 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Retrieval-Augmented Generation vs. Long-Context Input for Clinical Reasoning over EHRs
Aug 20, 2025Electronic health records (EHRs) are long, noisy, and often redundant, posing a major challenge for the clinicians who must navigate them. Large language models (LLMs) offer a promising solution for extracting and reasoning over this unstructured text, but the length of clinical notes often exceeds even state-of-the-art models' extended context windows. Retrieval-augmented generation (RAG) offers an alternative by retrieving task-relevant passages from across the entire EHR, potentially reducing the amount of required input tokens. In this work, we propose three clinical tasks designed to be replicable across health systems with minimal effort: 1) extracting imaging procedures, 2) generating timelines of antibiotic use, and 3) identifying key diagnoses. Using EHRs from actual hospitalized patients, we test three state-of-the-art LLMs with varying amounts of provided context, using either targeted text retrieval or the most recent clinical notes. We find that RAG closely matches or exceeds the performance of using recent notes, and approaches the performance of using the models' full context while requiring drastically fewer input tokens. Our results suggest that RAG remains a competitive and efficient approach even as newer models become capable of handling increasingly longer amounts of text.
MoMA: A Mixture-of-Multimodal-Agents Architecture for Enhancing Clinical Prediction Modelling
Aug 07, 2025Multimodal electronic health record (EHR) data provide richer, complementary insights into patient health compared to single-modality data. However, effectively integrating diverse data modalities for clinical prediction modeling remains challenging due to the substantial data requirements. We introduce a novel architecture, Mixture-of-Multimodal-Agents (MoMA), designed to leverage multiple large language model (LLM) agents for clinical prediction tasks using multimodal EHR data. MoMA employs specialized LLM agents ("specialist agents") to convert non-textual modalities, such as medical images and laboratory results, into structured textual summaries. These summaries, together with clinical notes, are combined by another LLM ("aggregator agent") to generate a unified multimodal summary, which is then used by a third LLM ("predictor agent") to produce clinical predictions. Evaluating MoMA on three prediction tasks using real-world datasets with different modality combinations and prediction settings, MoMA outperforms current state-of-the-art methods, highlighting its enhanced accuracy and flexibility across various tasks.
An Information-Theoretic Perspective on Multi-LLM Uncertainty Estimation
Jul 09, 2025Large language models (LLMs) often behave inconsistently across inputs, indicating uncertainty and motivating the need for its quantification in high-stakes settings. Prior work on calibration and uncertainty quantification often focuses on individual models, overlooking the potential of model diversity. We hypothesize that LLMs make complementary predictions due to differences in training and the Zipfian nature of language, and that aggregating their outputs leads to more reliable uncertainty estimates. To leverage this, we propose MUSE (Multi-LLM Uncertainty via Subset Ensembles), a simple information-theoretic method that uses Jensen-Shannon Divergence to identify and aggregate well-calibrated subsets of LLMs. Experiments on binary prediction tasks demonstrate improved calibration and predictive performance compared to single-model and naive ensemble baselines.
Development and Validation of the Provider Documentation Summarization Quality Instrument for Large Language Models
Jan 15, 2025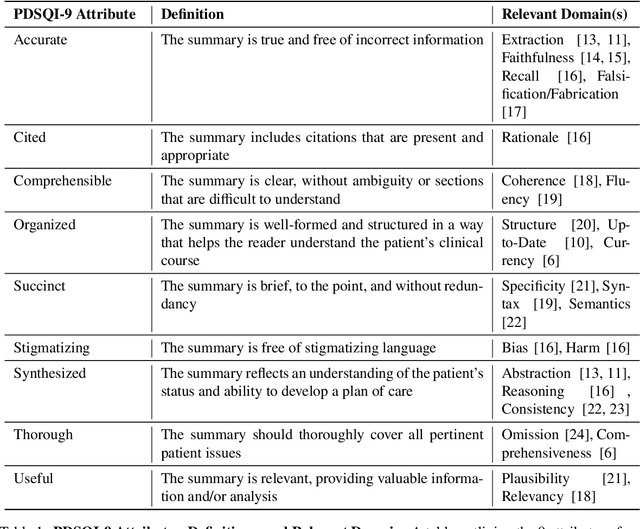
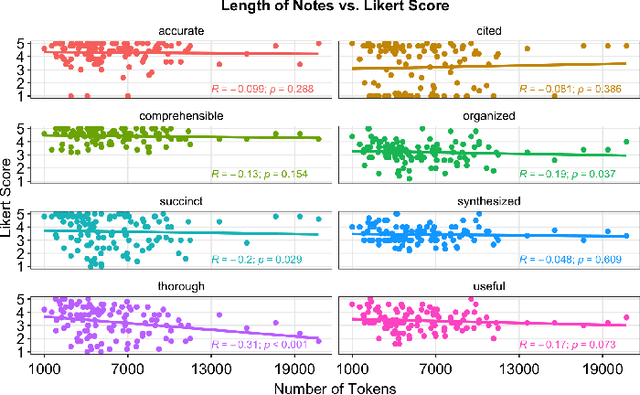
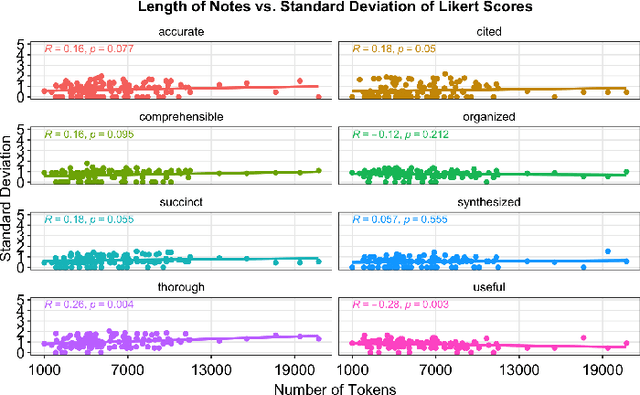
