 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAST-CKT: Chaos-Aware Spatio-Temporal and Cross-City Knowledge Transfer for Traffic Flow Prediction
Feb 04, 2026Traffic prediction in data-scarce, cross-city settings is challenging due to complex nonlinear dynamics and domain shifts. Existing methods often fail to capture traffic's inherent chaotic nature for effective few-shot learning. We propose CAST-CKT, a novel Chaos-Aware Spatio-Temporal and Cross-City Knowledge Transfer framework. It employs an efficient chaotic analyser to quantify traffic predictability regimes, driving several key innovations: chaos-aware attention for regime-adaptive temporal modelling; adaptive topology learning for dynamic spatial dependencies; and chaotic consistency-based cross-city alignment for knowledge transfer. The framework also provides horizon-specific predictions with uncertainty quantification. Theoretical analysis shows improved generalisation bounds. Extensive experiments on four benchmarks in cross-city few-shot settings show CAST-CKT outperforms state-of-the-art methods by significant margins in MAE and RMSE, while offering interpretable regime analysis. Code is available at https://github.com/afofanah/CAST-CKT.
FaceTracer: Unveiling Source Identities from Swapped Face Images and Videos for Fraud Prevention
Dec 11, 2024



Face-swapping techniques have advanced rapidly with the evolution of deep learning, leading to widespread use and growing concerns about potential misuse, especially in cases of fraud. While many efforts have focused on detecting swapped face images or videos, these methods are insufficient for tracing the malicious users behind fraudulent activities. Intrusive watermark-based approaches also fail to trace unmarked identities, limiting their practical utility. To address these challenges, we introduce FaceTracer, the first non-intrusive framework specifically designed to trace the identity of the source person from swapped face images or videos. Specifically, FaceTracer leverages a disentanglement module that effectively suppresses identity information related to the target person while isolating the identity features of the source person. This allows us to extract robust identity information that can directly link the swapped face back to the original individual, aiding in uncovering the actors behind fraudulent activities. Extensive experiments demonstrate FaceTracer's effectiveness across various face-swapping techniques, successfully identifying the source person in swapped content and enabling the tracing of malicious actors involved in fraudulent activities. Additionally, FaceTracer shows strong transferability to unseen face-swapping methods including commercial applications and robustness against transmission distortions and adaptive attacks.
M2GNN: Metapath and Multi-interest Aggregated Graph Neural Network for Tag-based Cross-domain Recommendation
Apr 16, 2023Cross-domain recommendation (CDR) is an effective way to alleviate the data sparsity problem. Content-based CDR is one of the most promising branches since most kinds of products can be described by a piece of text, especially when cold-start users or items have few interactions. However, two vital issues are still under-explored: (1) From the content modeling perspective, sufficient long-text descriptions are usually scarce in a real recommender system, more often the light-weight textual features, such as a few keywords or tags, are more accessible, which is improperly modeled by existing methods. (2) From the CDR perspective, not all inter-domain interests are helpful to infer intra-domain interests. Caused by domain-specific features, there are part of signals benefiting for recommendation in the source domain but harmful for that in the target domain. Therefore, how to distill useful interests is crucial. To tackle the above two problems, we propose a metapath and multi-interest aggregated graph neural network (M2GNN). Specifically, to model the tag-based contents, we construct a heterogeneous information network to hold the semantic relatedness between users, items, and tags in all domains. The metapath schema is predefined according to domain-specific knowledge, with one metapath for one domain. User representations are learned by GNN with a hierarchical aggregation framework, where the intra-metapath aggregation firstly filters out trivial tags and the inter-metapath aggregation further filters out useless interests. Offline experiments and online A/B tests demonstrate that M2GNN achieves significant improvements over the state-of-the-art methods and current industrial recommender system in Dianping, respectively. Further analysis shows that M2GNN offers an interpretable recommendation.
