 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesthetic Visual Question Answering of Photographs
Aug 10, 2022


Aesthetic assessment of images can be categorized into two main forms: numerical assessment and language assessment. Aesthetics caption of photographs is the only task of aesthetic language assessment that has been addressed. In this paper, we propose a new task of aesthetic language assessment: aesthetic visual question and answering (AVQA) of images. If we give a question of images aesthetics, model can predict the answer. We use images from \textit{www.flickr.com}. The objective QA pairs are generated by the proposed aesthetic attributes analysis algorithms. Moreover, we introduce subjective QA pairs that are converted from aesthetic numerical labels and sentiment analysis from large-scale pre-train models. We build the first aesthetic visual question answering dataset, AesVQA, that contains 72,168 high-quality images and 324,756 pairs of aesthetic questions. Two methods for adjusting the data distribution have been proposed and proved to improve the accuracy of existing models. This is the first work that both addresses the task of aesthetic VQA and introduces subjectiveness into VQA tasks. The experimental results reveal that our methods outperform other VQA models on this new task.
Aesthetic Language Guidance Generation of Images Using Attribute Comparison
Aug 09, 2022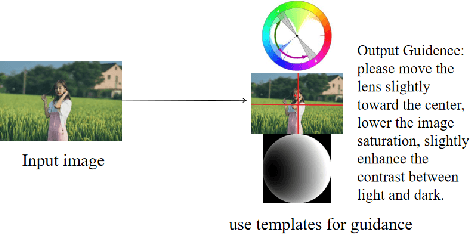

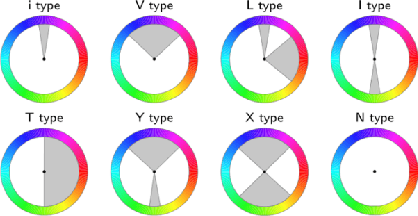
With the vigorous development of mobile photography technology, major mobile phone manufacturers are scrambling to improve the shooting ability of equipments and the photo beautification algorithm of software. However, the improvement of intelligent equipments and algorithms cannot replace human subjective photography technology. In this paper, we propose the aesthetic language guidance of image (ALG). We divide ALG into ALG-T and ALG-I according to whether the guiding rules are based on photography templates or guidance images. Whether it is ALG-T or ALG-I, we guide photography from three attributes of color, lighting and composition of the images. The differences of the three attributes between the input images and the photography templates or the guidance images are described in natural language, which is aesthetic natural language guidance (ALG). Also, because of the differences in lighting and composition between landscape images and portrait images, we divide the input images into landscape images and portrait images. Both ALG-T and ALG-I conduct aesthetic language guidance respectively for the two types of input images (landscape images and portrait images).
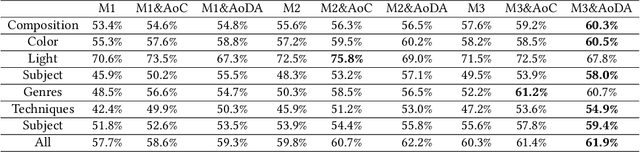
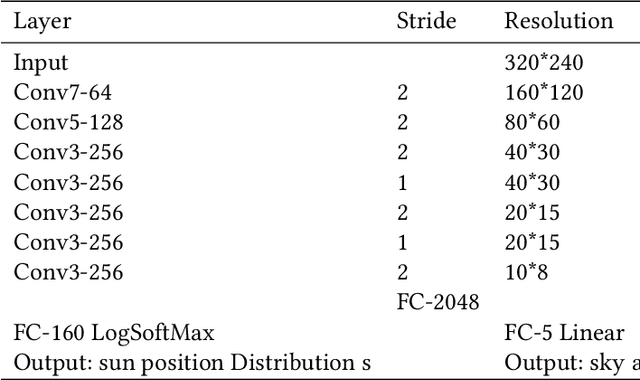
Aesthetic Attributes Assessment of Images with AMANv2 and DPC-CaptionsV2
Aug 09, 2022

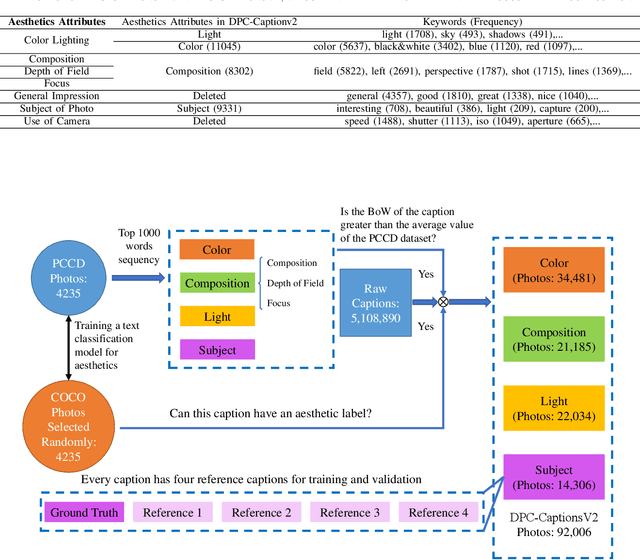

Image aesthetic quality assessment is popular during the last decade. Besides numerical assessment, nature language assessment (aesthetic captioning) has been proposed to describe the generally aesthetic impression of an image. In this paper, we propose aesthetic attribute assessment, which is the aesthetic attributes captioning, i.e., to assess the aesthetic attributes such as composition, lighting usage and color arrangement. It is a non-trivial task to label the comments of aesthetic attributes, which limit the scale of the corresponding datasets. We construct a novel dataset, named DPC-CaptionsV2, by a semi-automatic way. The knowledge is transferred from a small-scale dataset with full annotations to large-scale professional comments from a photography website. Images of DPC-CaptionsV2 contain comments up to 4 aesthetic attributes: composition, lighting, color, and subject. Then, we propose a new version of Aesthetic Multi-Attributes Networks (AMANv2) based on the BUTD model and the VLPSA model. AMANv2 fuses features of a mixture of small-scale PCCD dataset with full annotations and large-scale DPCCaptionsV2 dataset with full annotations. The experimental results of DPCCaptionsV2 show that our method can predict the comments on 4 aesthetic attributes, which are closer to aesthetic topics than those produced by the previous AMAN model. Through the evaluation criteria of image captioning, the specially designed AMANv2 model is better to the CNN-LSTM model and the AMAN model.