 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoMA: A Mixture-of-Multimodal-Agents Architecture for Enhancing Clinical Prediction Modelling
Aug 07, 2025Multimodal electronic health record (EHR) data provide richer, complementary insights into patient health compared to single-modality data. However, effectively integrating diverse data modalities for clinical prediction modeling remains challenging due to the substantial data requirements. We introduce a novel architecture, Mixture-of-Multimodal-Agents (MoMA), designed to leverage multiple large language model (LLM) agents for clinical prediction tasks using multimodal EHR data. MoMA employs specialized LLM agents ("specialist agents") to convert non-textual modalities, such as medical images and laboratory results, into structured textual summaries. These summaries, together with clinical notes, are combined by another LLM ("aggregator agent") to generate a unified multimodal summary, which is then used by a third LLM ("predictor agent") to produce clinical predictions. Evaluating MoMA on three prediction tasks using real-world datasets with different modality combinations and prediction settings, MoMA outperforms current state-of-the-art methods, highlighting its enhanced accuracy and flexibility across various tasks.
Leveraging A Medical Knowledge Graph into Large Language Models for Diagnosis Prediction
Aug 28, 2023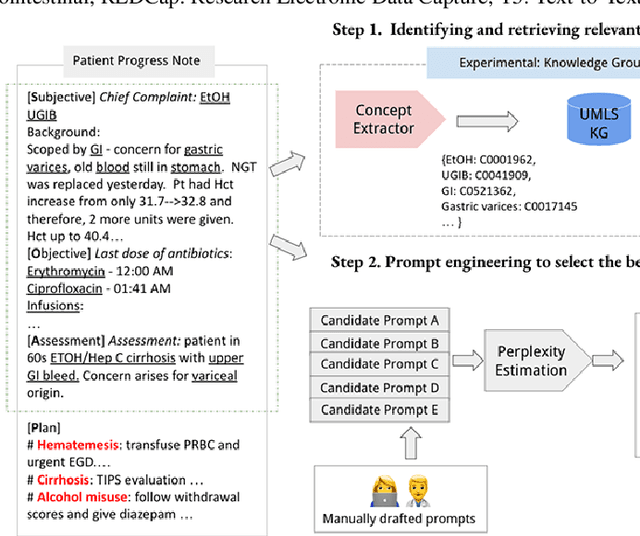

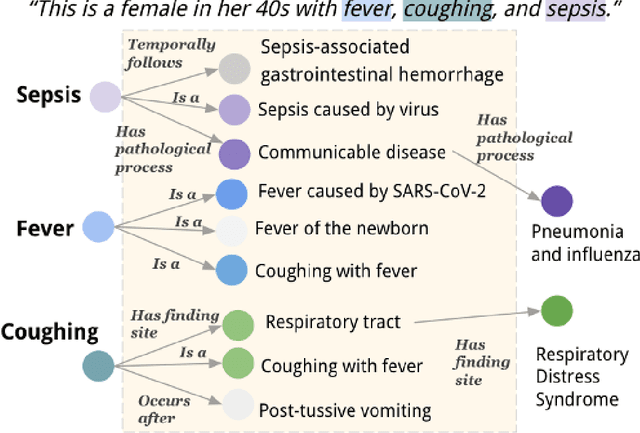
Electronic Health Records (EHRs) and routine documentation practices play a vital role in patients' daily care, providing a holistic record of health, diagnoses, and treatment. However, complex and verbose EHR narratives overload healthcare providers, risking diagnostic inaccuracies. While Large Language Models (LLMs) have showcased their potential in diverse language tasks, their application in the healthcare arena needs to ensure the minimization of diagnostic errors and the prevention of patient harm. In this paper, we outline an innovative approach for augmenting the proficiency of LLMs in the realm of automated diagnosis generation, achieved through the incorporation of a medical knowledge graph (KG) and a novel graph model: Dr.Knows, inspired by the clinical diagnostic reasoning process. We derive the KG from the National Library of Medicine's Unified Medical Language System (UMLS), a robust repository of biomedical knowledge. Our method negates the need for pre-training and instead leverages the KG as an auxiliary instrument aiding in the interpretation and summarization of complex medical concepts. Using real-world hospital datasets, our experimental results demonstrate that the proposed approach of combining LLMs with KG has the potential to improve the accuracy of automated diagnosis generation. More importantly, our approach offers an explainable diagnostic pathway, edging us closer to the realization of AI-augmented diagnostic decision support systems.
