 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
LMDX: Language Model-based Document Information Extraction and Localization
Sep 19, 2023


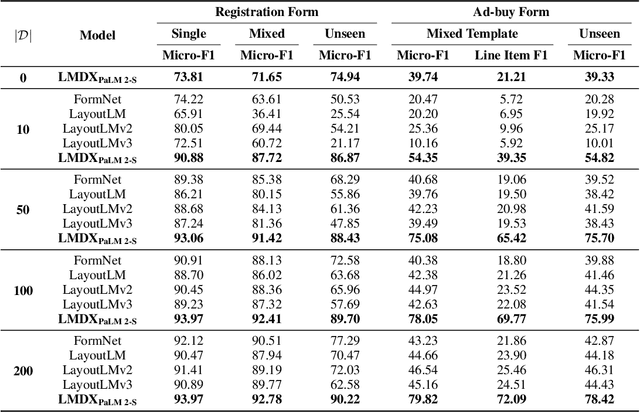
Large Language Models (LLM) have revolutionized Natural Language Processing (NLP), improving state-of-the-art on many existing tasks and exhibiting emergent capabilities. However, LLMs have not yet been successfully applied on semi-structured document information extraction, which is at the core of many document processing workflows and consists of extracting key entities from a visually rich document (VRD) given a predefined target schema. The main obstacles to LLM adoption in that task have been the absence of layout encoding within LLMs, critical for a high quality extraction, and the lack of a grounding mechanism ensuring the answer is not hallucinated. In this paper, we introduce Language Model-based Document Information Extraction and Localization (LMDX), a methodology to adapt arbitrary LLMs for document information extraction. LMDX can do extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document. In particular, we apply LMDX to the PaLM 2-S LLM and evaluate it on VRDU and CORD benchmarks, setting a new state-of-the-art and showing how LMDX enables the creation of high quality, data-efficient parsers.
All-but-the-Top: Simple and Effective Postprocessing for Word Representations
Mar 19, 2018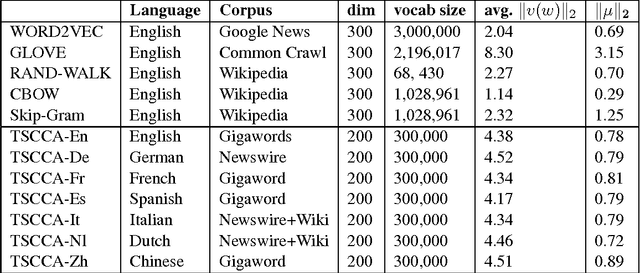
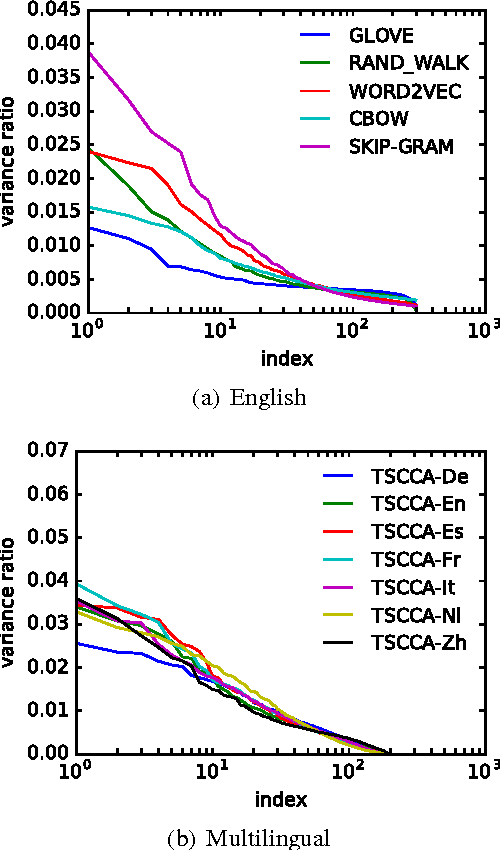
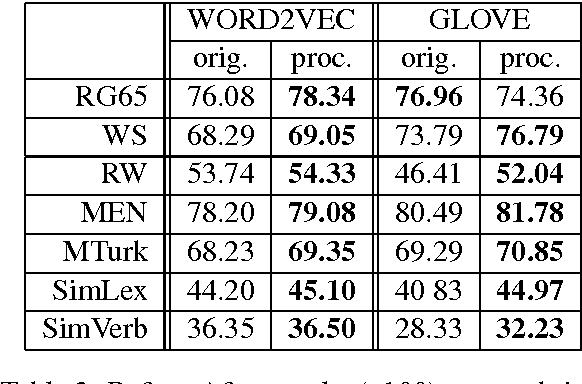
Real-valued word representations have transformed NLP applications; popular examples are word2vec and GloVe, recognized for their ability to capture linguistic regularities. In this paper, we demonstrate a {\em very simple}, and yet counter-intuitive, postprocessing technique -- eliminate the common mean vector and a few top dominating directions from the word vectors -- that renders off-the-shelf representations {\em even stronger}. The postprocessing is empirically validated on a variety of lexical-level intrinsic tasks (word similarity, concept categorization, word analogy) and sentence-level tasks (semantic textural similarity and { text classification}) on multiple datasets and with a variety of representation methods and hyperparameter choices in multiple languages; in each case, the processed representations are consistently better than the original ones.
