 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Analysis of YOLO-based Architectures for Vehicle Detection from Traffic Images in Bangladesh
Dec 24, 2022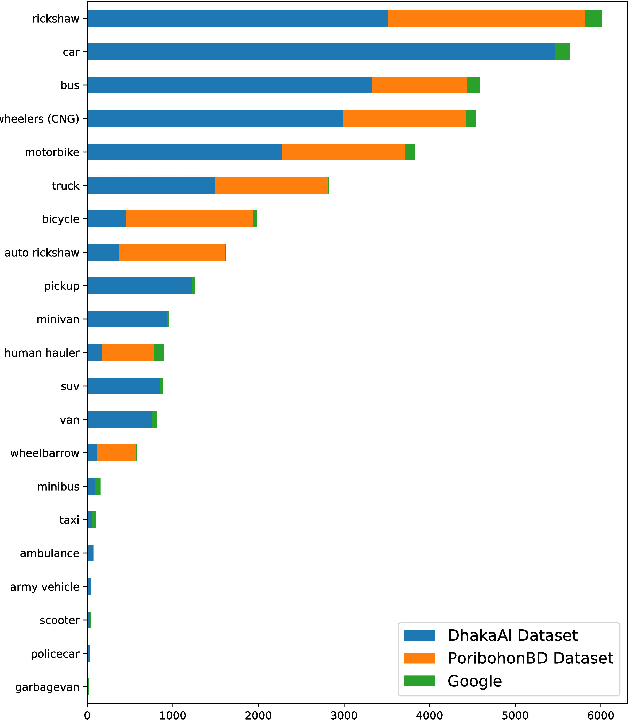
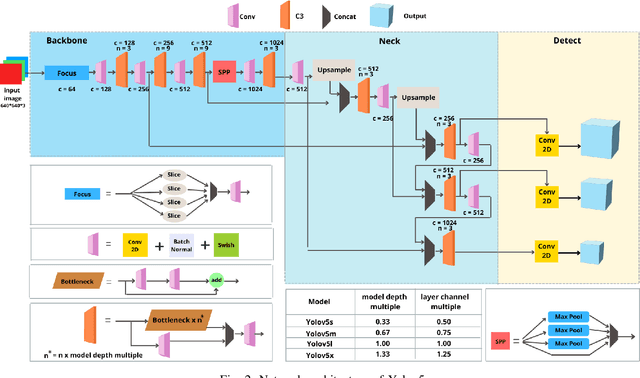
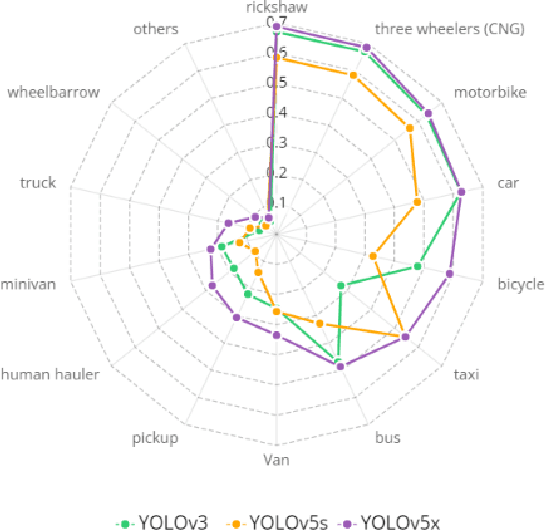

The task of locating and classifying different types of vehicles has become a vital element in numerous applications of automation and intelligent systems ranging from traffic surveillance to vehicle identification and many more. In recent times, Deep Learning models have been dominating the field of vehicle detection. Yet, Bangladeshi vehicle detection has remained a relatively unexplored area. One of the main goals of vehicle detection is its real-time application, where `You Only Look Once' (YOLO) models have proven to be the most effective architecture. In this work, intending to find the best-suited YOLO architecture for fast and accurate vehicle detection from traffic images in Bangladesh, we have conducted a performance analysis of different variants of the YOLO-based architectures such as YOLOV3, YOLOV5s, and YOLOV5x. The models were trained on a dataset containing 7390 images belonging to 21 types of vehicles comprising samples from the DhakaAI dataset, the Poribohon-BD dataset, and our self-collected images. After thorough quantitative and qualitative analysis, we found the YOLOV5x variant to be the best-suited model, performing better than YOLOv3 and YOLOv5s models respectively by 7 & 4 percent in mAP, and 12 & 8.5 percent in terms of Accuracy.
