 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeak Your Mind: The Speech Continuation Task as a Probe of Voice-Based Model Bias
Sep 26, 2025Speech Continuation (SC) is the task of generating a coherent extension of a spoken prompt while preserving both semantic context and speaker identity. Because SC is constrained to a single audio stream, it offers a more direct setting for probing biases in speech foundation models than dialogue does. In this work we present the first systematic evaluation of bias in SC, investigating how gender and phonation type (breathy, creaky, end-creak) affect continuation behaviour. We evaluate three recent models: SpiritLM (base and expressive), VAE-GSLM, and SpeechGPT across speaker similarity, voice quality preservation, and text-based bias metrics. Results show that while both speaker similarity and coherence remain a challenge, textual evaluations reveal significant model and gender interactions: once coherence is sufficiently high (for VAE-GSLM), gender effects emerge on text-metrics such as agency and sentence polarity. In addition, continuations revert toward modal phonation more strongly for female prompts than for male ones, revealing a systematic voice-quality bias. These findings highlight SC as a controlled probe of socially relevant representational biases in speech foundation models, and suggest that it will become an increasingly informative diagnostic as continuation quality improves.
Will AI shape the way we speak? The emerging sociolinguistic influence of synthetic voices
Apr 14, 2025The growing prevalence of conversational voice interfaces, powered by developments in both speech and language technologies, raises important questions about their influence on human communication. While written communication can signal identity through lexical and stylistic choices, voice-based interactions inherently amplify socioindexical elements - such as accent, intonation, and speech style - which more prominently convey social identity and group affiliation. There is evidence that even passive media such as television is likely to influence the audience's linguistic patterns. Unlike passive media, conversational AI is interactive, creating a more immersive and reciprocal dynamic that holds a greater potential to impact how individuals speak in everyday interactions. Such heightened influence can be expected to arise from phenomena such as acoustic-prosodic entrainment and linguistic accommodation, which occur naturally during interaction and enable users to adapt their speech patterns in response to the system. While this phenomenon is still emerging, its potential societal impact could provide organisations, movements, and brands with a subtle yet powerful avenue for shaping and controlling public perception and social identity. We argue that the socioindexical influence of AI-generated speech warrants attention and should become a focus of interdisciplinary research, leveraging new and existing methodologies and technologies to better understand its implications.
Should you use a probabilistic duration model in TTS? Probably! Especially for spontaneous speech
Jun 08, 2024Converting input symbols to output audio in TTS requires modelling the durations of speech sounds. Leading non-autoregressive (NAR) TTS models treat duration modelling as a regression problem. The same utterance is then spoken with identical timings every time, unlike when a human speaks. Probabilistic models of duration have been proposed, but there is mixed evidence of their benefits. However, prior studies generally only consider speech read aloud, and ignore spontaneous speech, despite the latter being both a more common and a more variable mode of speaking. We compare the effect of conventional deterministic duration modelling to durations sampled from a powerful probabilistic model based on conditional flow matching (OT-CFM), in three different NAR TTS approaches: regression-based, deep generative, and end-to-end. Across four different corpora, stochastic duration modelling improves probabilistic NAR TTS approaches, especially for spontaneous speech. Please see https://shivammehta25.github.io/prob_dur/ for audio and resources.
Evaluating Text-to-Speech Synthesis from a Large Discrete Token-based Speech Language Model
May 16, 2024


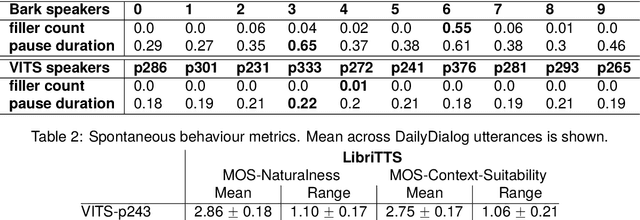
Recent advances in generative language modeling applied to discrete speech tokens presented a new avenue for text-to-speech (TTS) synthesis. These speech language models (SLMs), similarly to their textual counterparts, are scalable, probabilistic, and context-aware. While they can produce diverse and natural outputs, they sometimes face issues such as unintelligibility and the inclusion of non-speech noises or hallucination. As the adoption of this innovative paradigm in speech synthesis increases, there is a clear need for an in-depth evaluation of its capabilities and limitations. In this paper, we evaluate TTS from a discrete token-based SLM, through both automatic metrics and listening tests. We examine five key dimensions: speaking style, intelligibility, speaker consistency, prosodic variation, spontaneous behaviour. Our results highlight the model's strength in generating varied prosody and spontaneous outputs. It is also rated higher in naturalness and context appropriateness in listening tests compared to a conventional TTS. However, the model's performance in intelligibility and speaker consistency lags behind traditional TTS. Additionally, we show that increasing the scale of SLMs offers a modest boost in robustness. Our findings aim to serve as a benchmark for future advancements in generative SLMs for speech synthesis.
