 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesthetic Visual Question Answering of Photographs
Paper and Code
Aug 10, 2022


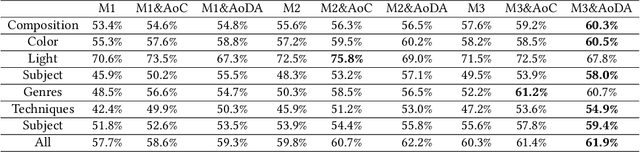
Aesthetic assessment of images can be categorized into two main forms: numerical assessment and language assessment. Aesthetics caption of photographs is the only task of aesthetic language assessment that has been addressed. In this paper, we propose a new task of aesthetic language assessment: aesthetic visual question and answering (AVQA) of images. If we give a question of images aesthetics, model can predict the answer. We use images from \textit{www.flickr.com}. The objective QA pairs are generated by the proposed aesthetic attributes analysis algorithms. Moreover, we introduce subjective QA pairs that are converted from aesthetic numerical labels and sentiment analysis from large-scale pre-train models. We build the first aesthetic visual question answering dataset, AesVQA, that contains 72,168 high-quality images and 324,756 pairs of aesthetic questions. Two methods for adjusting the data distribution have been proposed and proved to improve the accuracy of existing models. This is the first work that both addresses the task of aesthetic VQA and introduces subjectiveness into VQA tasks. The experimental results reveal that our methods outperform other VQA models on this new task.