 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasonTigers at SemEval-2024 Task 9: Solving Puzzles with an Ensemble of Chain-of-Thoughts
Paper and Code
Apr 03, 2024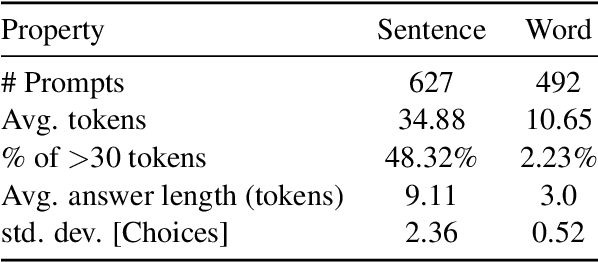


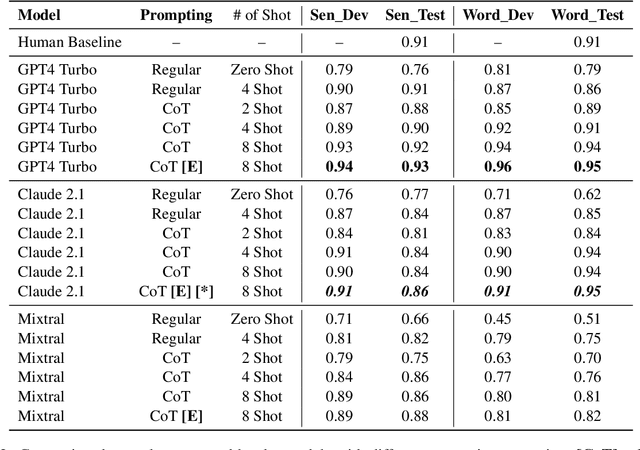
Our paper presents team MasonTigers submission to the SemEval-2024 Task 9 - which provides a dataset of puzzles for testing natural language understanding. We employ large language models (LLMs) to solve this task through several prompting techniques. Zero-shot and few-shot prompting generate reasonably good results when tested with proprietary LLMs, compared to the open-source models. We obtain further improved results with chain-of-thought prompting, an iterative prompting method that breaks down the reasoning process step-by-step. We obtain our best results by utilizing an ensemble of chain-of-thought prompts, placing 2nd in the word puzzle subtask and 13th in the sentence puzzle subtask. The strong performance of prompted LLMs demonstrates their capability for complex reasoning when provided with a decomposition of the thought process. Our work sheds light on how step-wise explanatory prompts can unlock more of the knowledge encoded in the parameters of large models.