 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrepositions in Context
Paper and Code

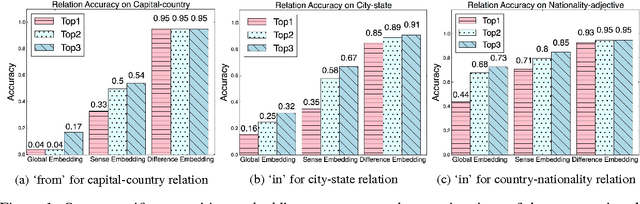
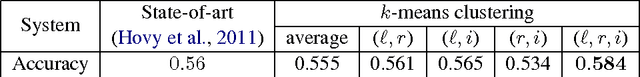
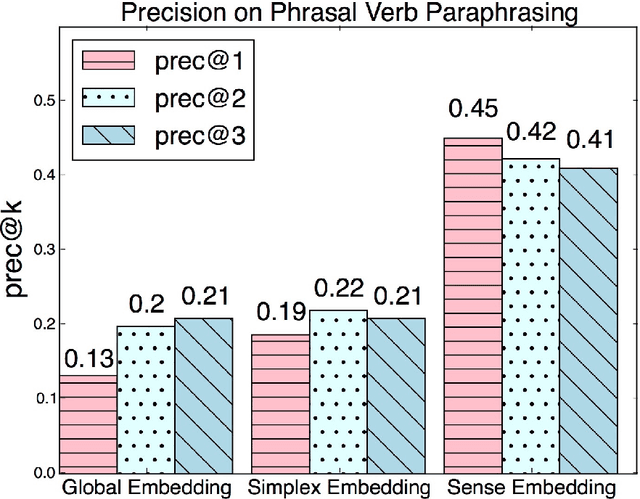
Prepositions are highly polysemous, and their variegated senses encode significant semantic information. In this paper we match each preposition's complement and attachment and their interplay crucially to the geometry of the word vectors to the left and right of the preposition. Extracting such features from the vast number of instances of each preposition and clustering them makes for an efficient preposition sense disambigution (PSD) algorithm, which is comparable to and better than state-of-the-art on two benchmark datasets. Our reliance on no external linguistic resource allows us to scale the PSD algorithm to a large WikiCorpus and learn sense-specific preposition representations -- which we show to encode semantic relations and paraphrasing of verb particle compounds, via simple vector operations.