 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Natural Language Understanding Pipeline for Bangla Conversational Agents
Paper and Code
Jul 15, 2021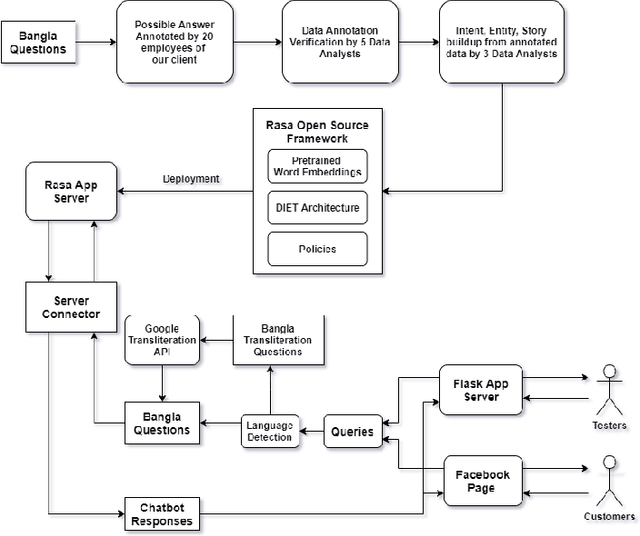
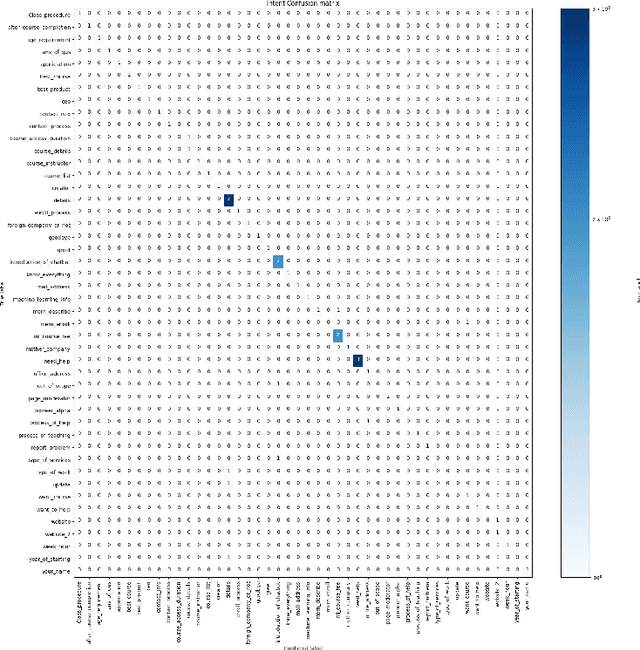
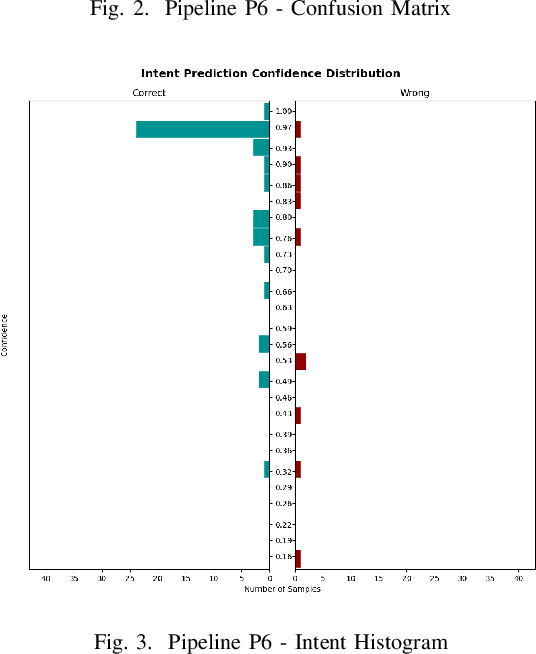
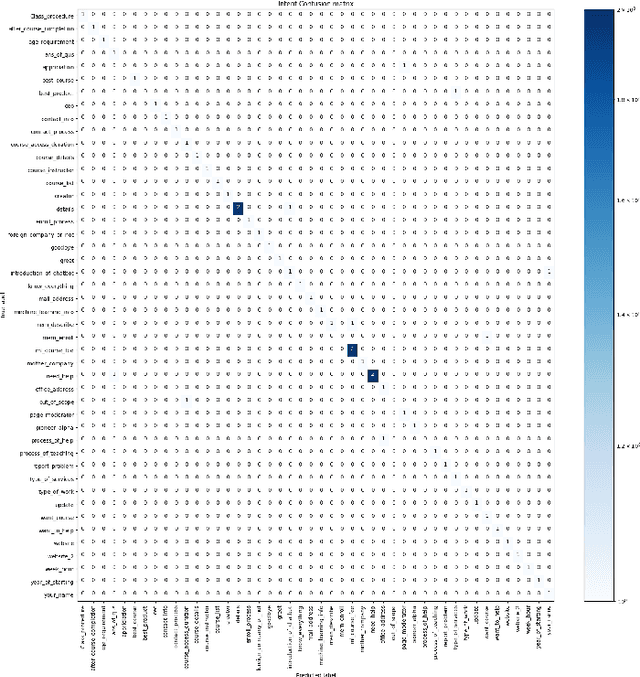
Chatbots are intelligent software built to be used as a replacement for human interaction. However, existing studies typically do not provide enough support for low-resource languages like Bangla. Moreover, due to the increasing popularity of social media, we can also see the rise of interactions in Bangla transliteration (mostly in English) among the native Bangla speakers. In this paper, we propose a novel approach to build a Bangla chatbot aimed to be used as a business assistant which can communicate in Bangla and Bangla Transliteration in English with high confidence consistently. Since annotated data was not available for this purpose, we had to work on the whole machine learning life cycle (data preparation, machine learning modeling, and model deployment) using Rasa Open Source Framework, fastText embeddings, Polyglot embeddings, Flask, and other systems as building blocks. While working with the skewed annotated dataset, we try out different setups and pipelines to evaluate which works best and provide possible reasoning behind the observed results. Finally, we present a pipeline for intent classification and entity extraction which achieves reasonable performance (accuracy: 83.02%, precision: 80.82%, recall: 83.02%, F1-score: 80%).