As Large Language Models (LLMs) are integrated into electronic health record (EHR) workflows, validated instruments are essential to evaluate their performance before implementation. Existing instruments for provider documentation quality are often unsuitable for the complexities of LLM-generated text and lack validation on real-world data. The Provider Documentation Summarization Quality Instrument (PDSQI-9) was developed to evaluate LLM-generated clinical summaries. Multi-document summaries were generated from real-world EHR data across multiple specialties using several LLMs (GPT-4o, Mixtral 8x7b, and Llama 3-8b). Validation included Pearson correlation for substantive validity, factor analysis and Cronbach's alpha for structural validity, inter-rater reliability (ICC and Krippendorff's alpha) for generalizability, a semi-Delphi process for content validity, and comparisons of high- versus low-quality summaries for discriminant validity. Seven physician raters evaluated 779 summaries and answered 8,329 questions, achieving over 80% power for inter-rater reliability. The PDSQI-9 demonstrated strong internal consistency (Cronbach's alpha = 0.879; 95% CI: 0.867-0.891) and high inter-rater reliability (ICC = 0.867; 95% CI: 0.867-0.868), supporting structural validity and generalizability. Factor analysis identified a 4-factor model explaining 58% of the variance, representing organization, clarity, accuracy, and utility. Substantive validity was supported by correlations between note length and scores for Succinct (rho = -0.200, p = 0.029) and Organized (rho = -0.190, p = 0.037). Discriminant validity distinguished high- from low-quality summaries (p < 0.001). The PDSQI-9 demonstrates robust construct validity, supporting its use in clinical practice to evaluate LLM-generated summaries and facilitate safer integration of LLMs into healthcare workflows.
Position Paper On Diagnostic Uncertainty Estimation from Large Language Models: Next-Word Probability Is Not Pre-test Probability
Nov 07, 2024Large language models (LLMs) are being explored for diagnostic decision support, yet their ability to estimate pre-test probabilities, vital for clinical decision-making, remains limited. This study evaluates two LLMs, Mistral-7B and Llama3-70B, using structured electronic health record data on three diagnosis tasks. We examined three current methods of extracting LLM probability estimations and revealed their limitations. We aim to highlight the need for improved techniques in LLM confidence estimation.
When Raw Data Prevails: Are Large Language Model Embeddings Effective in Numerical Data Representation for Medical Machine Learning Applications?
Aug 15, 2024



The introduction of Large Language Models (LLMs) has advanced data representation and analysis, bringing significant progress in their use for medical questions and answering. Despite these advancements, integrating tabular data, especially numerical data pivotal in clinical contexts, into LLM paradigms has not been thoroughly explored. In this study, we examine the effectiveness of vector representations from last hidden states of LLMs for medical diagnostics and prognostics using electronic health record (EHR) data. We compare the performance of these embeddings with that of raw numerical EHR data when used as feature inputs to traditional machine learning (ML) algorithms that excel at tabular data learning, such as eXtreme Gradient Boosting. We focus on instruction-tuned LLMs in a zero-shot setting to represent abnormal physiological data and evaluating their utilities as feature extractors to enhance ML classifiers for predicting diagnoses, length of stay, and mortality. Furthermore, we examine prompt engineering techniques on zero-shot and few-shot LLM embeddings to measure their impact comprehensively. Although findings suggest the raw data features still prevails in medical ML tasks, zero-shot LLM embeddings demonstrate competitive results, suggesting a promising avenue for future research in medical applications.
