 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Visual Reasoning for Socially-Aware Robots
Mar 04, 2026Robots operating in shared human environments must not only navigate, interact, and detect their surroundings, they must also interpret and respond to dynamic, and often unpredictable, human behaviours. Although recent advances have shown promise in enhancing robotic perception and instruction-following using Vision-Language Models (VLMs), they remain limited in addressing the complexities of multimodal human-robot interactions (HRI). Motivated by this challenge, we introduce a lightweight language-to-vision feedback module that closes the loop between an LLM and the vision encoder in VLMs. The module projects image-token hidden states through a gated Multi-Layer Perceptron (MLP) back into the encoder input, prompting a second pass that reinterprets the scene under text context. We evaluate this approach on three robotics-centred tasks: navigation in a simulated environment (Habitat), sequential scene description (Mementos-Robotics), and human-intention recognition (our HRI dataset). Results show that our method improves Qwen 2.5 (7B) by $3.3\%$ (less distance), $+0.057$ description score, and $+2.93\%$ accuracy, with less than $3\%$ extra parameters; Gemma 3 (4B) and LLaVA OV 1.5 (4B) show mixed navigation results but gains $+0.111,+0.055$ and $+10.81\%,+4.79\%$ on the latter two tasks. Code is available at https://github.com/alessioGalatolo/VLM-Reasoning-for-Robotics
"Who Should I Believe?": User Interpretation and Decision-Making When a Family Healthcare Robot Contradicts Human Memory
Jun 26, 2025Advancements in robotic capabilities for providing physical assistance, psychological support, and daily health management are making the deployment of intelligent healthcare robots in home environments increasingly feasible in the near future. However, challenges arise when the information provided by these robots contradicts users' memory, raising concerns about user trust and decision-making. This paper presents a study that examines how varying a robot's level of transparency and sociability influences user interpretation, decision-making and perceived trust when faced with conflicting information from a robot. In a 2 x 2 between-subjects online study, 176 participants watched videos of a Furhat robot acting as a family healthcare assistant and suggesting a fictional user to take medication at a different time from that remembered by the user. Results indicate that robot transparency influenced users' interpretation of information discrepancies: with a low transparency robot, the most frequent assumption was that the user had not correctly remembered the time, while with the high transparency robot, participants were more likely to attribute the discrepancy to external factors, such as a partner or another household member modifying the robot's information. Additionally, participants exhibited a tendency toward overtrust, often prioritizing the robot's recommendations over the user's memory, even when suspecting system malfunctions or third-party interference. These findings highlight the impact of transparency mechanisms in robotic systems, the complexity and importance associated with system access control for multi-user robots deployed in home environments, and the potential risks of users' over reliance on robots in sensitive domains such as healthcare.
Blending Participatory Design and Artificial Awareness for Trustworthy Autonomous Vehicles
Jun 09, 2025Current robotic agents, such as autonomous vehicles (AVs) and drones, need to deal with uncertain real-world environments with appropriate situational awareness (SA), risk awareness, coordination, and decision-making. The SymAware project strives to address this issue by designing an architecture for artificial awareness in multi-agent systems, enabling safe collaboration of autonomous vehicles and drones. However, these agents will also need to interact with human users (drivers, pedestrians, drone operators), which in turn requires an understanding of how to model the human in the interaction scenario, and how to foster trust and transparency between the agent and the human. In this work, we aim to create a data-driven model of a human driver to be integrated into our SA architecture, grounding our research in the principles of trustworthy human-agent interaction. To collect the data necessary for creating the model, we conducted a large-scale user-centered study on human-AV interaction, in which we investigate the interaction between the AV's transparency and the users' behavior. The contributions of this paper are twofold: First, we illustrate in detail our human-AV study and its findings, and second we present the resulting Markov chain models of the human driver computed from the study's data. Our results show that depending on the AV's transparency, the scenario's environment, and the users' demographics, we can obtain significant differences in the model's transitions.
