 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttResDU-Net: Medical Image Segmentation Using Attention-based Residual Double U-Net
Jun 25, 2023Manually inspecting polyps from a colonoscopy for colorectal cancer or performing a biopsy on skin lesions for skin cancer are time-consuming, laborious, and complex procedures. Automatic medical image segmentation aims to expedite this diagnosis process. However, numerous challenges exist due to significant variations in the appearance and sizes of objects with no distinct boundaries. This paper proposes an attention-based residual Double U-Net architecture (AttResDU-Net) that improves on the existing medical image segmentation networks. Inspired by the Double U-Net, this architecture incorporates attention gates on the skip connections and residual connections in the convolutional blocks. The attention gates allow the model to retain more relevant spatial information by suppressing irrelevant feature representation from the down-sampling path for which the model learns to focus on target regions of varying shapes and sizes. Moreover, the residual connections help to train deeper models by ensuring better gradient flow. We conducted experiments on three datasets: CVC Clinic-DB, ISIC 2018, and the 2018 Data Science Bowl datasets and achieved Dice Coefficient scores of 94.35%, 91.68% and 92.45% respectively. Our results suggest that AttResDU-Net can be facilitated as a reliable method for automatic medical image segmentation in practice.
End-to-End Natural Language Understanding Pipeline for Bangla Conversational Agents
Jul 15, 2021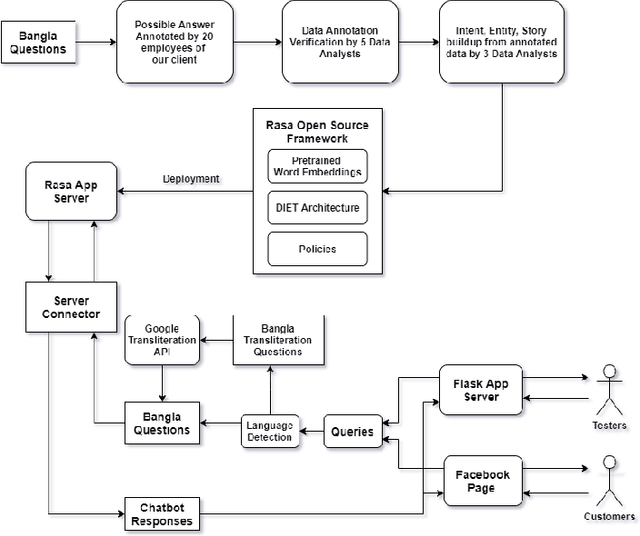
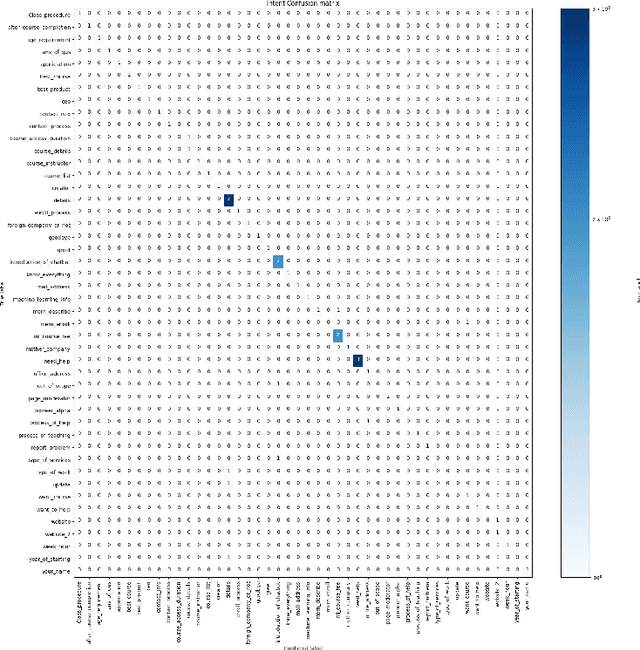
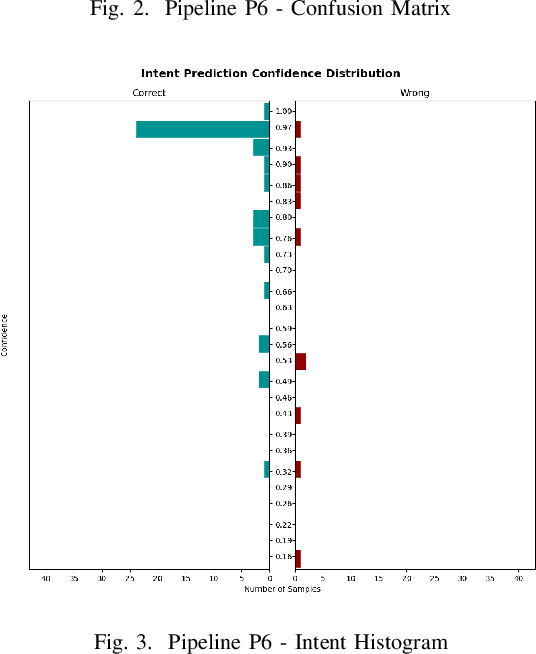
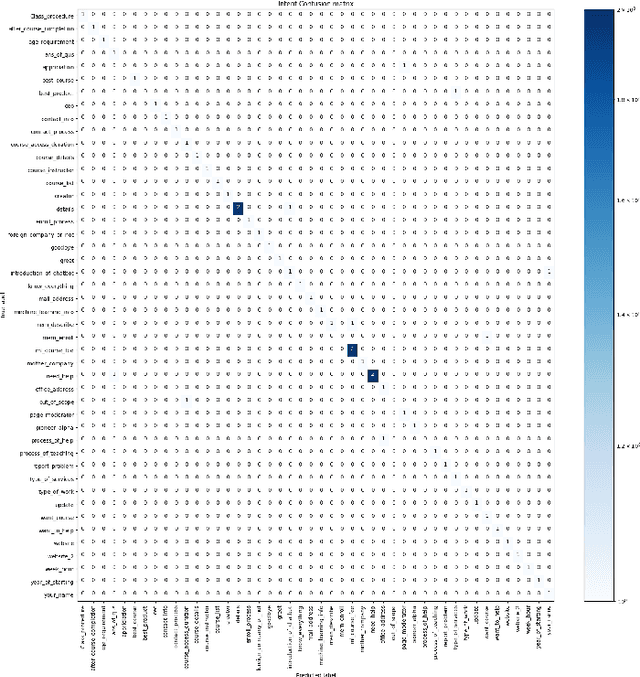
Chatbots are intelligent software built to be used as a replacement for human interaction. However, existing studies typically do not provide enough support for low-resource languages like Bangla. Moreover, due to the increasing popularity of social media, we can also see the rise of interactions in Bangla transliteration (mostly in English) among the native Bangla speakers. In this paper, we propose a novel approach to build a Bangla chatbot aimed to be used as a business assistant which can communicate in Bangla and Bangla Transliteration in English with high confidence consistently. Since annotated data was not available for this purpose, we had to work on the whole machine learning life cycle (data preparation, machine learning modeling, and model deployment) using Rasa Open Source Framework, fastText embeddings, Polyglot embeddings, Flask, and other systems as building blocks. While working with the skewed annotated dataset, we try out different setups and pipelines to evaluate which works best and provide possible reasoning behind the observed results. Finally, we present a pipeline for intent classification and entity extraction which achieves reasonable performance (accuracy: 83.02%, precision: 80.82%, recall: 83.02%, F1-score: 80%).