Representing Sentences as Low-Rank Subspaces
Apr 18, 2017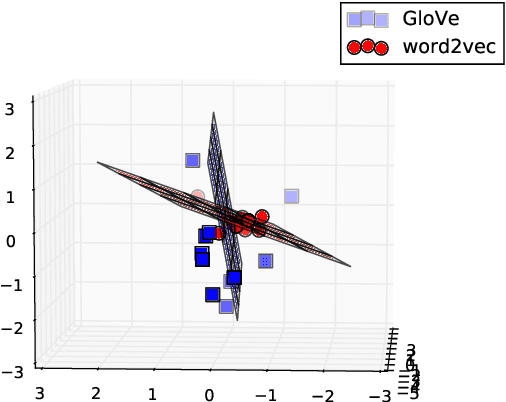
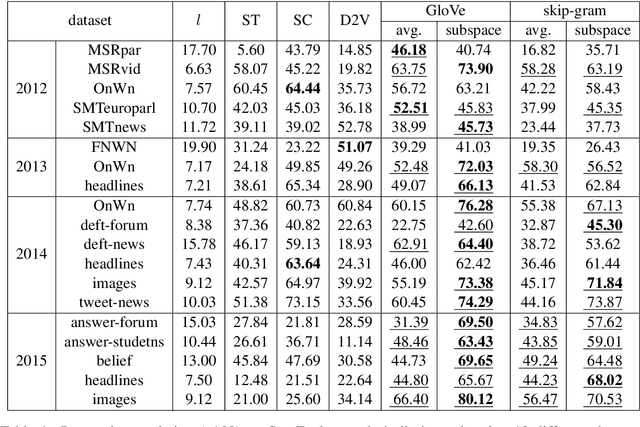
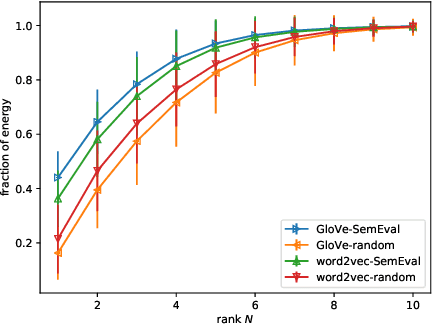
Sentences are important semantic units of natural language. A generic, distributional representation of sentences that can capture the latent semantics is beneficial to multiple downstream applications. We observe a simple geometry of sentences -- the word representations of a given sentence (on average 10.23 words in all SemEval datasets with a standard deviation 4.84) roughly lie in a low-rank subspace (roughly, rank 4). Motivated by this observation, we represent a sentence by the low-rank subspace spanned by its word vectors. Such an unsupervised representation is empirically validated via semantic textual similarity tasks on 19 different datasets, where it outperforms the sophisticated neural network models, including skip-thought vectors, by 15% on average.
