 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceTracer: Unveiling Source Identities from Swapped Face Images and Videos for Fraud Prevention
Dec 11, 2024



Face-swapping techniques have advanced rapidly with the evolution of deep learning, leading to widespread use and growing concerns about potential misuse, especially in cases of fraud. While many efforts have focused on detecting swapped face images or videos, these methods are insufficient for tracing the malicious users behind fraudulent activities. Intrusive watermark-based approaches also fail to trace unmarked identities, limiting their practical utility. To address these challenges, we introduce FaceTracer, the first non-intrusive framework specifically designed to trace the identity of the source person from swapped face images or videos. Specifically, FaceTracer leverages a disentanglement module that effectively suppresses identity information related to the target person while isolating the identity features of the source person. This allows us to extract robust identity information that can directly link the swapped face back to the original individual, aiding in uncovering the actors behind fraudulent activities. Extensive experiments demonstrate FaceTracer's effectiveness across various face-swapping techniques, successfully identifying the source person in swapped content and enabling the tracing of malicious actors involved in fraudulent activities. Additionally, FaceTracer shows strong transferability to unseen face-swapping methods including commercial applications and robustness against transmission distortions and adaptive attacks.
Rank-based No-reference Quality Assessment for Face Swapping
Jun 04, 2024



Face swapping has become a prominent research area in computer vision and image processing due to rapid technological advancements. The metric of measuring the quality in most face swapping methods relies on several distances between the manipulated images and the source image, or the target image, i.e., there are suitable known reference face images. Therefore, there is still a gap in accurately assessing the quality of face interchange in reference-free scenarios. In this study, we present a novel no-reference image quality assessment (NR-IQA) method specifically designed for face swapping, addressing this issue by constructing a comprehensive large-scale dataset, implementing a method for ranking image quality based on multiple facial attributes, and incorporating a Siamese network based on interpretable qualitative comparisons. Our model demonstrates the state-of-the-art performance in the quality assessment of swapped faces, providing coarse- and fine-grained. Enhanced by this metric, an improved face-swapping model achieved a more advanced level with respect to expressions and poses. Extensive experiments confirm the superiority of our method over existing general no-reference image quality assessment metrics and the latest metric of facial image quality assessment, making it well suited for evaluating face swapping images in real-world scenarios.
Aesthetic Visual Question Answering of Photographs
Aug 10, 2022


Aesthetic assessment of images can be categorized into two main forms: numerical assessment and language assessment. Aesthetics caption of photographs is the only task of aesthetic language assessment that has been addressed. In this paper, we propose a new task of aesthetic language assessment: aesthetic visual question and answering (AVQA) of images. If we give a question of images aesthetics, model can predict the answer. We use images from \textit{www.flickr.com}. The objective QA pairs are generated by the proposed aesthetic attributes analysis algorithms. Moreover, we introduce subjective QA pairs that are converted from aesthetic numerical labels and sentiment analysis from large-scale pre-train models. We build the first aesthetic visual question answering dataset, AesVQA, that contains 72,168 high-quality images and 324,756 pairs of aesthetic questions. Two methods for adjusting the data distribution have been proposed and proved to improve the accuracy of existing models. This is the first work that both addresses the task of aesthetic VQA and introduces subjectiveness into VQA tasks. The experimental results reveal that our methods outperform other VQA models on this new task.
Aesthetic Attributes Assessment of Images with AMANv2 and DPC-CaptionsV2
Aug 09, 2022