Unified speech and gesture synthesis using flow matching
Oct 08, 2023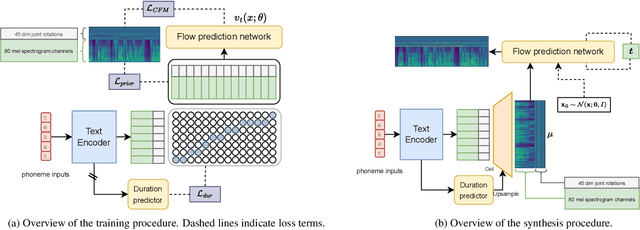
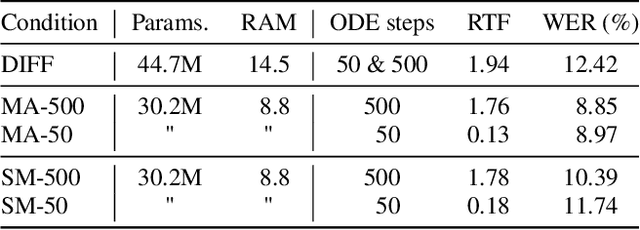
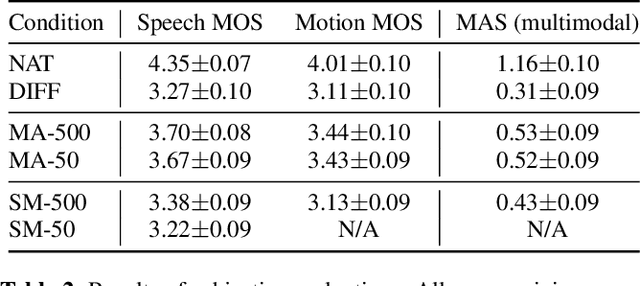
As text-to-speech technologies achieve remarkable naturalness in read-aloud tasks, there is growing interest in multimodal synthesis of verbal and non-verbal communicative behaviour, such as spontaneous speech and associated body gestures. This paper presents a novel, unified architecture for jointly synthesising speech acoustics and skeleton-based 3D gesture motion from text, trained using optimal-transport conditional flow matching (OT-CFM). The proposed architecture is simpler than the previous state of the art, has a smaller memory footprint, and can capture the joint distribution of speech and gestures, generating both modalities together in one single process. The new training regime, meanwhile, enables better synthesis quality in much fewer steps (network evaluations) than before. Uni- and multimodal subjective tests demonstrate improved speech naturalness, gesture human-likeness, and cross-modal appropriateness compared to existing benchmarks.
