 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntaxNet Models for the CoNLL 2017 Shared Task
Mar 15, 2017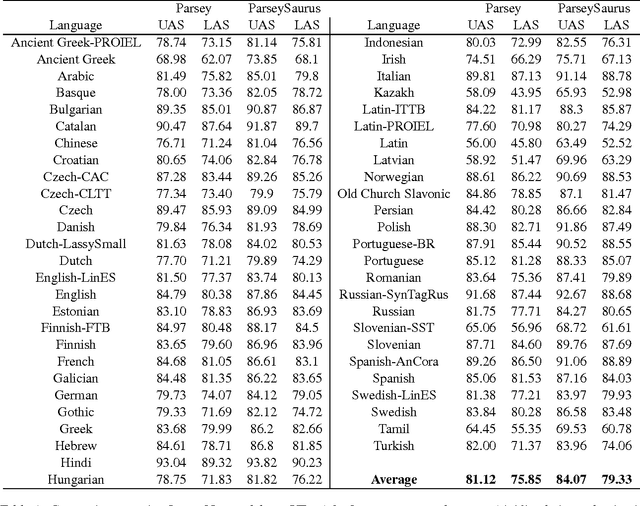
We describe a baseline dependency parsing system for the CoNLL2017 Shared Task. This system, which we call "ParseySaurus," uses the DRAGNN framework [Kong et al, 2017] to combine transition-based recurrent parsing and tagging with character-based word representations. On the v1.3 Universal Dependencies Treebanks, the new system outpeforms the publicly available, state-of-the-art "Parsey's Cousins" models by 3.47% absolute Labeled Accuracy Score (LAS) across 52 treebanks.
Context-Dependent Fine-Grained Entity Type Tagging
Aug 01, 2016



Entity type tagging is the task of assigning category labels to each mention of an entity in a document. While standard systems focus on a small set of types, recent work (Ling and Weld, 2012) suggests that using a large fine-grained label set can lead to dramatic improvements in downstream tasks. In the absence of labeled training data, existing fine-grained tagging systems obtain examples automatically, using resolved entities and their types extracted from a knowledge base. However, since the appropriate type often depends on context (e.g. Washington could be tagged either as city or government), this procedure can result in spurious labels, leading to poorer generalization. We propose the task of context-dependent fine type tagging, where the set of acceptable labels for a mention is restricted to only those deducible from the local context (e.g. sentence or document). We introduce new resources for this task: 12,017 mentions annotated with their context-dependent fine types, and we provide baseline experimental results on this data.
Multilingual Language Processing From Bytes
Apr 02, 2016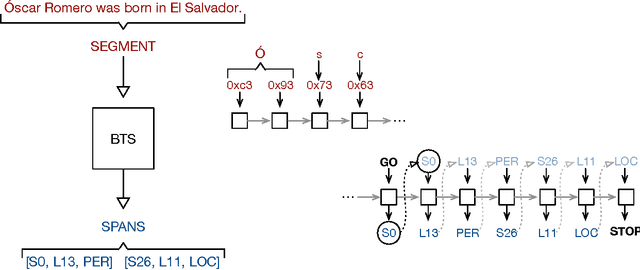
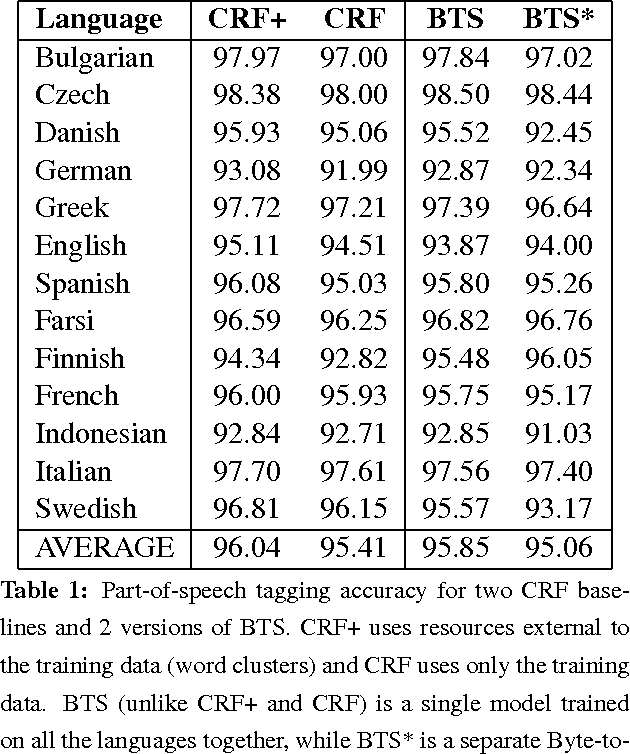
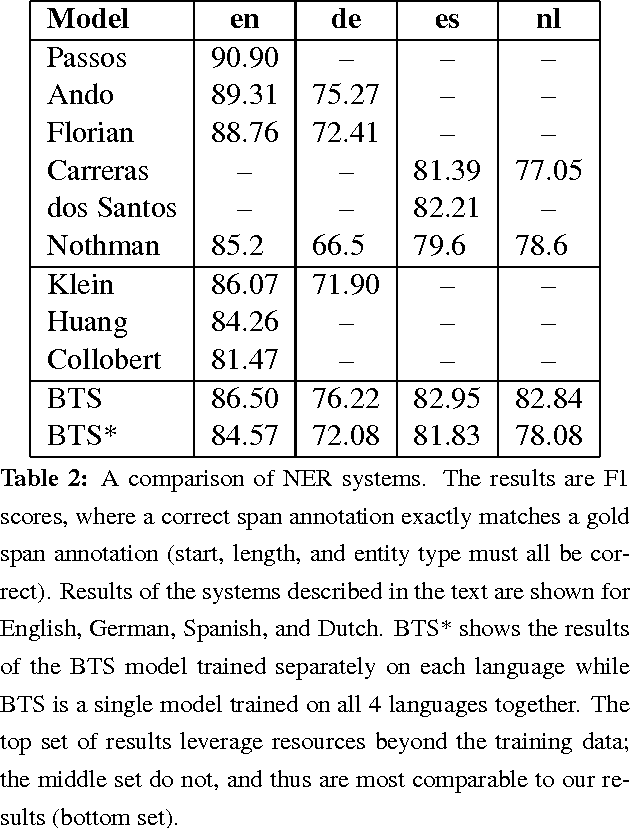

We describe an LSTM-based model which we call Byte-to-Span (BTS) that reads text as bytes and outputs span annotations of the form [start, length, label] where start positions, lengths, and labels are separate entries in our vocabulary. Because we operate directly on unicode bytes rather than language-specific words or characters, we can analyze text in many languages with a single model. Due to the small vocabulary size, these multilingual models are very compact, but produce results similar to or better than the state-of- the-art in Part-of-Speech tagging and Named Entity Recognition that use only the provided training datasets (no external data sources). Our models are learning "from scratch" in that they do not rely on any elements of the standard pipeline in Natural Language Processing (including tokenization), and thus can run in standalone fashion on raw text.