Improving Clinical NLP Performance through Language Model-Generated Synthetic Clinical Data
Mar 28, 2024
Generative models have been showing potential for producing data in mass. This study explores the enhancement of clinical natural language processing performance by utilizing synthetic data generated from advanced language models. Promising results show feasible applications in such a high-stakes domain.
The impact of using an AI chatbot to respond to patient messages
Oct 26, 2023
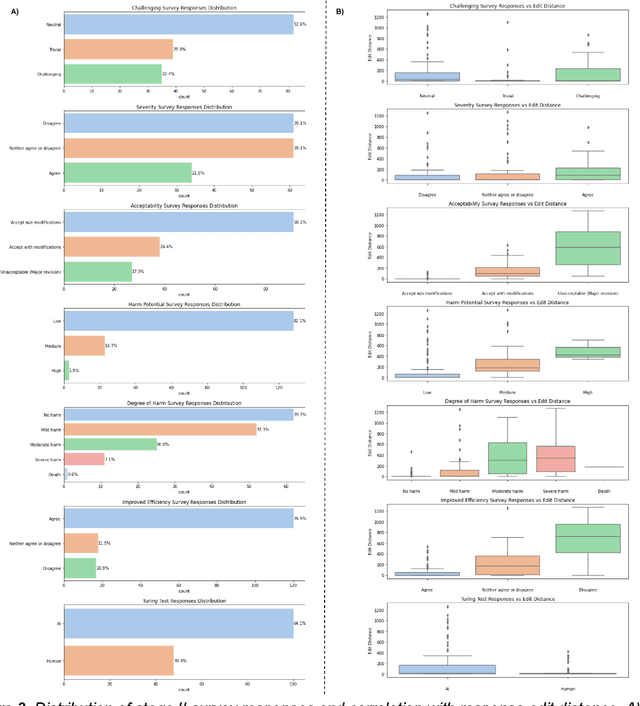
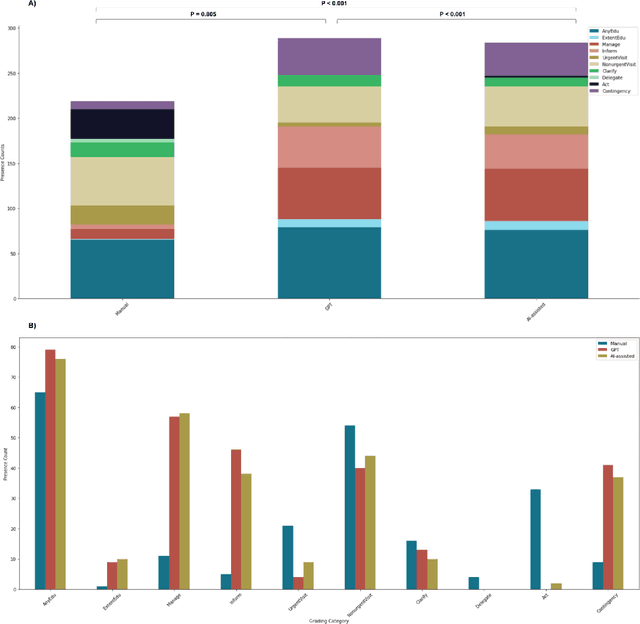
Documentation burden is a major contributor to clinician burnout, which is rising nationally and is an urgent threat to our ability to care for patients. Artificial intelligence (AI) chatbots, such as ChatGPT, could reduce clinician burden by assisting with documentation. Although many hospitals are actively integrating such systems into electronic medical record systems, AI chatbots utility and impact on clinical decision-making have not been studied for this intended use. We are the first to examine the utility of large language models in assisting clinicians draft responses to patient questions. In our two-stage cross-sectional study, 6 oncologists responded to 100 realistic synthetic cancer patient scenarios and portal messages developed to reflect common medical situations, first manually, then with AI assistance. We find AI-assisted responses were longer, less readable, but provided acceptable drafts without edits 58% of time. AI assistance improved efficiency 77% of time, with low harm risk (82% safe). However, 7.7% unedited AI responses could severely harm. In 31% cases, physicians thought AI drafts were human-written. AI assistance led to more patient education recommendations, fewer clinical actions than manual responses. Results show promise for AI to improve clinician efficiency and patient care through assisting documentation, if used judiciously. Monitoring model outputs and human-AI interaction remains crucial for safe implementation.
