 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Artificial Intelligence Models for Health Recognition Using Face Photographs (FAHR-Face)
Jun 17, 2025Background: Facial appearance offers a noninvasive window into health. We built FAHR-Face, a foundation model trained on >40 million facial images and fine-tuned it for two distinct tasks: biological age estimation (FAHR-FaceAge) and survival risk prediction (FAHR-FaceSurvival). Methods: FAHR-FaceAge underwent a two-stage, age-balanced fine-tuning on 749,935 public images; FAHR-FaceSurvival was fine-tuned on 34,389 photos of cancer patients. Model robustness (cosmetic surgery, makeup, pose, lighting) and independence (saliency mapping) was tested extensively. Both models were clinically tested in two independent cancer patient datasets with survival analyzed by multivariable Cox models and adjusted for clinical prognostic factors. Findings: For age estimation, FAHR-FaceAge had the lowest mean absolute error of 5.1 years on public datasets, outperforming benchmark models and maintaining accuracy across the full human lifespan. In cancer patients, FAHR-FaceAge outperformed a prior facial age estimation model in survival prognostication. FAHR-FaceSurvival demonstrated robust prediction of mortality, and the highest-risk quartile had more than triple the mortality of the lowest (adjusted hazard ratio 3.22; P<0.001). These findings were validated in the independent cohort and both models showed generalizability across age, sex, race and cancer subgroups. The two algorithms provided distinct, complementary prognostic information; saliency mapping revealed each model relied on distinct facial regions. The combination of FAHR-FaceAge and FAHR-FaceSurvival improved prognostic accuracy. Interpretation: A single foundation model can generate inexpensive, scalable facial biomarkers that capture both biological ageing and disease-related mortality risk. The foundation model enabled effective training using relatively small clinical datasets.
TissUnet: Improved Extracranial Tissue and Cranium Segmentation for Children through Adulthood
Jun 06, 2025

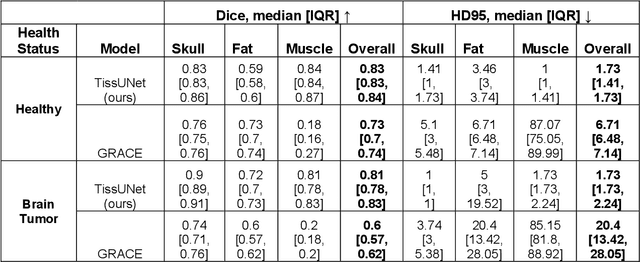

Extracranial tissues visible on brain magnetic resonance imaging (MRI) may hold significant value for characterizing health conditions and clinical decision-making, yet they are rarely quantified. Current tools have not been widely validated, particularly in settings of developing brains or underlying pathology. We present TissUnet, a deep learning model that segments skull bone, subcutaneous fat, and muscle from routine three-dimensional T1-weighted MRI, with or without contrast enhancement. The model was trained on 155 paired MRI-computed tomography (CT) scans and validated across nine datasets covering a wide age range and including individuals with brain tumors. In comparison to AI-CT-derived labels from 37 MRI-CT pairs, TissUnet achieved a median Dice coefficient of 0.79 [IQR: 0.77-0.81] in a healthy adult cohort. In a second validation using expert manual annotations, median Dice was 0.83 [IQR: 0.83-0.84] in healthy individuals and 0.81 [IQR: 0.78-0.83] in tumor cases, outperforming previous state-of-the-art method. Acceptability testing resulted in an 89% acceptance rate after adjudication by a tie-breaker(N=108 MRIs), and TissUnet demonstrated excellent performance in the blinded comparative review (N=45 MRIs), including both healthy and tumor cases in pediatric populations. TissUnet enables fast, accurate, and reproducible segmentation of extracranial tissues, supporting large-scale studies on craniofacial morphology, treatment effects, and cardiometabolic risk using standard brain T1w MRI.