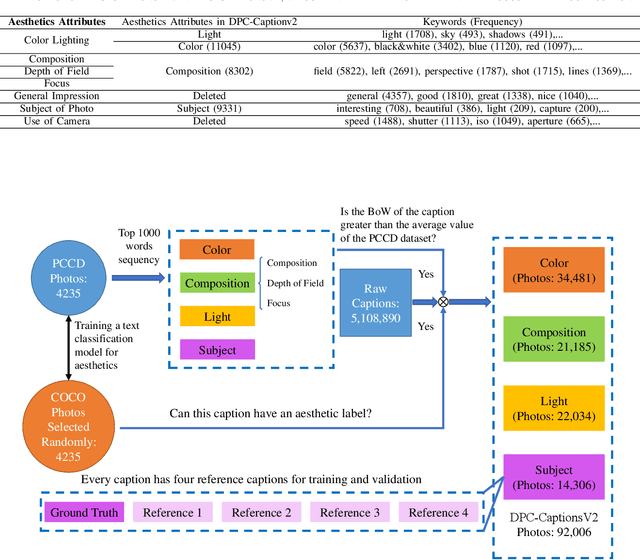

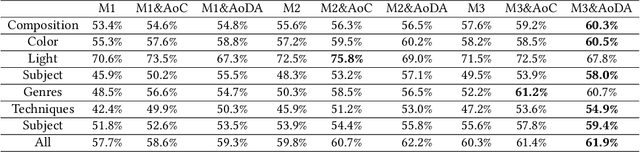
Image aesthetic quality assessment is popular during the last decade. Besides numerical assessment, nature language assessment (aesthetic captioning) has been proposed to describe the generally aesthetic impression of an image. In this paper, we propose aesthetic attribute assessment, which is the aesthetic attributes captioning, i.e., to assess the aesthetic attributes such as composition, lighting usage and color arrangement. It is a non-trivial task to label the comments of aesthetic attributes, which limit the scale of the corresponding datasets. We construct a novel dataset, named DPC-CaptionsV2, by a semi-automatic way. The knowledge is transferred from a small-scale dataset with full annotations to large-scale professional comments from a photography website. Images of DPC-CaptionsV2 contain comments up to 4 aesthetic attributes: composition, lighting, color, and subject. Then, we propose a new version of Aesthetic Multi-Attributes Networks (AMANv2) based on the BUTD model and the VLPSA model. AMANv2 fuses features of a mixture of small-scale PCCD dataset with full annotations and large-scale DPCCaptionsV2 dataset with full annotations. The experimental results of DPCCaptionsV2 show that our method can predict the comments on 4 aesthetic attributes, which are closer to aesthetic topics than those produced by the previous AMAN model. Through the evaluation criteria of image captioning, the specially designed AMANv2 model is better to the CNN-LSTM model and the AMAN model.
A Deep Drift-Diffusion Model for Image Aesthetic Score Distribution Prediction
Oct 15, 2020



The task of aesthetic quality assessment is complicated due to its subjectivity. In recent years, the target representation of image aesthetic quality has changed from a one-dimensional binary classification label or numerical score to a multi-dimensional score distribution. According to current methods, the ground truth score distributions are straightforwardly regressed. However, the subjectivity of aesthetics is not taken into account, that is to say, the psychological processes of human beings are not taken into consideration, which limits the performance of the task. In this paper, we propose a Deep Drift-Diffusion (DDD) model inspired by psychologists to predict aesthetic score distribution from images. The DDD model can describe the psychological process of aesthetic perception instead of traditional modeling of the results of assessment. We use deep convolution neural networks to regress the parameters of the drift-diffusion model. The experimental results in large scale aesthetic image datasets reveal that our novel DDD model is simple but efficient, which outperforms the state-of-the-art methods in aesthetic score distribution prediction. Besides, different psychological processes can also be predicted by our model.
Aesthetic Attributes Assessment of Images
Jul 29, 2019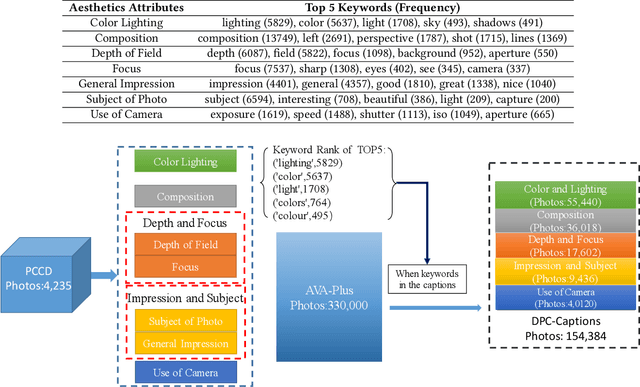



Image aesthetic quality assessment has been a relatively hot topic during the last decade. Most recently, comments type assessment (aesthetic captions) has been proposed to describe the general aesthetic impression of an image using text. In this paper, we propose Aesthetic Attributes Assessment of Images, which means the aesthetic attributes captioning. This is a new formula of image aesthetic assessment, which predicts aesthetic attributes captions together with the aesthetic score of each attribute. We introduce a new dataset named \emph{DPC-Captions} which contains comments of up to 5 aesthetic attributes of one image through knowledge transfer from a full-annotated small-scale dataset. Then, we propose Aesthetic Multi-Attribute Network (AMAN), which is trained on a mixture of fully-annotated small-scale PCCD dataset and weakly-annotated large-scale DPC-Captions dataset. Our AMAN makes full use of transfer learning and attention model in a single framework. The experimental results on our DPC-Captions and PCCD dataset reveal that our method can predict captions of 5 aesthetic attributes together with numerical score assessment of each attribute. We use the evaluation criteria used in image captions to prove that our specially designed AMAN model outperforms traditional CNN-LSTM model and modern SCA-CNN model of image captions.