 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximizing Generalization: The Effect of Different Augmentation Techniques on Lightweight Vision Transformer for Bengali Character Classification
Mar 03, 2026Deep learning models have proven to be highly effective in computer vision, with deep convolutional neural networks achieving impressive results across various computer vision tasks. However, these models rely heavily on large datasets to avoid overfitting. When a model learns features with either low or high variance, it can lead to underfitting or overfitting on the training data. Unfortunately, large-scale datasets may not be available in many domains, particularly for resource-limited languages such as Bengali. In this experiment, a series of tests were conducted in the field of image data augmentation as an approach to addressing the limited data problem for Bengali handwritten characters. The study also provides an in-depth analysis of the performance of different augmentation techniques. Data augmentation refers to a set of techniques applied to data to increase its size and diversity, making it more suitable for training deep learning models. The image augmentation techniques evaluated in this study include CLAHE, Random Rotation, Random Affine, Color Jitter, and their combinations. The study further explores the use of augmentation methods with a lightweight model such as EfficientViT. Among the different augmentation strategies, the combination of Random Affine and Color Jitter produced the best accuracy on the Ekush [1] and AIBangla [2] datasets, achieving accuracies of 97.48% and 97.57%, respectively. This combination outperformed all other individual and combined augmentation techniques. Overall, this analysis presents a thorough examination of the impact of image data augmentation in resource-scarce languages, particularly in the context of Bengali handwritten character recognition using lightweight models.
BornoViT: A Novel Efficient Vision Transformer for Bengali Handwritten Basic Characters Classification
Feb 28, 2026Handwritten character classification in the Bengali script is a significant challenge due to the complexity and variability of the characters. The models commonly used for classification are often computationally expensive and data-hungry, making them unsuitable for resource-limited languages such as Bengali. In this experiment, we propose a novel, efficient, and lightweight Vision Transformer model that effectively classifies Bengali handwritten basic characters and digits, addressing several shortcomings of traditional methods. The proposed solution utilizes a deep convolutional neural network (DCNN) in a more simplified manner compared to traditional DCNN architectures, with the aim of reducing computational burden. With only 0.65 million parameters, a model size of 0.62 MB, and 0.16 GFLOPs, our model, BornoViT, is significantly lighter than current state-of-the-art models, making it more suitable for resource-limited environments, which is essential for Bengali handwritten character classification. BornoViT was evaluated on the BanglaLekha Isolated dataset, achieving an accuracy of 95.77%, and demonstrating superior efficiency compared to existing state-of-the-art approaches. Furthermore, the model was evaluated on our self-collected dataset, Bornomala, consisting of approximately 222 samples from different age groups, where it achieved an accuracy of 91.51%.
Catastrophic Forgetting in LLMs: A Comparative Analysis Across Language Tasks
Apr 01, 2025



Large Language Models (LLMs) have significantly advanced Natural Language Processing (NLP), particularly in Natural Language Understanding (NLU) tasks. As we progress toward an agentic world where LLM-based agents autonomously handle specialized tasks, it becomes crucial for these models to adapt to new tasks without forgetting previously learned information - a challenge known as catastrophic forgetting. This study evaluates the continual fine-tuning of various open-source LLMs with different parameter sizes (specifically models under 10 billion parameters) on key NLU tasks from the GLUE benchmark, including SST-2, MRPC, CoLA, and MNLI. By employing prompt engineering and task-specific adjustments, we assess and compare the models' abilities to retain prior knowledge while learning new tasks. Our results indicate that models such as Phi-3.5-mini exhibit minimal forgetting while maintaining strong learning capabilities, making them well-suited for continual learning environments. Additionally, models like Orca-2-7b and Qwen2.5-7B demonstrate impressive learning abilities and overall performance after fine-tuning. This work contributes to understanding catastrophic forgetting in LLMs and highlights prompting engineering to optimize model performance for continual learning scenarios.
BDA: Bangla Text Data Augmentation Framework
Dec 11, 2024



