 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidential Deep Learning for Class-Incremental Semantic Segmentation
Dec 06, 2022Class-Incremental Learning is a challenging problem in machine learning that aims to extend previously trained neural networks with new classes. This is especially useful if the system is able to classify new objects despite the original training data being unavailable. While the semantic segmentation problem has received less attention than classification, it poses distinct problems and challenges since previous and future target classes can be unlabeled in the images of a single increment. In this case, the background, past and future classes are correlated and there exist a background-shift. In this paper, we address the problem of how to model unlabeled classes while avoiding spurious feature clustering of future uncorrelated classes. We propose to use Evidential Deep Learning to model the evidence of the classes as a Dirichlet distribution. Our method factorizes the problem into a separate foreground class probability, calculated by the expected value of the Dirichlet distribution, and an unknown class (background) probability corresponding to the uncertainty of the estimate. In our novel formulation, the background probability is implicitly modeled, avoiding the feature space clustering that comes from forcing the model to output a high background score for pixels that are not labeled as objects. Experiments on the incremental Pascal VOC, and ADE20k benchmarks show that our method is superior to state-of-the-art, especially when repeatedly learning new classes with increasing number of increments.
DiffPose: Multi-hypothesis Human Pose Estimation using Diffusion models
Nov 29, 2022



Traditionally, monocular 3D human pose estimation employs a machine learning model to predict the most likely 3D pose for a given input image. However, a single image can be highly ambiguous and induces multiple plausible solutions for the 2D-3D lifting step which results in overly confident 3D pose predictors. To this end, we propose \emph{DiffPose}, a conditional diffusion model, that predicts multiple hypotheses for a given input image. In comparison to similar approaches, our diffusion model is straightforward and avoids intensive hyperparameter tuning, complex network structures, mode collapse, and unstable training. Moreover, we tackle a problem of the common two-step approach that first