UpStory: the Uppsala Storytelling dataset
Jul 05, 2024Friendship and rapport play an important role in the formation of constructive social interactions, and have been widely studied in educational settings due to their impact on student outcomes. Given the growing interest in automating the analysis of such phenomena through Machine Learning (ML), access to annotated interaction datasets is highly valuable. However, no dataset on dyadic child-child interactions explicitly capturing rapport currently exists. Moreover, despite advances in the automatic analysis of human behaviour, no previous work has addressed the prediction of rapport in child-child dyadic interactions in educational settings. We present UpStory -- the Uppsala Storytelling dataset: a novel dataset of naturalistic dyadic interactions between primary school aged children, with an experimental manipulation of rapport. Pairs of children aged 8-10 participate in a task-oriented activity: designing a story together, while being allowed free movement within the play area. We promote balanced collection of different levels of rapport by using a within-subjects design: self-reported friendships are used to pair each child twice, either minimizing or maximizing pair separation in the friendship network. The dataset contains data for 35 pairs, totalling 3h 40m of audio and video recordings. It includes two video sources covering the play area, as well as separate voice recordings for each child. An anonymized version of the dataset is made publicly available, containing per-frame head pose, body pose, and face features; as well as per-pair information, including the level of rapport. Finally, we provide ML baselines for the prediction of rapport.
Awareness in robotics: An early perspective from the viewpoint of the EIC Pathfinder Challenge "Awareness Inside''
Feb 14, 2024Consciousness has been historically a heavily debated topic in engineering, science, and philosophy. On the contrary, awareness had less success in raising the interest of scholars in the past. However, things are changing as more and more researchers are getting interested in answering questions concerning what awareness is and how it can be artificially generated. The landscape is rapidly evolving, with multiple voices and interpretations of the concept being conceived and techniques being developed. The goal of this paper is to summarize and discuss the ones among these voices connected with projects funded by the EIC Pathfinder Challenge called ``Awareness Inside'', a nonrecurring call for proposals within Horizon Europe designed specifically for fostering research on natural and synthetic awareness. In this perspective, we dedicate special attention to challenges and promises of applying synthetic awareness in robotics, as the development of mature techniques in this new field is expected to have a special impact on generating more capable and trustworthy embodied systems.
SLOT-V: Supervised Learning of Observer Models for Legible Robot Motion Planning in Manipulation
Oct 04, 2022

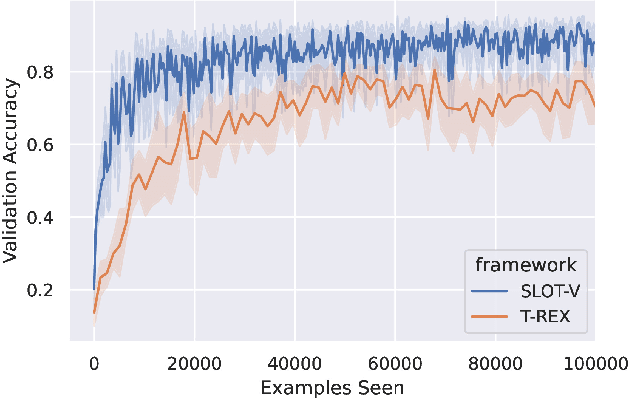
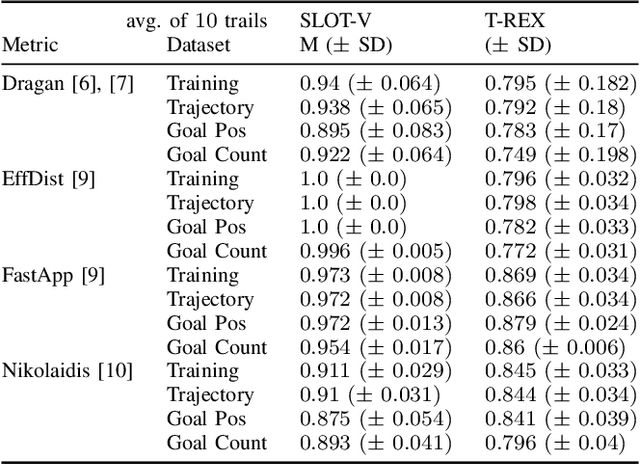
We present SLOT-V, a novel supervised learning framework that learns observer models (human preferences) from robot motion trajectories in a legibility context. Legibility measures how easily a (human) observer can infer the robot's goal from a robot motion trajectory. When generating such trajectories, existing planners often rely on an observer model that estimates the quality of trajectory candidates. These observer models are frequently hand-crafted or, occasionally, learned from demonstrations. Here, we propose to learn them in a supervised manner using the same data format that is frequently used during the evaluation of aforementioned approaches. We then demonstrate the generality of SLOT-V using a Franka Emika in a simulated manipulation environment. For this, we show that it can learn to closely predict various hand-crafted observer models, i.e., that SLOT-V's hypothesis space encompasses existing handcrafted models. Next, we showcase SLOT-V's ability to generalize by showing that a trained model continues to perform well in environments with unseen goal configurations and/or goal counts. Finally, we benchmark SLOT-V's sample efficiency (and performance) against an existing IRL approach and show that SLOT-V learns better observer models with less data. Combined, these results suggest that SLOT-V can learn viable observer models. Better observer models imply more legible trajectories, which may - in turn - lead to better and more transparent human-robot interaction.
