 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Disaster Response of Tomorrow -- Final Presentation and Evaluation of the CENTAURO System
Sep 19, 2019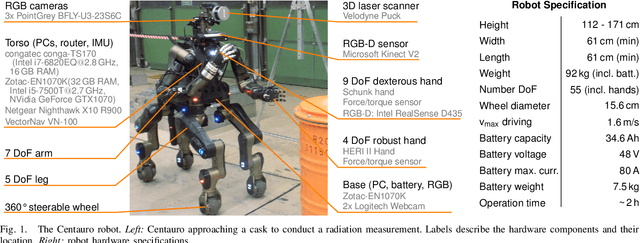

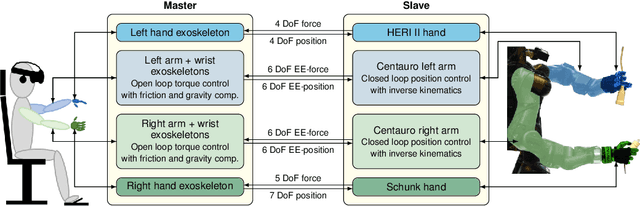
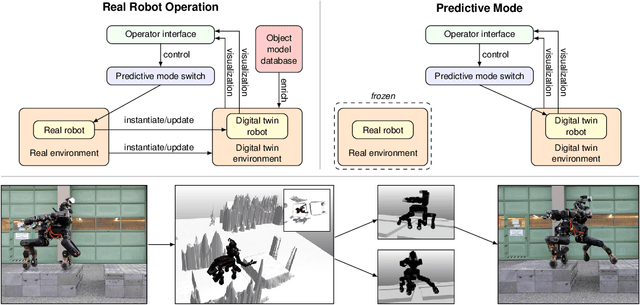
Mobile manipulation robots have high potential to support rescue forces in disaster-response missions. Despite the difficulties imposed by real-world scenarios, robots are promising to perform mission tasks from a safe distance. In the CENTAURO project, we developed a disaster-response system which consists of the highly flexible Centauro robot and suitable control interfaces including an immersive tele-presence suit and support-operator controls on different levels of autonomy. In this article, we give an overview of the final CENTAURO system. In particular, we explain several high-level design decisions and how those were derived from requirements and extensive experience of Kerntechnische Hilfsdienst GmbH, Karlsruhe, Germany (KHG). We focus on components which were recently integrated and report about a systematic evaluation which demonstrated system capabilities and revealed valuable insights.
Knowledge is Never Enough: Towards Web Aided Deep Open World Recognition
Jun 04, 2019
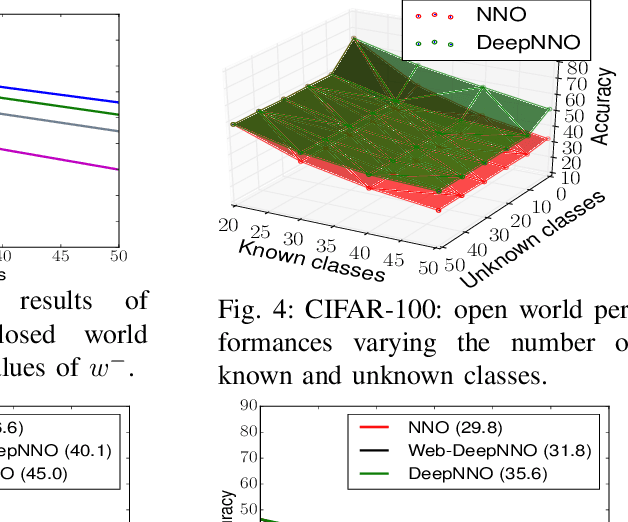
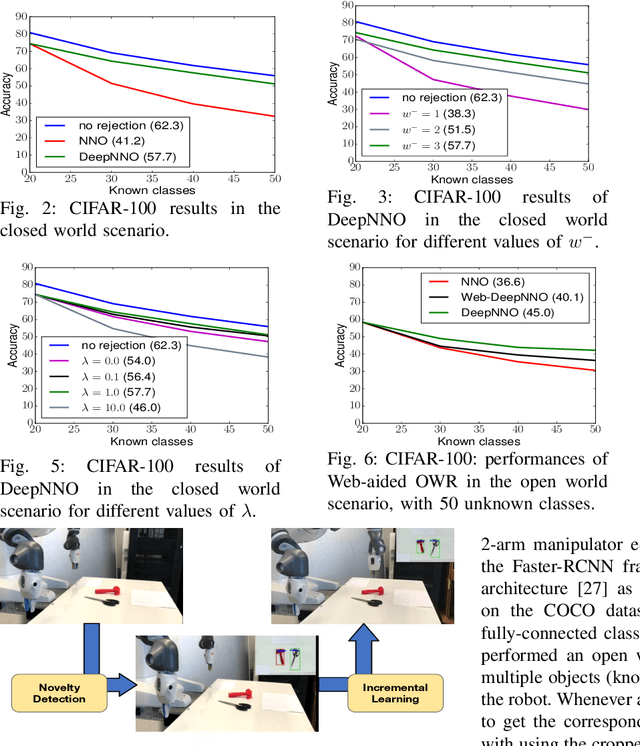
While today's robots are able to perform sophisticated tasks, they can only act on objects they have been trained to recognize. This is a severe limitation: any robot will inevitably see new objects in unconstrained settings, and thus will always have visual knowledge gaps. However, standard visual modules are usually built on a limited set of classes and are based on the strong prior that an object must belong to one of those classes. Identifying whether an instance does not belong to the set of known categories (i.e. open set recognition), only partially tackles this problem, as a truly autonomous agent should be able not only to detect what it does not know, but also to extend dynamically its knowledge about the world. We contribute to this challenge with a deep learning architecture that can dynamically update its known classes in an end-to-end fashion. The proposed deep network, based on a deep extension of a non-parametric model, detects whether a perceived object belongs to the set of categories known by the system and learns it without the need to retrain the whole system from scratch. Annotated images about the new category can be provided by an 'oracle' (i.e. human supervision), or by autonomous mining of the Web. Experiments on two different databases and on a robot platform demonstrate the promise of our approach.
Kitting in the Wild through Online Domain Adaptation
Jul 03, 2018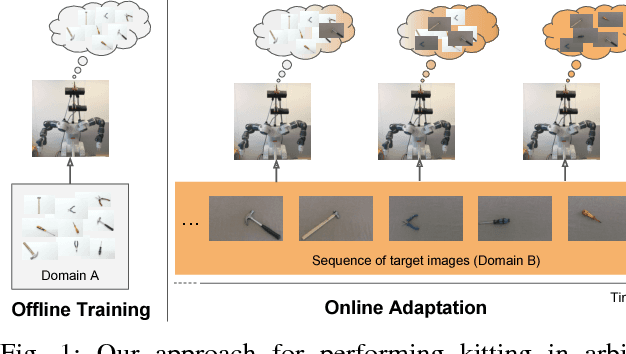