estimates a distribution of 2D joint locations via joint-wise heatmaps and consecutively approximates them based on first- or second-moment statistics. Since such a simplification of the heatmaps removes valid information about possibly correct, though labeled unlikely, joint locations, we propose to represent the heatmaps as a set of 2D joint candidate samples. To extract information about the original distribution from these samples we introduce our \emph{embedding transformer} that conditions the diffusion model. Experimentally, we show that DiffPose slightly improves upon the state of the art for multi-hypothesis pose estimation for simple poses and outperforms it by a large margin for highly ambiguous poses.
A Bayesian Approach to Reinforcement Learning of Vision-Based Vehicular Control
Apr 08, 2021
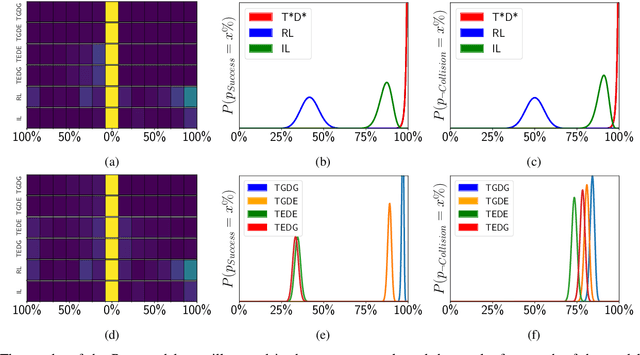
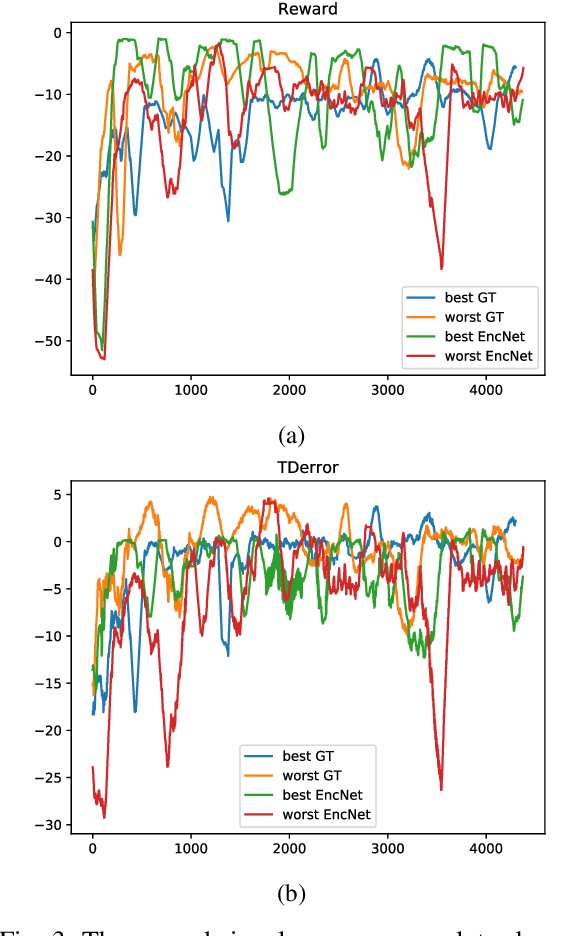

In this paper, we present a state-of-the-art reinforcement learning method for autonomous driving. Our approach employs temporal difference learning in a Bayesian framework to learn vehicle control signals from sensor data. The agent has access to images from a forward facing camera, which are preprocessed to generate semantic segmentation maps. We trained our system using both ground truth and estimated semantic segmentation input. Based on our observations from a large set of experiments, we conclude that training the system on ground truth input data leads to better performance than training the system on estimated input even if estimated input is used for evaluation. The system is trained and evaluated in a realistic simulated urban environment using the CARLA simulator. The simulator also contains a benchmark that allows for comparing to other systems and methods. The required training time of the system is shown to be lower and the performance on the benchmark superior to competing approaches.
Uncertainty-Aware CNNs for Depth Completion: Uncertainty from Beginning to End
Jun 05, 2020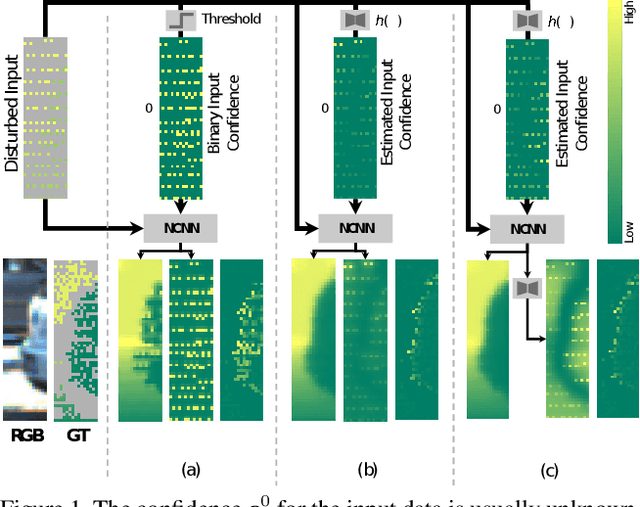
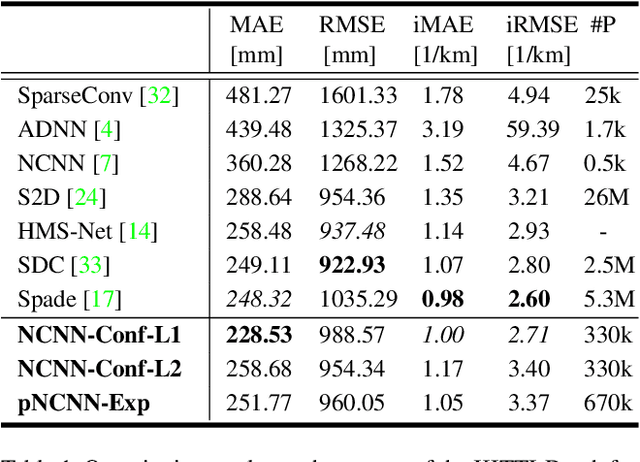
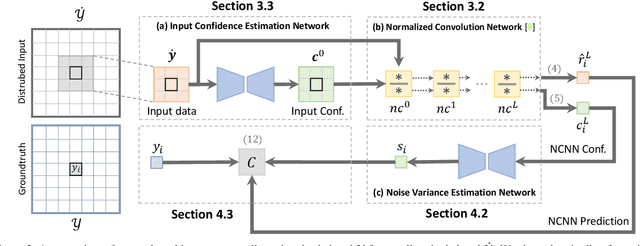
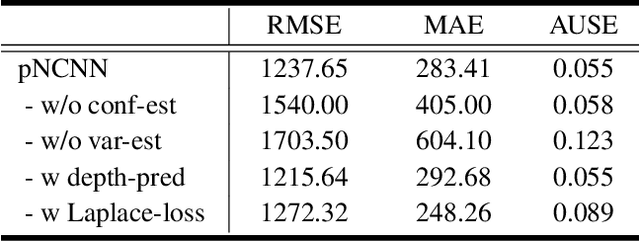