A new approach to evaluating legibility: Comparing legibility frameworks using framework-independent robot motion trajectories
Jan 15, 2022
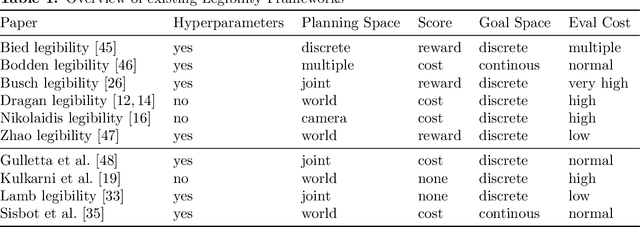


Robots that share an environment with humans may communicate their intent using a variety of different channels. Movement is one of these channels and, particularly in manipulation tasks, intent communication via movement is called legibility. It alters a robot's trajectory to make it intent expressive. Here we propose a novel evaluation method that improves the data efficiency of collected experimental data when benchmarking approaches generating such legible behavior. The primary novelty of the proposed method is that it uses trajectories that were generated independently of the framework being tested. This makes evaluation easier, enables N-way comparisons between approaches, and allows easier comparison across papers. We demonstrate the efficiency of the new evaluation method by comparing 10 legibility frameworks in 2 scenarios. The paper, thus, provides readers with (1) a novel approach to investigate and/or benchmark legibility, (2) an overview of existing frameworks, (3) an evaluation of 10 legibility frameworks (from 6 papers), and (4) evidence that viewing angle and trajectory progression matter when users evaluate the legibility of a motion.
Does the Goal Matter? Emotion Recognition Tasks Can Change the Social Value of Facial Mimicry towards Artificial Agents
May 05, 2021

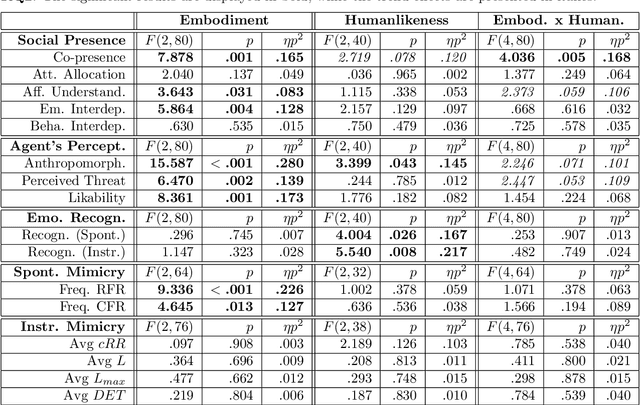

In this paper, we present a study aimed at understanding whether the embodiment and humanlikeness of an artificial agent can affect people's spontaneous and instructed mimicry of its facial expressions. The study followed a mixed experimental design and revolved around an emotion recognition task. Participants were randomly assigned to one level of humanlikeness (between-subject variable: humanlike, characterlike, or morph facial texture of the artificial agents) and observed the facial expressions displayed by a human (control) and three artificial agents differing in embodiment (within-subject variable: video-recorded robot, physical robot, and virtual agent). To study both spontaneous and instructed facial mimicry, we divided the experimental sessions into two phases. In the first phase, we asked participants to observe and recognize the emotions displayed by the agents. In the second phase, we asked them to look at the agents' facial expressions, replicate their dynamics as closely as possible, and then identify the observed emotions. In both cases, we assessed participants' facial expressions with an automated Action Unit (AU) intensity detector. Contrary to our hypotheses, our results disclose that the agent that was perceived as the least uncanny, and most anthropomorphic, likable, and co-present, was the one spontaneously mimicked the least. Moreover, they show that instructed facial mimicry negatively predicts spontaneous facial mimicry. Further exploratory analyses revealed that spontaneous facial mimicry appeared when participants were less certain of the emotion they recognized. Hence, we postulate that an emotion recognition goal can flip the social value of facial mimicry as it transforms a likable artificial agent into a distractor.