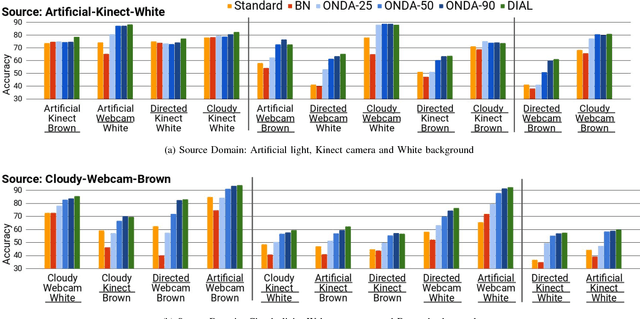
Technological developments call for increasing perception and action capabilities of robots. Among other skills, vision systems that can adapt to any possible change in the working conditions are needed. Since these conditions are unpredictable, we need benchmarks which allow to assess the generalization and robustness capabilities of our visual recognition algorithms. In this work we focus on robotic kitting in unconstrained scenarios. As a first contribution, we present a new visual dataset for the kitting task. Differently from standard object recognition datasets, we provide images of the same objects acquired under various conditions where camera, illumination and background are changed. This novel dataset allows for testing the robustness of robot visual recognition algorithms to a series of different domain shifts both in isolation and unified. Our second contribution is a novel online adaptation algorithm for deep models, based on batch-normalization layers, which allows to continuously adapt a model to the current working conditions. Differently from standard domain adaptation algorithms, it does not require any image from the target domain at training time. We benchmark the performance of the algorithm on the proposed dataset, showing its capability to fill the gap between the performances of a standard architecture and its counterpart adapted offline to the given target domain.
Fusing Saliency Maps with Region Proposals for Unsupervised Object Localization
Apr 11, 2018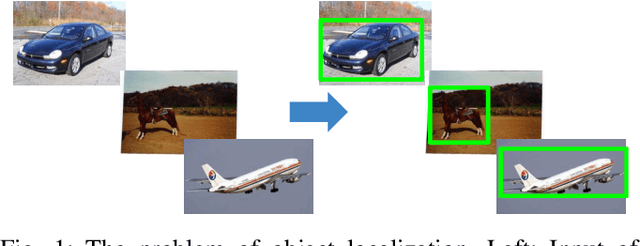
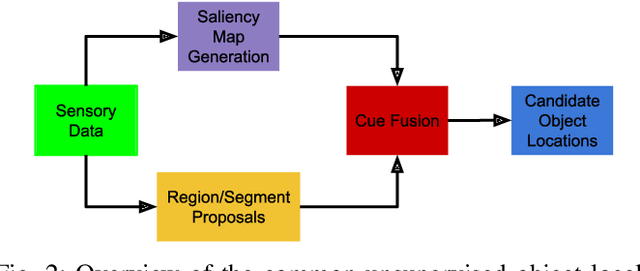
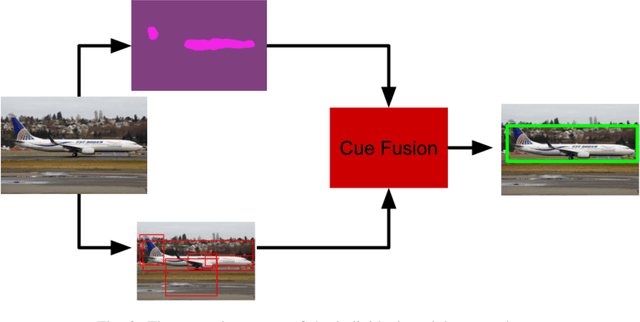