DR.BENCH: Diagnostic Reasoning Benchmark for Clinical Natural Language Processing
Sep 29, 2022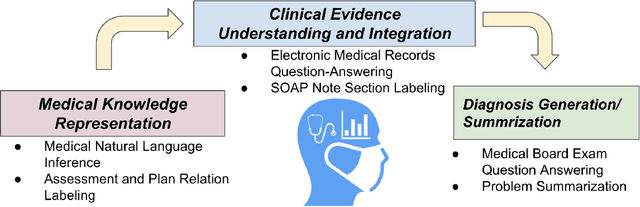
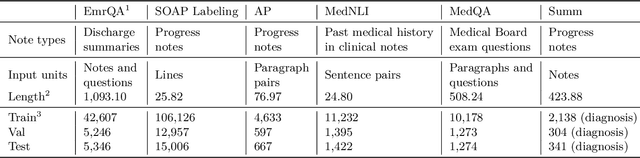
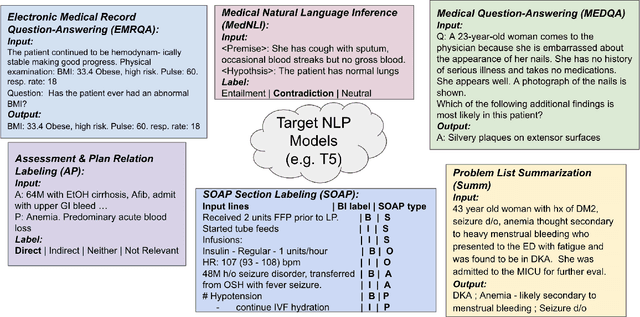
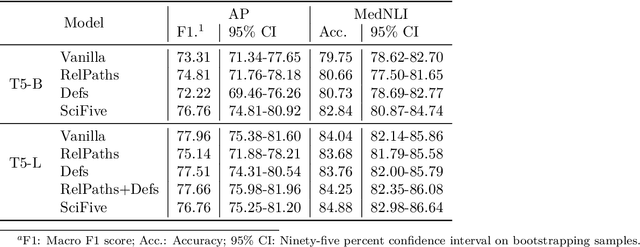
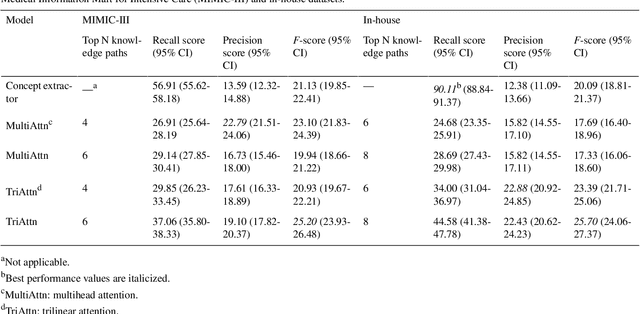
The meaningful use of electronic health records (EHR) continues to progress in the digital era with clinical decision support systems augmented by artificial intelligence. A priority in improving provider experience is to overcome information overload and reduce the cognitive burden so fewer medical errors and cognitive biases are introduced during patient care. One major type of medical error is diagnostic error due to systematic or predictable errors in judgment that rely on heuristics. The potential for clinical natural language processing (cNLP) to model diagnostic reasoning in humans with forward reasoning from data to diagnosis and potentially reduce the cognitive burden and medical error has not been investigated. Existing tasks to advance the science in cNLP have largely focused on information extraction and named entity recognition through classification tasks. We introduce a novel suite of tasks coined as Diagnostic Reasoning Benchmarks, DR.BENCH, as a new benchmark for developing and evaluating cNLP models with clinical diagnostic reasoning ability. The suite includes six tasks from ten publicly available datasets addressing clinical text understanding, medical knowledge reasoning, and diagnosis generation. DR.BENCH is the first clinical suite of tasks designed to be a natural language generation framework to evaluate pre-trained language models. Experiments with state-of-the-art pre-trained generative language models using large general domain models and models that were continually trained on a medical corpus demonstrate opportunities for improvement when evaluated in DR. BENCH. We share DR. BENCH as a publicly available GitLab repository with a systematic approach to load and evaluate models for the cNLP community.