I Can See it in Your Eyes: Gaze towards a Robot as an Implicit Cue of Uncanniness and Task Performance in Long-term Interactions
Jan 13, 2021
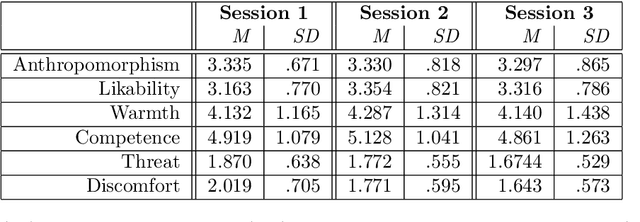
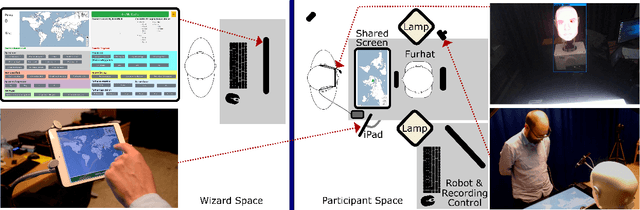
Over the past years, extensive research has been dedicated to developing robust platforms and data-driven dialogue models to support long-term human-robot interactions. However, little is known about how people's perception of robots and engagement with them develop over time and how these can be accurately assessed through implicit and continuous measurement techniques. In this paper, we investigate this by involving participants in three interaction sessions with multiple days of zero exposure in between. Each session consists of a joint task with a robot as well as two short social chats with it before and after the task. We measure participants' gaze patterns with a wearable eye-tracker and gauge their perception of the robot and engagement with it and the joint task using questionnaires. Results disclose that aversion of gaze in a social chat is an indicator of a robot's uncanniness and that the more people gaze at the robot in a joint task, the worse they perform. In contrast with most HRI literature, our results show that gaze towards an object of shared attention, rather than gaze towards a robotic partner, is the most meaningful predictor of engagement in a joint task. Furthermore, the analyses of long-term gaze patterns disclose that people's mutual gaze in a social chat develops congruently with their perceptions of the robot over time. These are key findings for the HRI community as they entail that gaze behavior can be used as an implicit measure of people's perception of robots in a social chat and of their engagement and task performance in a joint task.
A Robot by Any Other Frame: Framing and Behaviour Influence Mind Perception in Virtual but not Real-World Environments
Apr 16, 2020


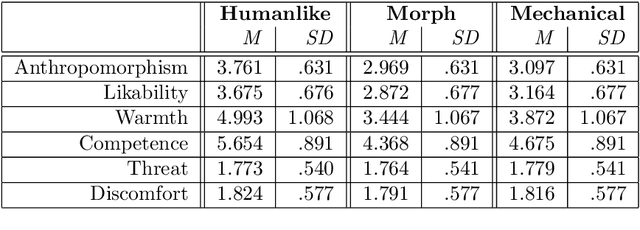
Mind perception in robots has been an understudied construct in human-robot interaction (HRI) compared to similar concepts such as anthropomorphism and the intentional stance. In a series of three experiments, we identify two factors that could potentially influence mind perception and moral concern in robots: how the robot is introduced (framing), and how the robot acts (social behaviour). In the first two online experiments, we show that both framing and behaviour independently influence participants' mind perception. However, when we combined both variables in the following real-world experiment, these effects failed to replicate. We hence identify a third factor post-hoc: the online versus real-world nature of the interactions. After analysing potential confounds, we tentatively suggest that mind perception is harder to influence in real-world experiments, as manipulations are harder to isolate compared to virtual experiments, which only provide a slice of the interaction.