 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Adaptation with Meta-Reinforcement Learning for Trust Modelling in Human-Robot Interaction
Aug 12, 2019
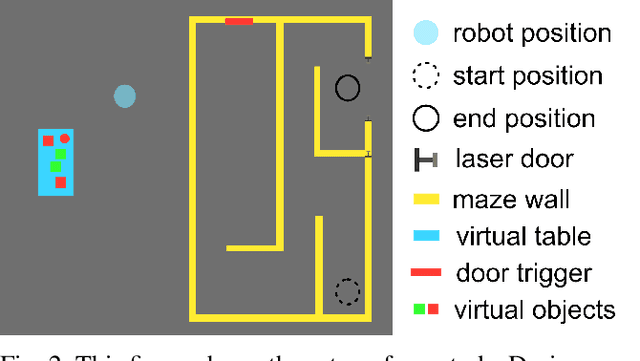
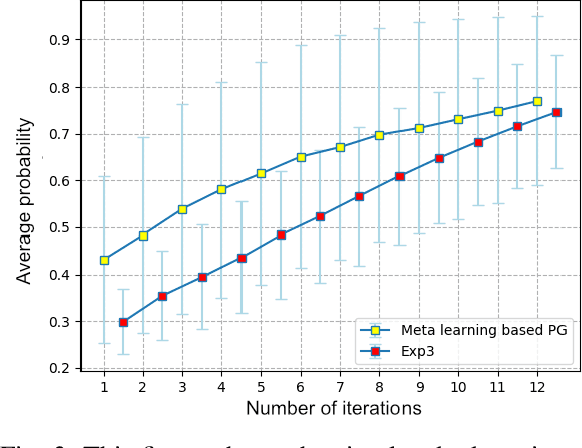
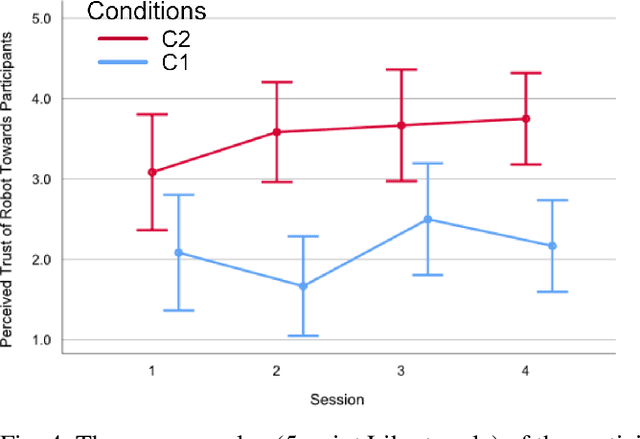
In socially assistive robotics, an important research area is the development of adaptation techniques and their effect on human-robot interaction. We present a meta-learning based policy gradient method for addressing the problem of adaptation in human-robot interaction and also investigate its role as a mechanism for trust modelling. By building an escape room scenario in mixed reality with a robot, we test our hypothesis that bi-directional trust can be influenced by different adaptation algorithms. We found that our proposed model increased the perceived trustworthiness of the robot and influenced the dynamics of gaining human's trust. Additionally, participants evaluated that the robot perceived them as more trustworthy during the interactions with the meta-learning based adaptation compared to the previously studied statistical adaptation model.
Exploring Temporal Dependencies in Multimodal Referring Expressions with Mixed Reality
Feb 04, 2019
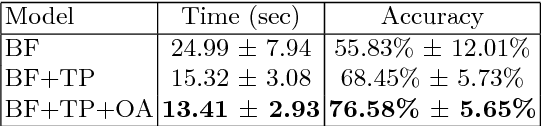
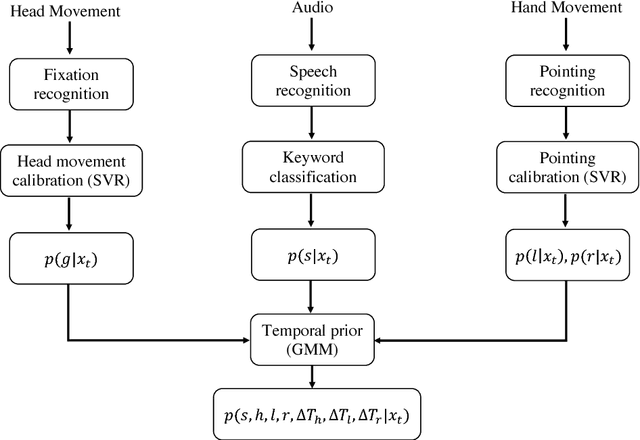

In collaborative tasks, people rely both on verbal and non-verbal cues simultaneously to communicate with each other. For human-robot interaction to run smoothly and naturally, a robot should be equipped with the ability to robustly disambiguate referring expressions. In this work, we propose a model that can disambiguate multimodal fetching requests using modalities such as head movements, hand gestures, and speech. We analysed the acquired data from mixed reality experiments and formulated a hypothesis that modelling temporal dependencies of events in these three modalities increases the model's predictive power. We evaluated our model on a Bayesian framework to interpret referring expressions with and without exploiting a temporal prior.
A Comparison of Visualisation Methods for Disambiguating Verbal Requests in Human-Robot Interaction
Jan 26, 2018

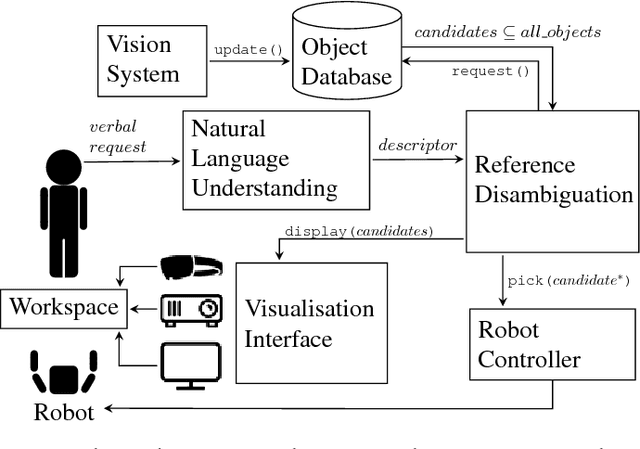

Picking up objects requested by a human user is a common task in human-robot interaction. When multiple objects match the user's verbal description, the robot needs to clarify which object the user is referring to before executing the action. Previous research has focused on perceiving user's multimodal behaviour to complement verbal commands or minimising the number of follow up questions to reduce task time. In this paper, we propose a system for reference disambiguation based on visualisation and compare three methods to disambiguate natural language instructions. In a controlled experiment with a YuMi robot, we investigated real-time augmentations of the workspace in three conditions -- mixed reality, augmented reality, and a monitor as the baseline -- using objective measures such as time and accuracy, and subjective measures like engagement, immersion, and display interference. Significant differences were found in accuracy and engagement between the conditions, but no differences were found in task time. Despite the higher error rates in the mixed reality condition, participants found that modality more engaging than the other two, but overall showed preference for the augmented reality condition over the monitor and mixed reality conditions.