 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Engineering Configurations of Neural Text Generation Models
Apr 13, 2020
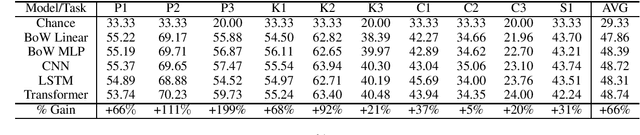
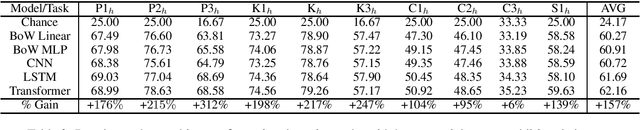
This paper seeks to develop a deeper understanding of the fundamental properties of neural text generations models. The study of artifacts that emerge in machine generated text as a result of modeling choices is a nascent research area. Previously, the extent and degree to which these artifacts surface in generated text has not been well studied. In the spirit of better understanding generative text models and their artifacts, we propose the new task of distinguishing which of several variants of a given model generated a piece of text, and we conduct an extensive suite of diagnostic tests to observe whether modeling choices (e.g., sampling methods, top-$k$ probabilities, model architectures, etc.) leave detectable artifacts in the text they generate. Our key finding, which is backed by a rigorous set of experiments, is that such artifacts are present and that different modeling choices can be inferred by observing the generated text alone. This suggests that neural text generators may be more sensitive to various modeling choices than previously thought.