Matcha-TTS: A fast TTS architecture with conditional flow matching
Sep 06, 2023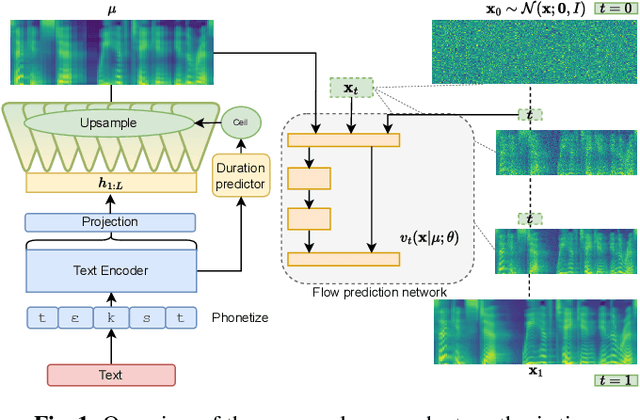
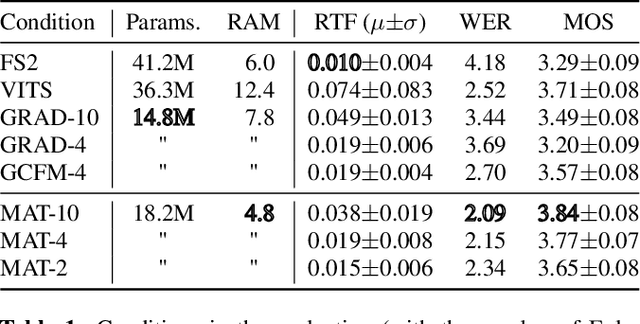
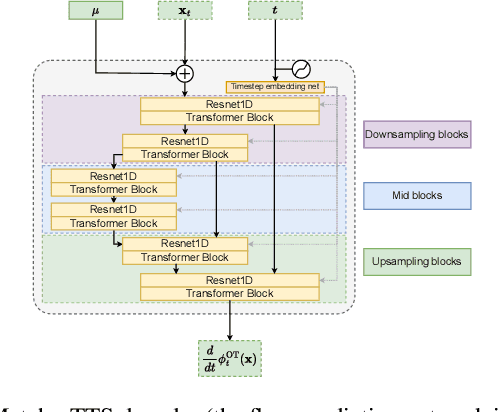
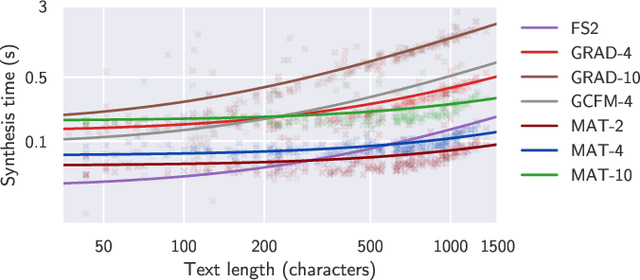
We introduce Matcha-TTS, a new encoder-decoder architecture for speedy TTS acoustic modelling, trained using optimal-transport conditional flow matching (OT-CFM). This yields an ODE-based decoder capable of high output quality in fewer synthesis steps than models trained using score matching. Careful design choices additionally ensure each synthesis step is fast to run. The method is probabilistic, non-autoregressive, and learns to speak from scratch without external alignments. Compared to strong pre-trained baseline models, the Matcha-TTS system has the smallest memory footprint, rivals the speed of the fastest models on long utterances, and attains the highest mean opinion score in a listening test. Please see https://shivammehta25.github.io/Matcha-TTS/ for audio examples, code, and pre-trained models.