The focus in deep learning research has been mostly to push the limits of prediction accuracy. However, this was often achieved at the cost of increased complexity, raising concerns about the interpretability and the reliability of deep networks. Recently, an increasing attention has been given to untangling the complexity of deep networks and quantifying their uncertainty for different computer vision tasks. Differently, the task of depth completion has not received enough attention despite the inherent noisy nature of depth sensors. In this work, we thus focus on modeling the uncertainty of depth data in depth completion starting from the sparse noisy input all the way to the final prediction. We propose a novel approach to identify disturbed measurements in the input by learning an input confidence estimator in a self-supervised manner based on the normalized convolutional neural networks (NCNNs). Further, we propose a probabilistic version of NCNNs that produces a statistically meaningful uncertainty measure for the final prediction. When we evaluate our approach on the KITTI dataset for depth completion, we outperform all the existing Bayesian Deep Learning approaches in terms of prediction accuracy, quality of the uncertainty measure, and the computational efficiency. Moreover, our small network with 670k parameters performs on-par with conventional approaches with millions of parameters. These results give strong evidence that separating the network into parallel uncertainty and prediction streams leads to state-of-the-art performance with accurate uncertainty estimates.
Flexible Disaster Response of Tomorrow -- Final Presentation and Evaluation of the CENTAURO System
Sep 19, 2019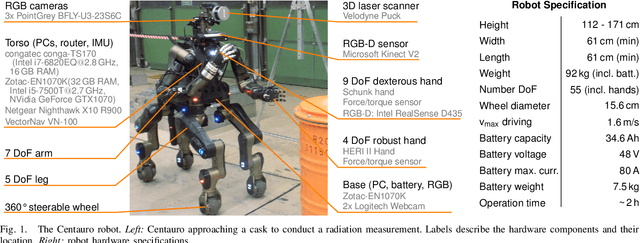

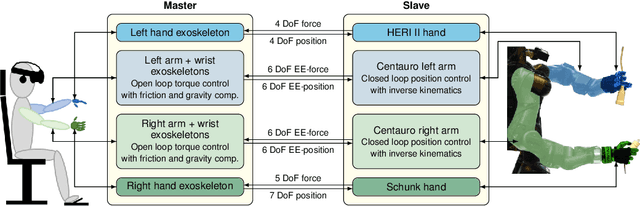
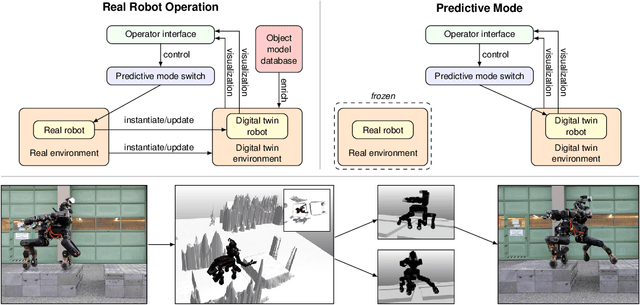
Mobile manipulation robots have high potential to support rescue forces in disaster-response missions. Despite the difficulties imposed by real-world scenarios, robots are promising to perform mission tasks from a safe distance. In the CENTAURO project, we developed a disaster-response system which consists of the highly flexible Centauro robot and suitable control interfaces including an immersive tele-presence suit and support-operator controls on different levels of autonomy. In this article, we give an overview of the final CENTAURO system. In particular, we explain several high-level design decisions and how those were derived from requirements and extensive experience of Kerntechnische Hilfsdienst GmbH, Karlsruhe, Germany (KHG). We focus on components which were recently integrated and report about a systematic evaluation which demonstrated system capabilities and revealed valuable insights.