Vision Foundation Models for Computed Tomography
Jan 15, 2025Foundation models (FMs) have shown transformative potential in radiology by performing diverse, complex tasks across imaging modalities. Here, we developed CT-FM, a large-scale 3D image-based pre-trained model designed explicitly for various radiological tasks. CT-FM was pre-trained using 148,000 computed tomography (CT) scans from the Imaging Data Commons through label-agnostic contrastive learning. We evaluated CT-FM across four categories of tasks, namely, whole-body and tumor segmentation, head CT triage, medical image retrieval, and semantic understanding, showing superior performance against state-of-the-art models. Beyond quantitative success, CT-FM demonstrated the ability to cluster regions anatomically and identify similar anatomical and structural concepts across scans. Furthermore, it remained robust across test-retest settings and indicated reasonable salient regions attached to its embeddings. This study demonstrates the value of large-scale medical imaging foundation models and by open-sourcing the model weights, code, and data, aims to support more adaptable, reliable, and interpretable AI solutions in radiology.
BraTS-PEDs: Results of the Multi-Consortium International Pediatric Brain Tumor Segmentation Challenge 2023
Jul 11, 2024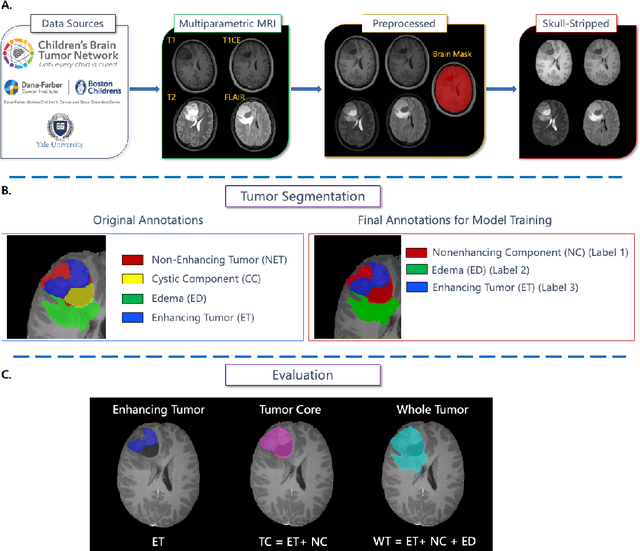

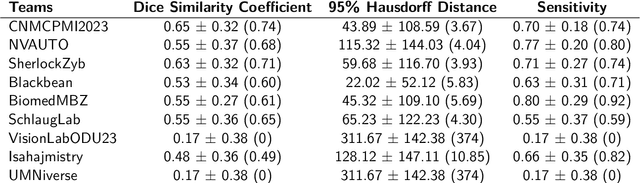
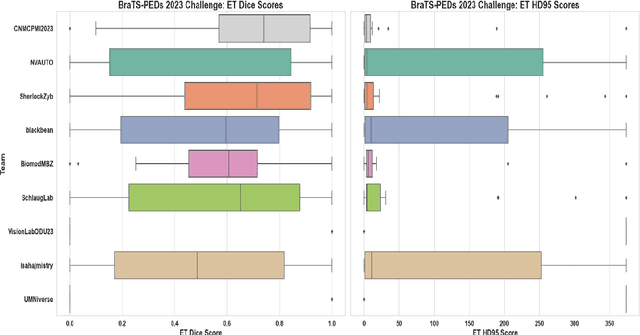
Pediatric central nervous system tumors are the leading cause of cancer-related deaths in children. The five-year survival rate for high-grade glioma in children is less than 20%. The development of new treatments is dependent upon multi-institutional collaborative clinical trials requiring reproducible and accurate centralized response assessment. We present the results of the BraTS-PEDs 2023 challenge, the first Brain Tumor Segmentation (BraTS) challenge focused on pediatric brain tumors. This challenge utilized data acquired from multiple international consortia dedicated to pediatric neuro-oncology and clinical trials. BraTS-PEDs 2023 aimed to evaluate volumetric segmentation algorithms for pediatric brain gliomas from magnetic resonance imaging using standardized quantitative performance evaluation metrics employed across the BraTS 2023 challenges. The top-performing AI approaches for pediatric tumor analysis included ensembles of nnU-Net and Swin UNETR, Auto3DSeg, or nnU-Net with a self-supervised framework. The BraTSPEDs 2023 challenge fostered collaboration between clinicians (neuro-oncologists, neuroradiologists) and AI/imaging scientists, promoting faster data sharing and the development of automated volumetric analysis techniques. These advancements could significantly benefit clinical trials and improve the care of children with brain tumors.