On the Use of Self-Supervised Speech Representations in Spontaneous Speech Synthesis
Jul 11, 2023Self-supervised learning (SSL) speech representations learned from large amounts of diverse, mixed-quality speech data without transcriptions are gaining ground in many speech technology applications. Prior work has shown that SSL is an effective intermediate representation in two-stage text-to-speech (TTS) for both read and spontaneous speech. However, it is still not clear which SSL and which layer from each SSL model is most suited for spontaneous TTS. We address this shortcoming by extending the scope of comparison for SSL in spontaneous TTS to 6 different SSLs and 3 layers within each SSL. Furthermore, SSL has also shown potential in predicting the mean opinion scores (MOS) of synthesized speech, but this has only been done in read-speech MOS prediction. We extend an SSL-based MOS prediction framework previously developed for scoring read speech synthesis and evaluate its performance on synthesized spontaneous speech. All experiments are conducted twice on two different spontaneous corpora in order to find generalizable trends. Overall, we present comprehensive experimental results on the use of SSL in spontaneous TTS and MOS prediction to further quantify and understand how SSL can be used in spontaneous TTS. Audios samples: https://www.speech.kth.se/tts-demos/sp_ssl_tts
Diff-TTSG: Denoising probabilistic integrated speech and gesture synthesis
Jun 15, 2023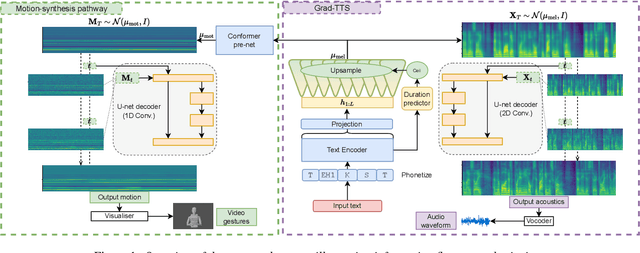

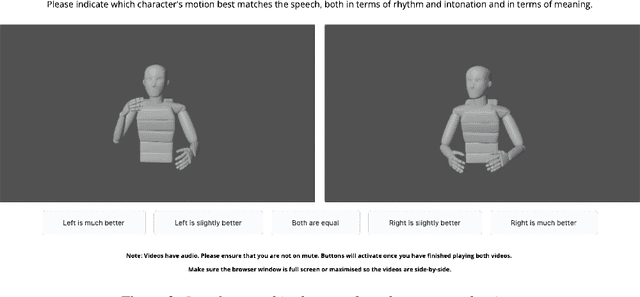
With read-aloud speech synthesis achieving high naturalness scores, there is a growing research interest in synthesising spontaneous speech. However, human spontaneous face-to-face conversation has both spoken and non-verbal aspects (here, co-speech gestures). Only recently has research begun to explore the benefits of jointly synthesising these two modalities in a single system. The previous state of the art used non-probabilistic methods, which fail to capture the variability of human speech and motion, and risk producing oversmoothing artefacts and sub-optimal synthesis quality. We present the first diffusion-based probabilistic model, called Diff-TTSG, that jointly learns to synthesise speech and gestures together. Our method can be trained on small datasets from scratch. Furthermore, we describe a set of careful uni- and multi-modal subjective tests for evaluating integrated speech and gesture synthesis systems, and use them to validate our proposed approach. For synthesised examples please see https://shivammehta25.github.io/Diff-TTSG
Automatic Evaluation of Turn-taking Cues in Conversational Speech Synthesis
May 29, 2023



Turn-taking is a fundamental aspect of human communication where speakers convey their intention to either hold, or yield, their turn through prosodic cues. Using the recently proposed Voice Activity Projection model, we propose an automatic evaluation approach to measure these aspects for conversational speech synthesis. We investigate the ability of three commercial, and two open-source, Text-To-Speech (TTS) systems ability to generate turn-taking cues over simulated turns. By varying the stimuli, or controlling the prosody, we analyze the models performances. We show that while commercial TTS largely provide appropriate cues, they often produce ambiguous signals, and that further improvements are possible. TTS, trained on read or spontaneous speech, produce strong turn-hold but weak turn-yield cues. We argue that this approach, that focus on functional aspects of interaction, provides a useful addition to other important speech metrics, such as intelligibility and naturalness.
A Comparative Study of Self-Supervised Speech Representations in Read and Spontaneous TTS
Mar 05, 2023Recent work has explored using self-supervised learning (SSL) speech representations such as wav2vec2.0 as the representation medium in standard two-stage TTS, in place of conventionally used mel-spectrograms. It is however unclear which speech SSL is the better fit for TTS, and whether or not the performance differs between read and spontaneous TTS, the later of which is arguably more challenging. This study aims at addressing these questions by testing several speech SSLs, including different layers of the same SSL, in two-stage TTS on both read and spontaneous corpora, while maintaining constant TTS model architecture and training settings. Results from listening tests show that the 9th layer of 12-layer wav2vec2.0 (ASR finetuned) outperforms other tested SSLs and mel-spectrogram, in both read and spontaneous TTS. Our work sheds light on both how speech SSL can readily improve current TTS systems, and how SSLs compare in the challenging generative task of TTS. Audio examples can be found at https://www.speech.kth.se/tts-demos/ssr_tts