Fully Automated Deep Learning-enabled Detection for Hepatic Steatosis on Computed Tomography: A Multicenter International Validation Study
Nov 06, 2022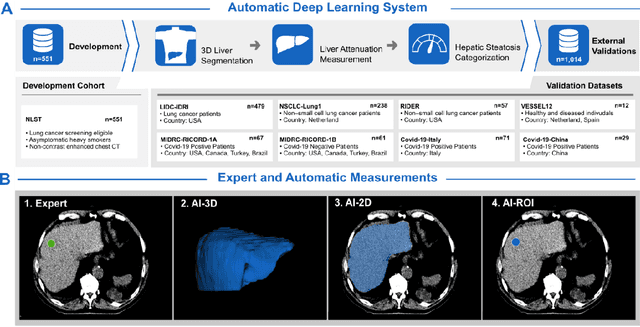

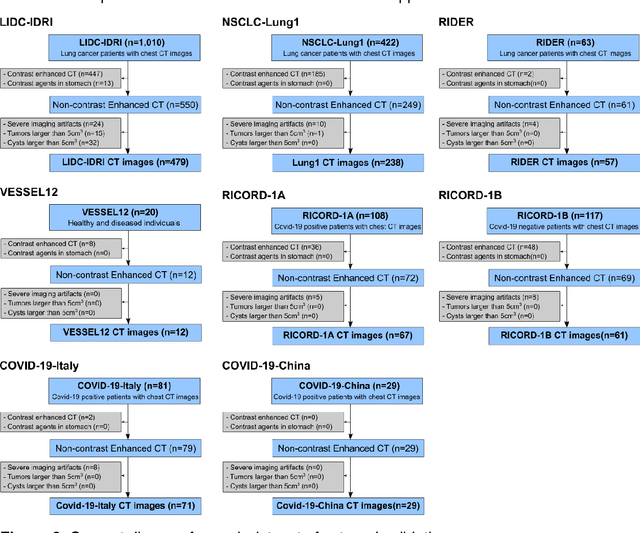

Despite high global prevalence of hepatic steatosis, no automated diagnostics demonstrated generalizability in detecting steatosis on multiple international datasets. Traditionally, hepatic steatosis detection relies on clinicians selecting the region of interest (ROI) on computed tomography (CT) to measure liver attenuation. ROI selection demands time and expertise, and therefore is not routinely performed in populations. To automate the process, we validated an existing artificial intelligence (AI) system for 3D liver segmentation and used it to purpose a novel method: AI-ROI, which could automatically select the ROI for attenuation measurements. AI segmentation and AI-ROI method were evaluated on 1,014 non-contrast enhanced chest CT images from eight international datasets: LIDC-IDRI, NSCLC-Lung1, RIDER, VESSEL12, RICORD-1A, RICORD-1B, COVID-19-Italy, and COVID-19-China. AI segmentation achieved a mean dice coefficient of 0.957. Attenuations measured by AI-ROI showed no significant differences (p = 0.545) and a reduction of 71% time compared to expert measurements. The area under the curve (AUC) of the steatosis classification of AI-ROI is 0.921 (95% CI: 0.883 - 0.959). If performed as a routine screening method, our AI protocol could potentially allow early non-invasive, non-pharmacological preventative interventions for hepatic steatosis. 1,014 expert-annotated liver segmentations of patients with hepatic steatosis annotations can be downloaded here: https://drive.google.com/drive/folders/1-g_zJeAaZXYXGqL1OeF6pUjr6KB0igJX.
Deep learning-based detection of intravenous contrast in computed tomography scans