Magnetic resonance delta radiomics to track radiation response in lung tumors receiving stereotactic MRI-guided radiotherapy
Feb 23, 2024



Introduction: Lung cancer is a leading cause of cancer-related mortality, and stereotactic body radiotherapy (SBRT) has become a standard treatment for early-stage lung cancer. However, the heterogeneous response to radiation at the tumor level poses challenges. Currently, standardized dosage regimens lack adaptation based on individual patient or tumor characteristics. Thus, we explore the potential of delta radiomics from on-treatment magnetic resonance (MR) imaging to track radiation dose response, inform personalized radiotherapy dosing, and predict outcomes. Methods: A retrospective study of 47 MR-guided lung SBRT treatments for 39 patients was conducted. Radiomic features were extracted using Pyradiomics, and stability was evaluated temporally and spatially. Delta radiomics were correlated with radiation dose delivery and assessed for associations with tumor control and survival with Cox regressions. Results: Among 107 features, 49 demonstrated temporal stability, and 57 showed spatial stability. Fifteen stable and non-collinear features were analyzed. Median Skewness and surface to volume ratio decreased with radiation dose fraction delivery, while coarseness and 90th percentile values increased. Skewness had the largest relative median absolute changes (22%-45%) per fraction from baseline and was associated with locoregional failure (p=0.012) by analysis of covariance. Skewness, Elongation, and Flatness were significantly associated with local recurrence-free survival, while tumor diameter and volume were not. Conclusions: Our study establishes the feasibility and stability of delta radiomics analysis for MR-guided lung SBRT. Findings suggest that MR delta radiomics can capture short-term radiographic manifestations of intra-tumoral radiation effect.