Prepositions in Context
Feb 05, 2017
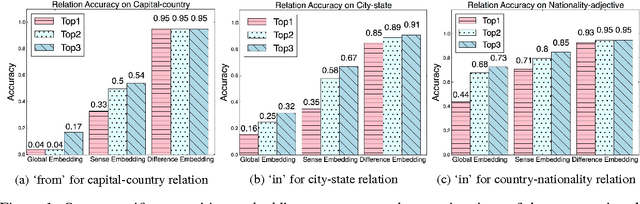
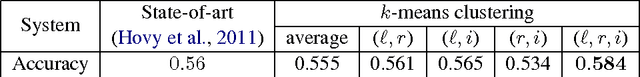
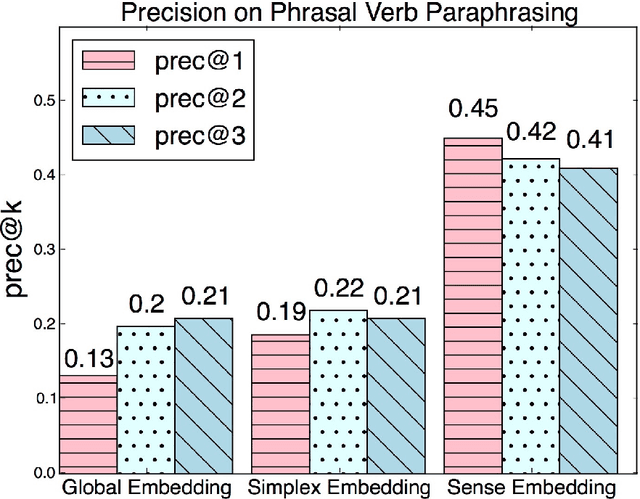
Prepositions are highly polysemous, and their variegated senses encode significant semantic information. In this paper we match each preposition's complement and attachment and their interplay crucially to the geometry of the word vectors to the left and right of the preposition. Extracting such features from the vast number of instances of each preposition and clustering them makes for an efficient preposition sense disambigution (PSD) algorithm, which is comparable to and better than state-of-the-art on two benchmark datasets. Our reliance on no external linguistic resource allows us to scale the PSD algorithm to a large WikiCorpus and learn sense-specific preposition representations -- which we show to encode semantic relations and paraphrasing of verb particle compounds, via simple vector operations.
Geometry of Polysemy
Oct 24, 2016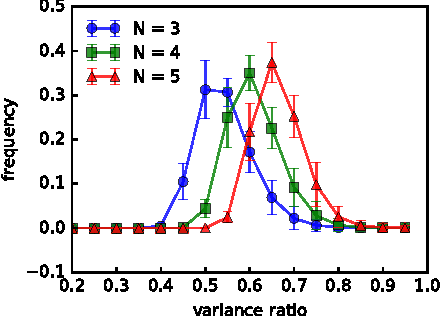

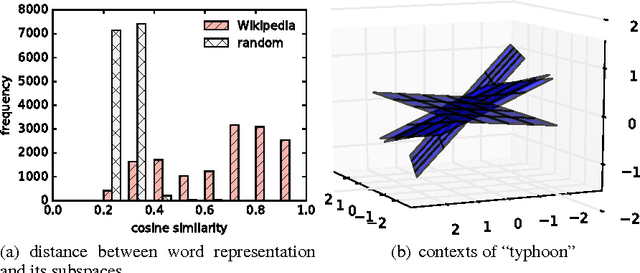
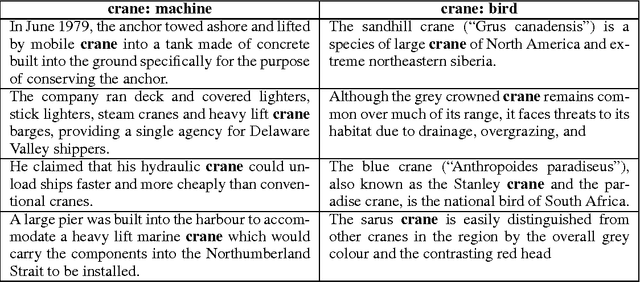
Vector representations of words have heralded a transformational approach to classical problems in NLP; the most popular example is word2vec. However, a single vector does not suffice to model the polysemous nature of many (frequent) words, i.e., words with multiple meanings. In this paper, we propose a three-fold approach for unsupervised polysemy modeling: (a) context representations, (b) sense induction and disambiguation and (c) lexeme (as a word and sense pair) representations. A key feature of our work is the finding that a sentence containing a target word is well represented by a low rank subspace, instead of a point in a vector space. We then show that the subspaces associated with a particular sense of the target word tend to intersect over a line (one-dimensional subspace), which we use to disambiguate senses using a clustering algorithm that harnesses the Grassmannian geometry of the representations. The disambiguation algorithm, which we call $K$-Grassmeans, leads to a procedure to label the different senses of the target word in the corpus -- yielding lexeme vector representations, all in an unsupervised manner starting from a large (Wikipedia) corpus in English. Apart from several prototypical target (word,sense) examples and a host of empirical studies to intuit and justify the various geometric representations, we validate our algorithms on standard sense induction and disambiguation datasets and present new state-of-the-art results.