 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Scores of Various Aesthetic Attribute Sets by Learning from Overall Score Labels
Dec 06, 2023Now many mobile phones embed deep-learning models for evaluation or guidance on photography. These models cannot provide detailed results like human pose scores or scene color scores because of the rare of corresponding aesthetic attribute data. However, the annotation of image aesthetic attribute scores requires experienced artists and professional photographers, which hinders the collection of large-scale fully-annotated datasets. In this paper, we propose to replace image attribute labels with feature extractors. First, a novel aesthetic attribute evaluation framework based on attribute features is proposed to predict attribute scores and overall scores. We call it the F2S (attribute features to attribute scores) model. We use networks from different tasks to provide attribute features to our F2S models. Then, we define an aesthetic attribute contribution to describe the role of aesthetic attributes throughout an image and use it with the attribute scores and the overall scores to train our F2S model. Sufficient experiments on publicly available datasets demonstrate that our F2S model achieves comparable performance with those trained on the datasets with fully-annotated aesthetic attribute score labels. Our method makes it feasible to learn meaningful attribute scores for various aesthetic attribute sets in different types of images with only overall aesthetic scores.
An Order-Complexity Model for Aesthetic Quality Assessment of Symbolic Homophony Music Scores
Jan 14, 2023



Computational aesthetics evaluation has made great achievements in the field of visual arts, but the research work on music still needs to be explored. Although the existing work of music generation is very substantial, the quality of music score generated by AI is relatively poor compared with that created by human composers. The music scores created by AI are usually monotonous and devoid of emotion. Based on Birkhoff's aesthetic measure, this paper proposes an objective quantitative evaluation method for homophony music score aesthetic quality assessment. The main contributions of our work are as follows: first, we put forward a homophony music score aesthetic model to objectively evaluate the quality of music score as a baseline model; second, we put forward eight basic music features and four music aesthetic features.
Aesthetic Visual Question Answering of Photographs
Aug 10, 2022


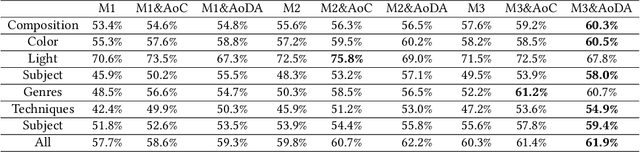
Aesthetic assessment of images can be categorized into two main forms: numerical assessment and language assessment. Aesthetics caption of photographs is the only task of aesthetic language assessment that has been addressed. In this paper, we propose a new task of aesthetic language assessment: aesthetic visual question and answering (AVQA) of images. If we give a question of images aesthetics, model can predict the answer. We use images from \textit{www.flickr.com}. The objective QA pairs are generated by the proposed aesthetic attributes analysis algorithms. Moreover, we introduce subjective QA pairs that are converted from aesthetic numerical labels and sentiment analysis from large-scale pre-train models. We build the first aesthetic visual question answering dataset, AesVQA, that contains 72,168 high-quality images and 324,756 pairs of aesthetic questions. Two methods for adjusting the data distribution have been proposed and proved to improve the accuracy of existing models. This is the first work that both addresses the task of aesthetic VQA and introduces subjectiveness into VQA tasks. The experimental results reveal that our methods outperform other VQA models on this new task.
Aesthetic Attributes Assessment of Images with AMANv2 and DPC-CaptionsV2
Aug 09, 2022

