 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Language Processing From Bytes
Apr 02, 2016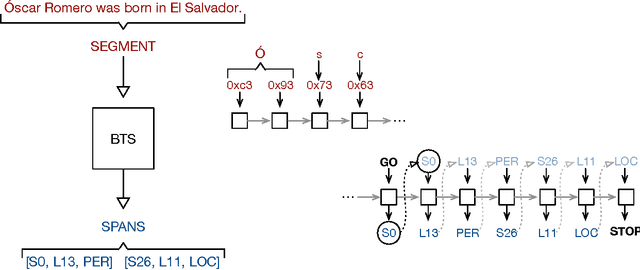
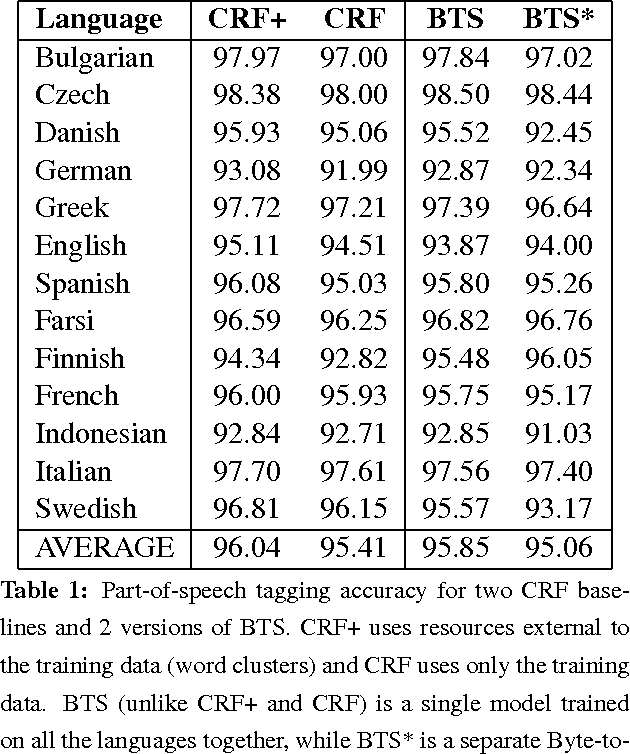
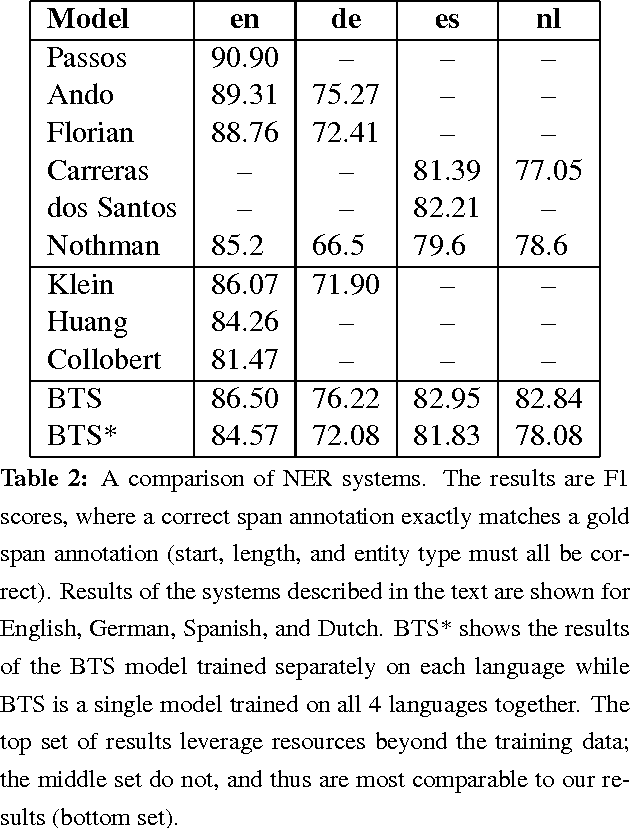

We describe an LSTM-based model which we call Byte-to-Span (BTS) that reads text as bytes and outputs span annotations of the form [start, length, label] where start positions, lengths, and labels are separate entries in our vocabulary. Because we operate directly on unicode bytes rather than language-specific words or characters, we can analyze text in many languages with a single model. Due to the small vocabulary size, these multilingual models are very compact, but produce results similar to or better than the state-of- the-art in Part-of-Speech tagging and Named Entity Recognition that use only the provided training datasets (no external data sources). Our models are learning "from scratch" in that they do not rely on any elements of the standard pipeline in Natural Language Processing (including tokenization), and thus can run in standalone fashion on raw text.
Recognizing Activities and Spatial Context Using Wearable Sensors
Jun 27, 2012

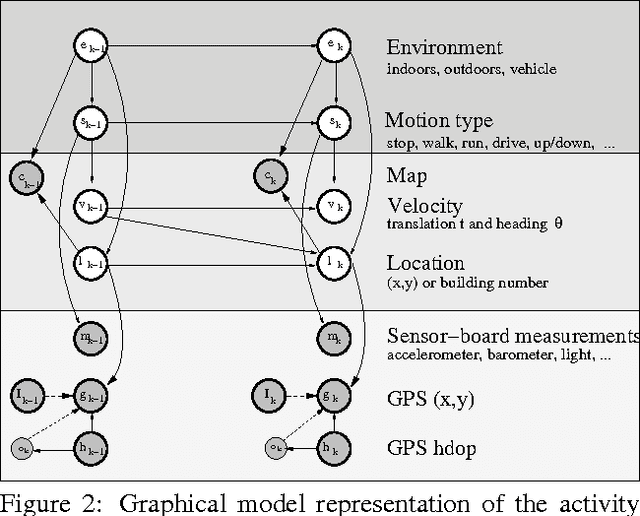

We introduce a new dynamic model with the capability of recognizing both activities that an individual is performing as well as where that ndividual is located. Our model is novel in that it utilizes a dynamic graphical model to jointly estimate both activity and spatial context over time based on the simultaneous use of asynchronous observations consisting of GPS measurements, and measurements from a small mountable sensor board. Joint inference is quite desirable as it has the ability to improve accuracy of the model. A key goal, however, in designing our overall system is to be able to perform accurate inference decisions while minimizing the amount of hardware an individual must wear. This minimization leads to greater comfort and flexibility, decreased power requirements and therefore increased battery life, and reduced cost. We show results indicating that our joint measurement model outperforms measurements from either the sensor board or GPS alone, using two types of probabilistic inference procedures, namely particle filtering and pruned exact inference.