 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR.BENCH: Diagnostic Reasoning Benchmark for Clinical Natural Language Processing
Paper and Code
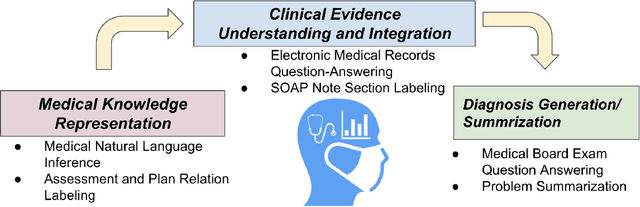
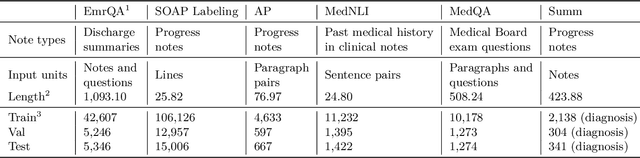
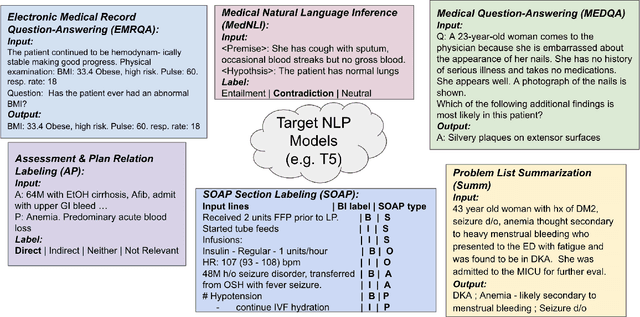
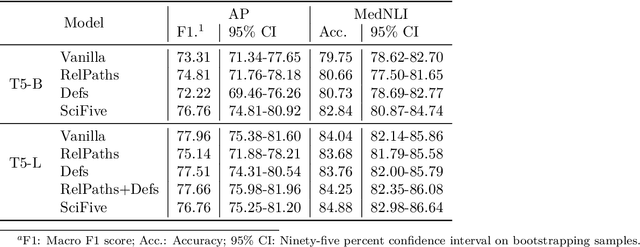
The meaningful use of electronic health records (EHR) continues to progress in the digital era with clinical decision support systems augmented by artificial intelligence. A priority in improving provider experience is to overcome information overload and reduce the cognitive burden so fewer medical errors and cognitive biases are introduced during patient care. One major type of medical error is diagnostic error due to systematic or predictable errors in judgment that rely on heuristics. The potential for clinical natural language processing (cNLP) to model diagnostic reasoning in humans with forward reasoning from data to diagnosis and potentially reduce the cognitive burden and medical error has not been investigated. Existing tasks to advance the science in cNLP have largely focused on information extraction and named entity recognition through classification tasks. We introduce a novel suite of tasks coined as Diagnostic Reasoning Benchmarks, DR.BENCH, as a new benchmark for developing and evaluating cNLP models with clinical diagnostic reasoning ability. The suite includes six tasks from ten publicly available datasets addressing clinical text understanding, medical knowledge reasoning, and diagnosis generation. DR.BENCH is the first clinical suite of tasks designed to be a natural language generation framework to evaluate pre-trained language models. Experiments with state-of-the-art pre-trained generative language models using large general domain models and models that were continually trained on a medical corpus demonstrate opportunities for improvement when evaluated in DR. BENCH. We share DR. BENCH as a publicly available GitLab repository with a systematic approach to load and evaluate models for the cNLP community.