 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealth Text Simplification: An Annotated Corpus for Digestive Cancer Education and Novel Strategies for Reinforcement Learning
Jan 26, 2024
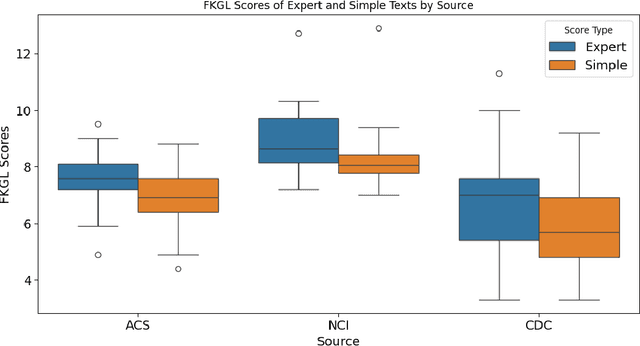
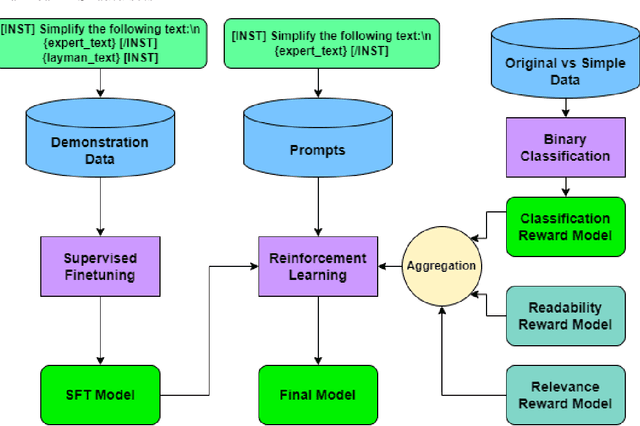
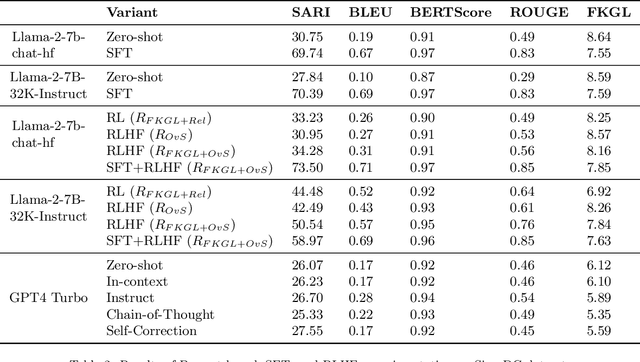
Objective: The reading level of health educational materials significantly influences information understandability and accessibility, particularly for minoritized populations. Many patient educational resources surpass the reading level and complexity of widely accepted standards. There is a critical need for high-performing text simplification models in health information to enhance dissemination and literacy. This need is particularly acute in cancer education, where effective prevention and screening education can substantially reduce morbidity and mortality. Methods: We introduce Simplified Digestive Cancer (SimpleDC), a parallel corpus of cancer education materials tailored for health text simplification research. Utilizing SimpleDC alongside the existing Med-EASi corpus, we explore Large Language Model (LLM)-based simplification methods, including fine-tuning, reinforcement learning (RL), reinforcement learning with human feedback (RLHF), domain adaptation, and prompt-based approaches. Our experimentation encompasses Llama 2 and GPT-4. A novel RLHF reward function is introduced, featuring a lightweight model adept at distinguishing between original and simplified texts, thereby enhancing the model's effectiveness with unlabeled data. Results: Fine-tuned Llama 2 models demonstrated high performance across various metrics. Our innovative RLHF reward function surpassed existing RL text simplification reward functions in effectiveness. The results underscore that RL/RLHF can augment fine-tuning, facilitating model training on unlabeled text and improving performance. Additionally, these methods effectively adapt out-of-domain text simplification models to targeted domains.