End-to-End Natural Language Understanding Pipeline for Bangla Conversational Agents
Jul 15, 2021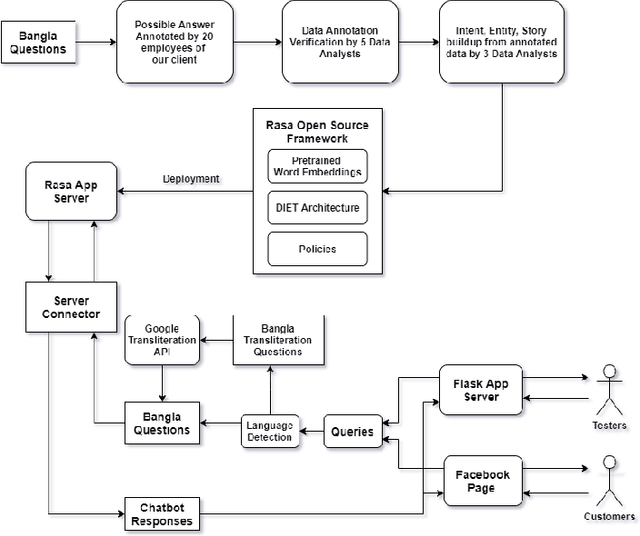
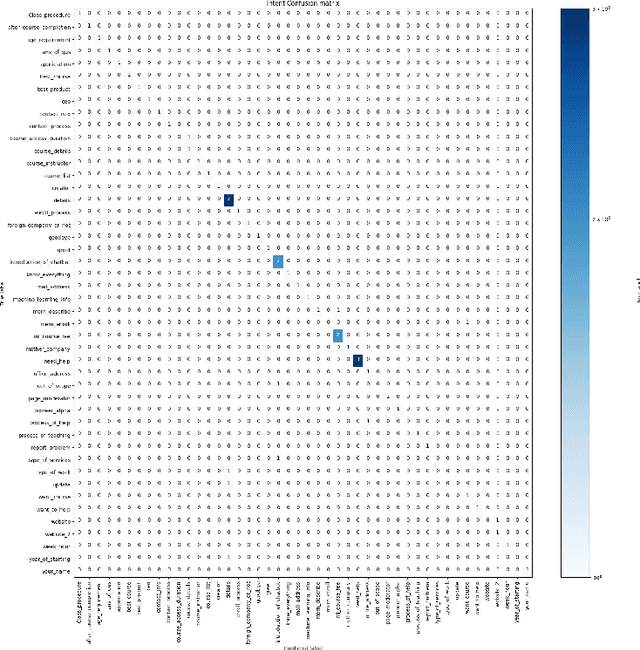
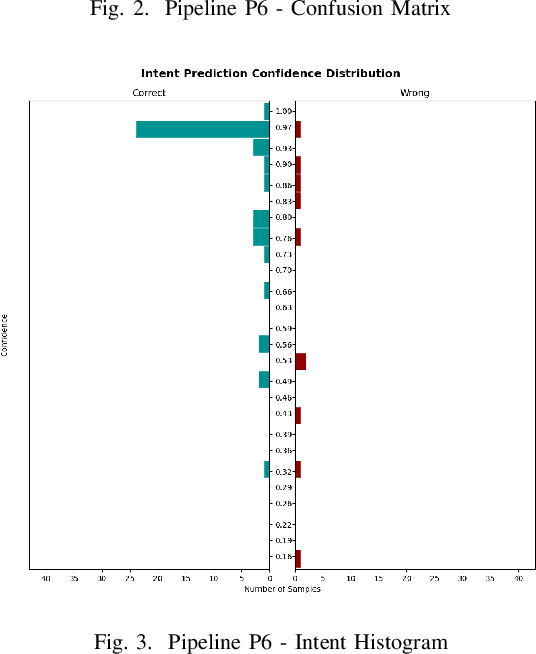
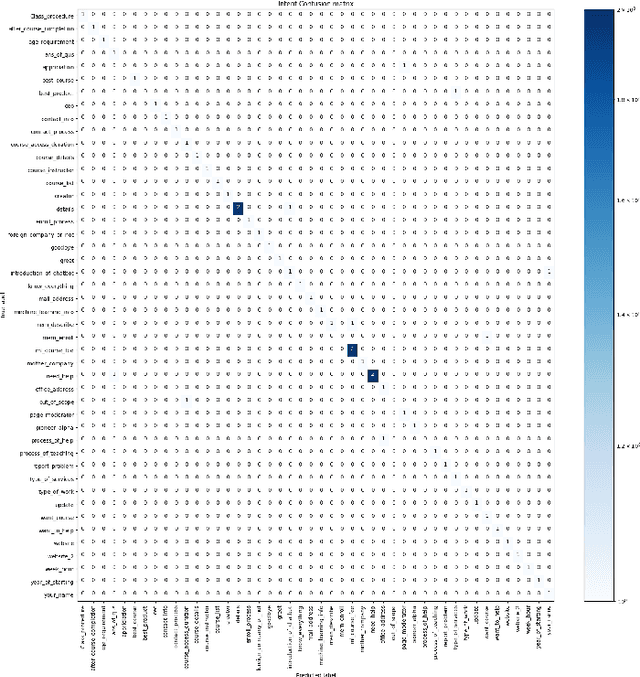
Chatbots are intelligent software built to be used as a replacement for human interaction. However, existing studies typically do not provide enough support for low-resource languages like Bangla. Moreover, due to the increasing popularity of social media, we can also see the rise of interactions in Bangla transliteration (mostly in English) among the native Bangla speakers. In this paper, we propose a novel approach to build a Bangla chatbot aimed to be used as a business assistant which can communicate in Bangla and Bangla Transliteration in English with high confidence consistently. Since annotated data was not available for this purpose, we had to work on the whole machine learning life cycle (data preparation, machine learning modeling, and model deployment) using Rasa Open Source Framework, fastText embeddings, Polyglot embeddings, Flask, and other systems as building blocks. While working with the skewed annotated dataset, we try out different setups and pipelines to evaluate which works best and provide possible reasoning behind the observed results. Finally, we present a pipeline for intent classification and entity extraction which achieves reasonable performance (accuracy: 83.02%, precision: 80.82%, recall: 83.02%, F1-score: 80%).