Oct 19, 2021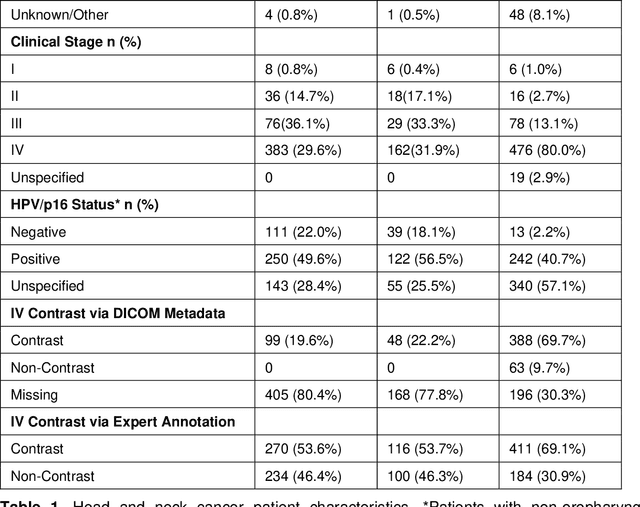
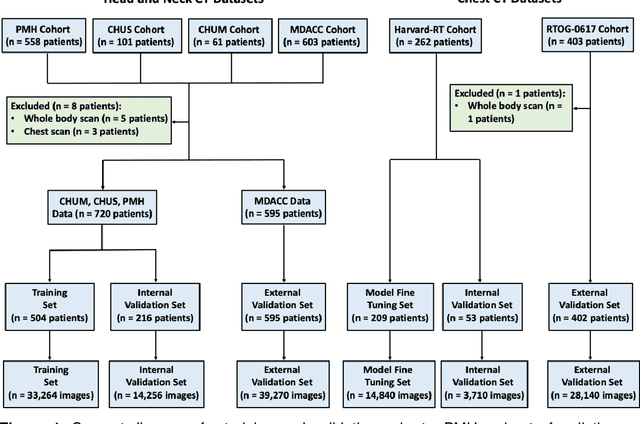
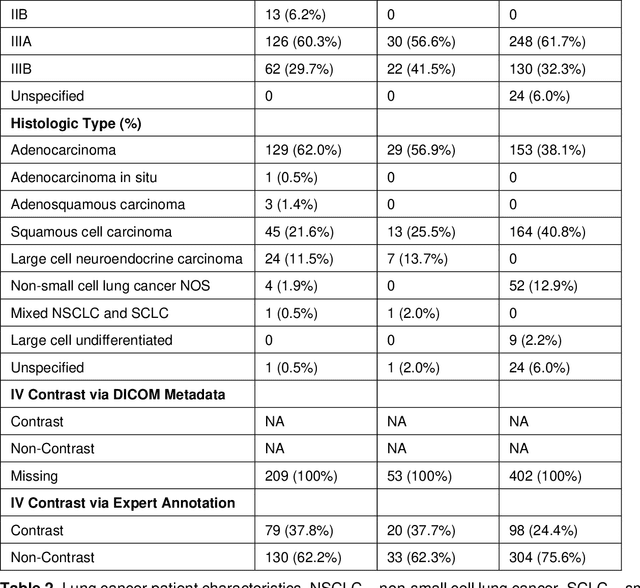
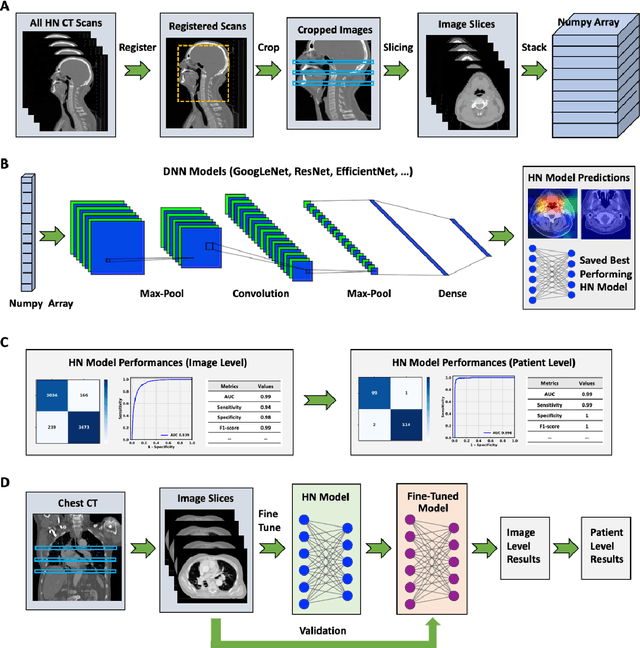
Purpose: Identifying intravenous (IV) contrast use within CT scans is a key component of data curation for model development and testing. Currently, IV contrast is poorly documented in imaging metadata and necessitates manual correction and annotation by clinician experts, presenting a major barrier to imaging analyses and algorithm deployment. We sought to develop and validate a convolutional neural network (CNN)-based deep learning (DL) platform to identify IV contrast within CT scans. Methods: For model development and evaluation, we used independent datasets of CT scans of head, neck (HN) and lung cancer patients, totaling 133,480 axial 2D scan slices from 1,979 CT scans manually annotated for contrast presence by clinical experts. Five different DL models were adopted and trained in HN training datasets for slice-level contrast detection. Model performances were evaluated on a hold-out set and on an independent validation set from another institution. DL models was then fine-tuned on chest CT data and externally validated on a separate chest CT dataset. Results: Initial DICOM metadata tags for IV contrast were missing or erroneous in 1,496 scans (75.6%). The EfficientNetB4-based model showed the best overall detection performance. For HN scans, AUC was 0.996 in the internal validation set (n = 216) and 1.0 in the external validation set (n = 595). The fine-tuned model on chest CTs yielded an AUC: 1.0 for the internal validation set (n = 53), and AUC: 0.980 for the external validation set (n = 402). Conclusion: The DL model could accurately detect IV contrast in both HN and chest CT scans with near-perfect performance.