In this paper we address the problem of unsupervised localization of objects in single images. Compared to previous state-of-the-art method our method is fully unsupervised in the sense that there is no prior instance level or category level information about the image. Furthermore, we treat each image individually and do not rely on any neighboring image similarity. We employ deep-learning based generation of saliency maps and region proposals to tackle this problem. First salient regions in the image are determined using an encoder/decoder architecture. The resulting saliency map is matched with region proposals from a class agnostic region proposal network to roughly localize the candidate object regions. These regions are further refined based on the overlap and similarity ratios. Our experimental evaluations on a benchmark dataset show that the method gets close to current state-of-the-art methods in terms of localization accuracy even though these make use of multiple frames. Furthermore, we created a more challenging and realistic dataset with multiple object categories and varying viewpoint and illumination conditions for evaluating the method's performance in real world scenarios.
A Comparison of Visualisation Methods for Disambiguating Verbal Requests in Human-Robot Interaction
Jan 26, 2018

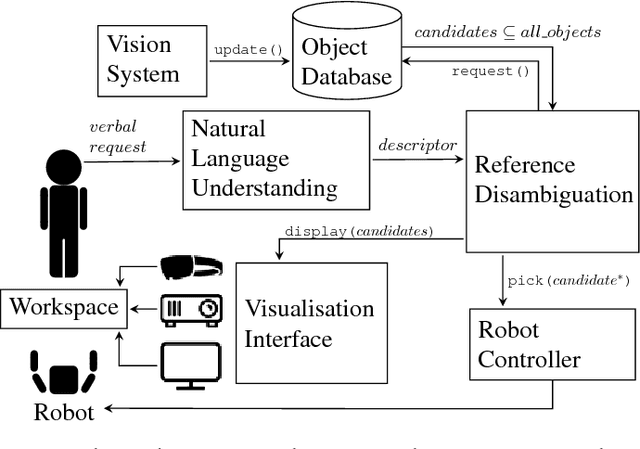

Picking up objects requested by a human user is a common task in human-robot interaction. When multiple objects match the user's verbal description, the robot needs to clarify which object the user is referring to before executing the action. Previous research has focused on perceiving user's multimodal behaviour to complement verbal commands or minimising the number of follow up questions to reduce task time. In this paper, we propose a system for reference disambiguation based on visualisation and compare three methods to disambiguate natural language instructions. In a controlled experiment with a YuMi robot, we investigated real-time augmentations of the workspace in three conditions -- mixed reality, augmented reality, and a monitor as the baseline -- using objective measures such as time and accuracy, and subjective measures like engagement, immersion, and display interference. Significant differences were found in accuracy and engagement between the conditions, but no differences were found in task time. Despite the higher error rates in the mixed reality condition, participants found that modality more engaging than the other two, but overall showed preference for the augmented reality condition over the monitor and mixed reality conditions.