Leveraging A Medical Knowledge Graph into Large Language Models for Diagnosis Prediction
Aug 28, 2023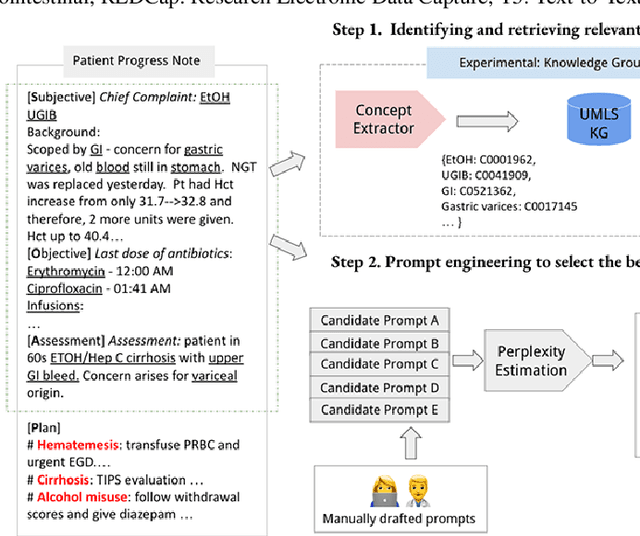

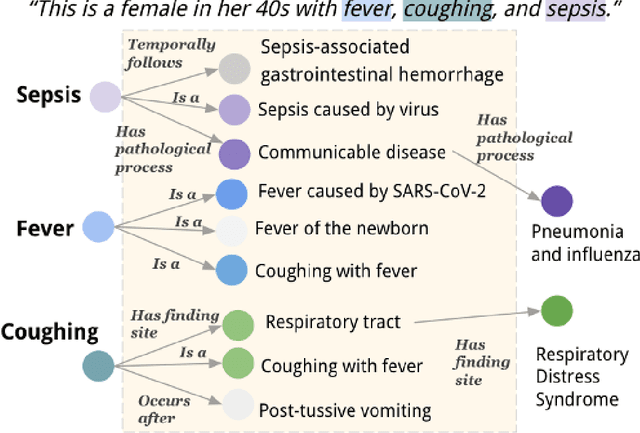
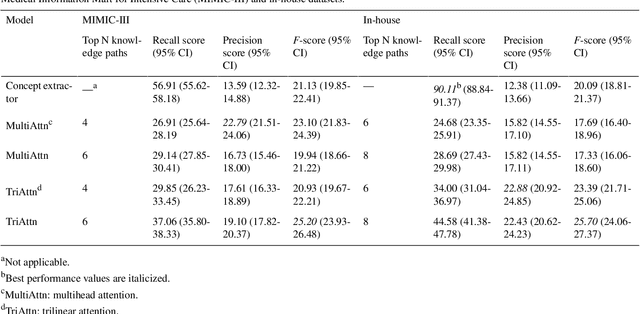
Electronic Health Records (EHRs) and routine documentation practices play a vital role in patients' daily care, providing a holistic record of health, diagnoses, and treatment. However, complex and verbose EHR narratives overload healthcare providers, risking diagnostic inaccuracies. While Large Language Models (LLMs) have showcased their potential in diverse language tasks, their application in the healthcare arena needs to ensure the minimization of diagnostic errors and the prevention of patient harm. In this paper, we outline an innovative approach for augmenting the proficiency of LLMs in the realm of automated diagnosis generation, achieved through the incorporation of a medical knowledge graph (KG) and a novel graph model: Dr.Knows, inspired by the clinical diagnostic reasoning process. We derive the KG from the National Library of Medicine's Unified Medical Language System (UMLS), a robust repository of biomedical knowledge. Our method negates the need for pre-training and instead leverages the KG as an auxiliary instrument aiding in the interpretation and summarization of complex medical concepts. Using real-world hospital datasets, our experimental results demonstrate that the proposed approach of combining LLMs with KG has the potential to improve the accuracy of automated diagnosis generation. More importantly, our approach offers an explainable diagnostic pathway, edging us closer to the realization of AI-augmented diagnostic decision support systems.
Multi-Task Training with In-Domain Language Models for Diagnostic Reasoning
Jun 13, 2023Generative artificial intelligence (AI) is a promising direction for augmenting clinical diagnostic decision support and reducing diagnostic errors, a leading contributor to medical errors. To further the development of clinical AI systems, the Diagnostic Reasoning Benchmark (DR.BENCH) was introduced as a comprehensive generative AI framework, comprised of six tasks representing key components in clinical reasoning. We present a comparative analysis of in-domain versus out-of-domain language models as well as multi-task versus single task training with a focus on the problem summarization task in DR.BENCH (Gao et al., 2023). We demonstrate that a multi-task, clinically trained language model outperforms its general domain counterpart by a large margin, establishing a new state-of-the-art performance, with a ROUGE-L score of 28.55. This research underscores the value of domain-specific training for optimizing clinical diagnostic reasoning tasks.