Data augmentation involves generating synthetic samples that resemble those in a given dataset. In resource-limited fields where high-quality data is scarce, augmentation plays a crucial role in increasing the volume of training data. This paper introduces a Bangla Text Data Augmentation (BDA) Framework that uses both pre-trained models and rule-based methods to create new variants of the text. A filtering process is included to ensure that the new text keeps the same meaning as the original while also adding variety in the words used. We conduct a comprehensive evaluation of the framework's effectiveness in Bangla text classification tasks. Our framework achieved significant improvement in F1 scores across five distinct datasets, delivering performance equivalent to models trained on 100\% of the data while utilizing only 50\% of the training dataset. Additionally, we explore the impact of data scarcity by progressively reducing the training data and augmenting it through BDA, resulting in notable F1 score enhancements. The study offers a thorough examination of BDA's performance, identifying key factors for optimal results and addressing its limitations through detailed analysis.
FaceAtt: Enhancing Image Captioning with Facial Attributes for Portrait Images
Sep 24, 2023
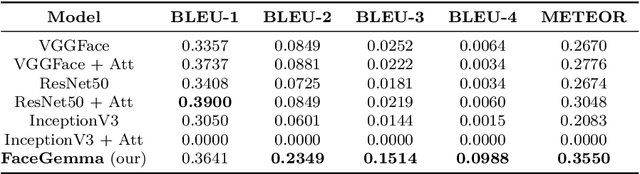

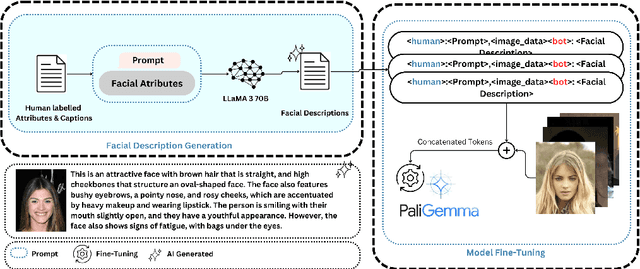
Automated image caption generation is a critical area of research that enhances accessibility and understanding of visual content for diverse audiences. In this study, we propose the FaceAtt model, a novel approach to attribute-focused image captioning that emphasizes the accurate depiction of facial attributes within images. FaceAtt automatically detects and describes a wide range of attributes, including emotions, expressions, pointed noses, fair skin tones, hair textures, attractiveness, and approximate age ranges. Leveraging deep learning techniques, we explore the impact of different image feature extraction methods on caption quality and evaluate our model's performance using metrics such as BLEU and METEOR. Our FaceAtt model leverages annotated attributes of portraits as supplementary prior knowledge for our portrait images before captioning. This innovative addition yields a subtle yet discernible enhancement in the resulting scores, exemplifying the potency of incorporating additional attribute vectors during training. Furthermore, our research contributes to the broader discourse on ethical considerations in automated captioning. This study sets the stage for future research in refining attribute-focused captioning techniques, with a focus on enhancing linguistic coherence, addressing biases, and accommodating diverse user needs.
BdSpell: A YOLO-based Real-time Finger Spelling System for Bangla Sign Language
Sep 24, 2023In the domain of Bangla Sign Language (BdSL) interpretation, prior approaches often imposed a burden on users, requiring them to spell words without hidden characters, which were subsequently corrected using Bangla grammar rules due to the missing classes in BdSL36 dataset. However, this method posed a challenge in accurately guessing the incorrect spelling of words. To address this limitation, we propose a novel real-time finger spelling system based on the YOLOv5 architecture. Our system employs specified rules and numerical classes as triggers to efficiently generate hidden and compound characters, eliminating the necessity for additional classes and significantly enhancing user convenience. Notably, our approach achieves character spelling in an impressive 1.32 seconds with a remarkable accuracy rate of 98\%. Furthermore, our YOLOv5 model, trained on 9147 images, demonstrates an exceptional mean Average Precision (mAP) of 96.4\%. These advancements represent a substantial progression in augmenting BdSL interpretation, promising increased inclusivity and accessibility for the linguistic minority. This innovative framework, characterized by compatibility with existing YOLO versions, stands as a transformative milestone in enhancing communication modalities and linguistic equity within the Bangla Sign Language community.