The impact of using an AI chatbot to respond to patient messages
Oct 26, 2023
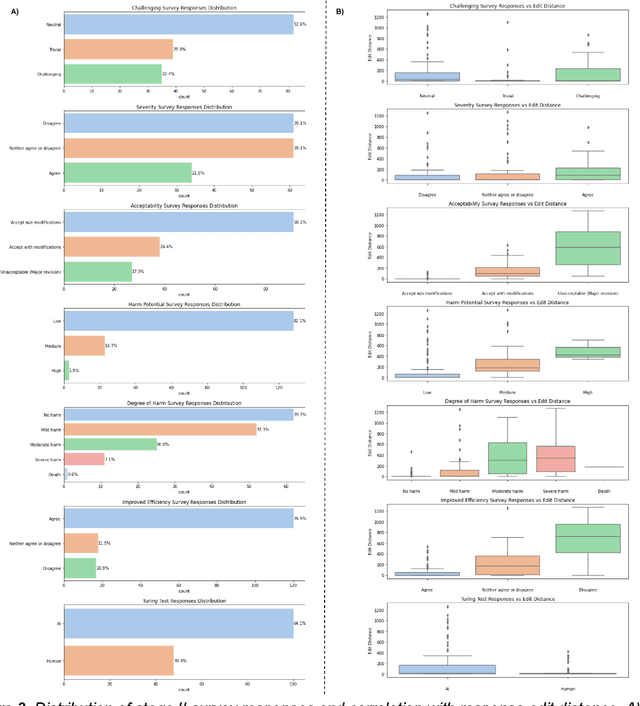
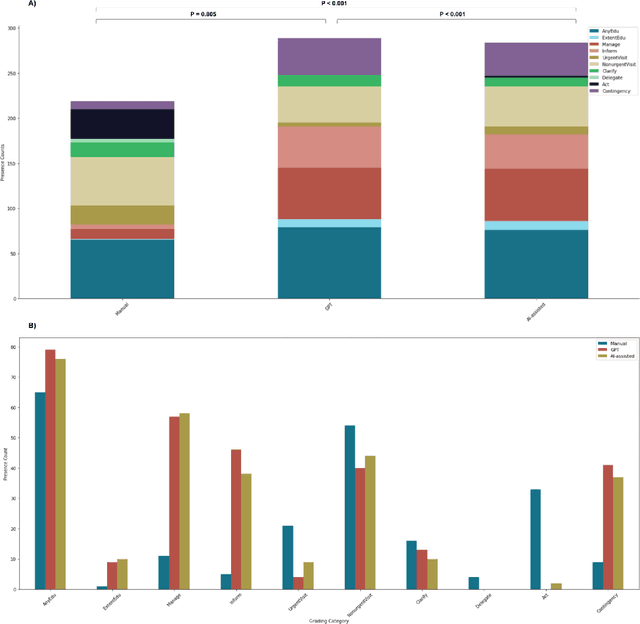
Documentation burden is a major contributor to clinician burnout, which is rising nationally and is an urgent threat to our ability to care for patients. Artificial intelligence (AI) chatbots, such as ChatGPT, could reduce clinician burden by assisting with documentation. Although many hospitals are actively integrating such systems into electronic medical record systems, AI chatbots utility and impact on clinical decision-making have not been studied for this intended use. We are the first to examine the utility of large language models in assisting clinicians draft responses to patient questions. In our two-stage cross-sectional study, 6 oncologists responded to 100 realistic synthetic cancer patient scenarios and portal messages developed to reflect common medical situations, first manually, then with AI assistance. We find AI-assisted responses were longer, less readable, but provided acceptable drafts without edits 58% of time. AI assistance improved efficiency 77% of time, with low harm risk (82% safe). However, 7.7% unedited AI responses could severely harm. In 31% cases, physicians thought AI drafts were human-written. AI assistance led to more patient education recommendations, fewer clinical actions than manual responses. Results show promise for AI to improve clinician efficiency and patient care through assisting documentation, if used judiciously. Monitoring model outputs and human-AI interaction remains crucial for safe implementation.
Deep learning-based detection of intravenous contrast in computed tomography scans
