Large outliers break down linear and nonlinear regression models. Robust regression methods allow one to filter out the outliers when building a model. By replacing the traditional least squares criterion with the least trimmed squares criterion, in which half of data is treated as potential outliers, one can fit accurate regression models to strongly contaminated data. High-breakdown methods have become very well established in linear regression, but have started being applied for non-linear regression only recently. In this work, we examine the problem of fitting artificial neural networks to contaminated data using least trimmed squares criterion. We introduce a penalized least trimmed squares criterion which prevents unnecessary removal of valid data. Training of ANNs leads to a challenging non-smooth global optimization problem. We compare the efficiency of several derivative-free optimization methods in solving it, and show that our approach identifies the outliers correctly when ANNs are used for nonlinear regression.