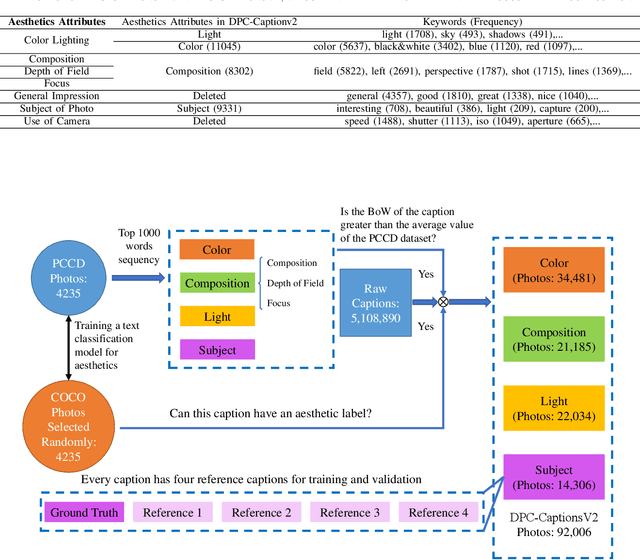

Image aesthetic quality assessment is popular during the last decade. Besides numerical assessment, nature language assessment (aesthetic captioning) has been proposed to describe the generally aesthetic impression of an image. In this paper, we propose aesthetic attribute assessment, which is the aesthetic attributes captioning, i.e., to assess the aesthetic attributes such as composition, lighting usage and color arrangement. It is a non-trivial task to label the comments of aesthetic attributes, which limit the scale of the corresponding datasets. We construct a novel dataset, named DPC-CaptionsV2, by a semi-automatic way. The knowledge is transferred from a small-scale dataset with full annotations to large-scale professional comments from a photography website. Images of DPC-CaptionsV2 contain comments up to 4 aesthetic attributes: composition, lighting, color, and subject. Then, we propose a new version of Aesthetic Multi-Attributes Networks (AMANv2) based on the BUTD model and the VLPSA model. AMANv2 fuses features of a mixture of small-scale PCCD dataset with full annotations and large-scale DPCCaptionsV2 dataset with full annotations. The experimental results of DPCCaptionsV2 show that our method can predict the comments on 4 aesthetic attributes, which are closer to aesthetic topics than those produced by the previous AMAN model. Through the evaluation criteria of image captioning, the specially designed AMANv2 model is better to the CNN-LSTM model and the AMAN model.
Aesthetic Attribute Assessment of Images Numerically on Mixed Multi-attribute Datasets
Jul 05, 2022

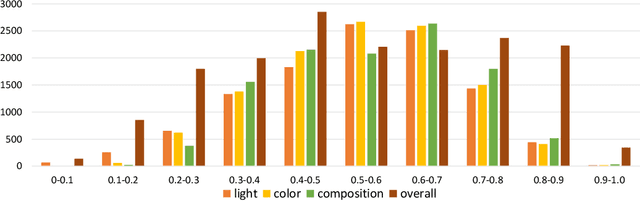

With the continuous development of social software and multimedia technology, images have become a kind of important carrier for spreading information and socializing. How to evaluate an image comprehensively has become the focus of recent researches. The traditional image aesthetic assessment methods often adopt single numerical overall assessment scores, which has certain subjectivity and can no longer meet the higher aesthetic requirements. In this paper, we construct an new image attribute dataset called aesthetic mixed dataset with attributes(AMD-A) and design external attribute features for fusion. Besides, we propose a efficient method for image aesthetic attribute assessment on mixed multi-attribute dataset and construct a multitasking network architecture by using the EfficientNet-B0 as the backbone network. Our model can achieve aesthetic classification, overall scoring and attribute scoring. In each sub-network, we improve the feature extraction through ECA channel attention module. As for the final overall scoring, we adopt the idea of the teacher-student network and use the classification sub-network to guide the aesthetic overall fine-grain regression. Experimental results, using the MindSpore, show that our proposed method can effectively improve the performance of the aesthetic overall and attribute assessment.
Pseudo-labelling and Meta Reweighting Learning for Image Aesthetic Quality Assessment
Jan 08, 2022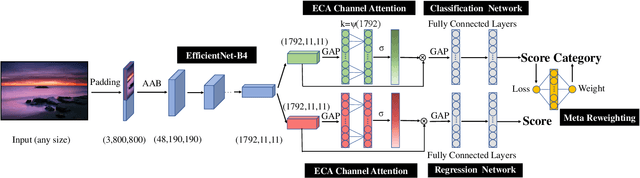

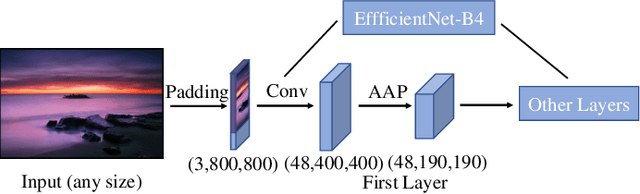
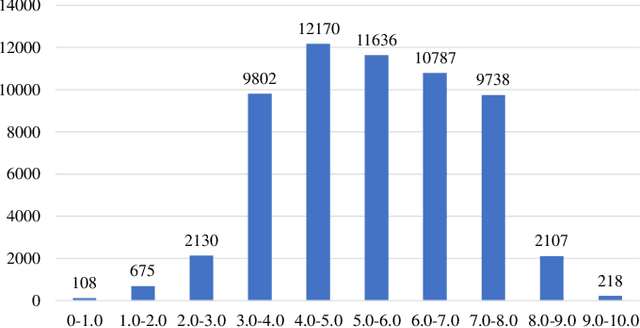
In the tasks of image aesthetic quality evaluation, it is difficult to reach both the high score area and low score area due to the normal distribution of aesthetic datasets. To reduce the error in labeling and solve the problem of normal data distribution, we propose a new aesthetic mixed dataset with classification and regression called AMD-CR, and we train a meta reweighting network to reweight the loss of training data differently. In addition, we provide a training strategy acccording to different stages, based on pseudo labels of the binary classification task, and then we use it for aesthetic training acccording to different stages in classification and regression tasks. In the construction of the network structure, we construct an aesthetic adaptive block (AAB) structure that can adapt to any size of the input images. Besides, we also use the efficient channel attention (ECA) to strengthen the feature extracting ability of each task. The experimental result shows that our method improves 0.1112 compared with the conventional methods in SROCC. The method can also help to find best aesthetic path planning for unmanned aerial vehicles (UAV) and vehicles.