Oct 19, 2021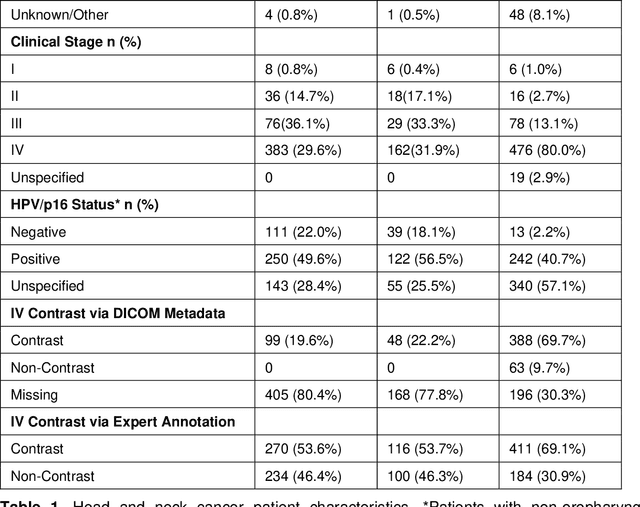
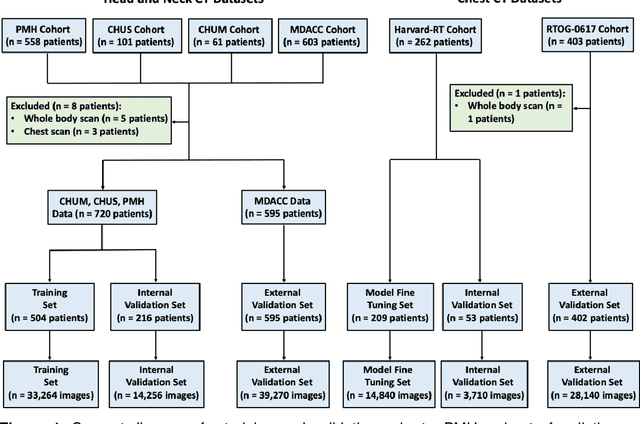
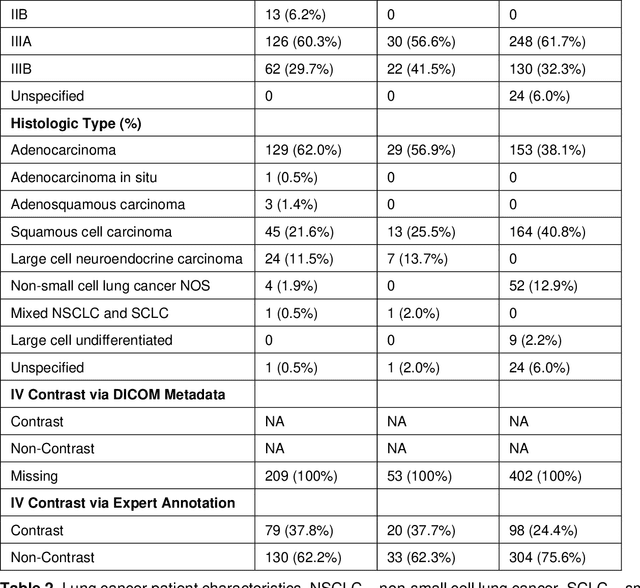
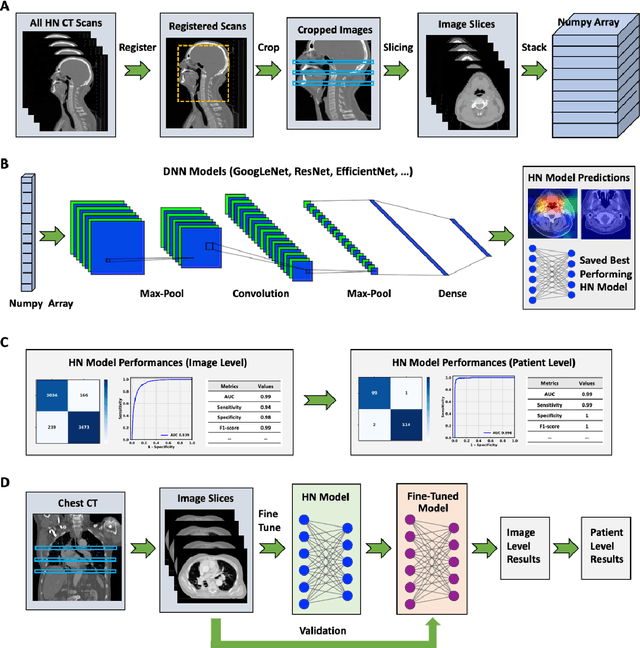
Purpose: Identifying intravenous (IV) contrast use within CT scans is a key component of data curation for model development and testing. Currently, IV contrast is poorly documented in imaging metadata and necessitates manual correction and annotation by clinician experts, presenting a major barrier to imaging analyses and algorithm deployment. We sought to develop and validate a convolutional neural network (CNN)-based deep learning (DL) platform to identify IV contrast within CT scans. Methods: For model development and evaluation, we used independent datasets of CT scans of head, neck (HN) and lung cancer patients, totaling 133,480 axial 2D scan slices from 1,979 CT scans manually annotated for contrast presence by clinical experts. Five different DL models were adopted and trained in HN training datasets for slice-level contrast detection. Model performances were evaluated on a hold-out set and on an independent validation set from another institution. DL models was then fine-tuned on chest CT data and externally validated on a separate chest CT dataset. Results: Initial DICOM metadata tags for IV contrast were missing or erroneous in 1,496 scans (75.6%). The EfficientNetB4-based model showed the best overall detection performance. For HN scans, AUC was 0.996 in the internal validation set (n = 216) and 1.0 in the external validation set (n = 595). The fine-tuned model on chest CTs yielded an AUC: 1.0 for the internal validation set (n = 53), and AUC: 0.980 for the external validation set (n = 402). Conclusion: The DL model could accurately detect IV contrast in both HN and chest CT scans with near-perfect performance.