 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Team Modeling through Tempo-Relational Representation Learning
Jul 17, 2025Team modeling remains a fundamental challenge at the intersection of Artificial Intelligence and the Social Sciences. Social Science research emphasizes the need to jointly model dynamics and relations, while practical applications demand unified models capable of inferring multiple team constructs simultaneously, providing interpretable insights and actionable recommendations to enhance team performance. However, existing works do not meet these practical demands. To bridge this gap, we present TRENN, a novel tempo-relational architecture that integrates: (i) an automatic temporal graph extractor, (ii) a tempo-relational encoder, (iii) a decoder for team construct prediction, and (iv) two complementary explainability modules. TRENN jointly captures relational and temporal team dynamics, providing a solid foundation for MT-TRENN, which extends TReNN by replacing the decoder with a multi-task head, enabling the model to learn shared Social Embeddings and simultaneously predict multiple team constructs, including Emergent Leadership, Leadership Style, and Teamwork components. Experimental results demonstrate that our approach significantly outperforms approaches that rely exclusively on temporal or relational information. Additionally, experimental evaluation has shown that the explainability modules integrated in MT-TRENN yield interpretable insights and actionable suggestions to support team improvement. These capabilities make our approach particularly well-suited for Human-Centered AI applications, such as intelligent decision-support systems in high-stakes collaborative environments.
UpStory: the Uppsala Storytelling dataset
Jul 05, 2024Friendship and rapport play an important role in the formation of constructive social interactions, and have been widely studied in educational settings due to their impact on student outcomes. Given the growing interest in automating the analysis of such phenomena through Machine Learning (ML), access to annotated interaction datasets is highly valuable. However, no dataset on dyadic child-child interactions explicitly capturing rapport currently exists. Moreover, despite advances in the automatic analysis of human behaviour, no previous work has addressed the prediction of rapport in child-child dyadic interactions in educational settings. We present UpStory -- the Uppsala Storytelling dataset: a novel dataset of naturalistic dyadic interactions between primary school aged children, with an experimental manipulation of rapport. Pairs of children aged 8-10 participate in a task-oriented activity: designing a story together, while being allowed free movement within the play area. We promote balanced collection of different levels of rapport by using a within-subjects design: self-reported friendships are used to pair each child twice, either minimizing or maximizing pair separation in the friendship network. The dataset contains data for 35 pairs, totalling 3h 40m of audio and video recordings. It includes two video sources covering the play area, as well as separate voice recordings for each child. An anonymized version of the dataset is made publicly available, containing per-frame head pose, body pose, and face features; as well as per-pair information, including the level of rapport. Finally, we provide ML baselines for the prediction of rapport.
Beam Search with Bidirectional Strategies for Neural Response Generation
Oct 07, 2021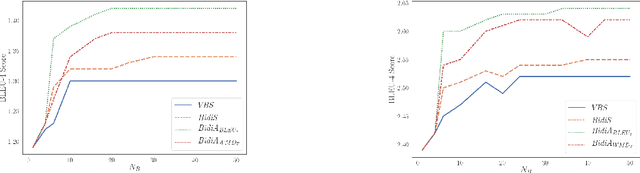
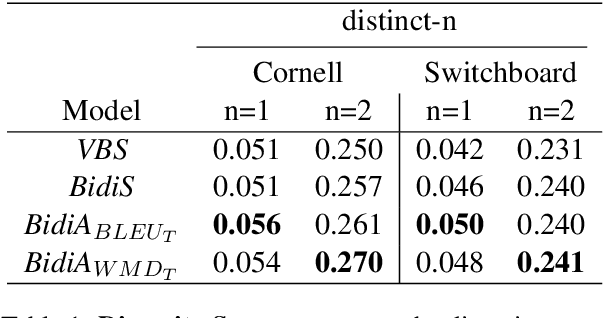
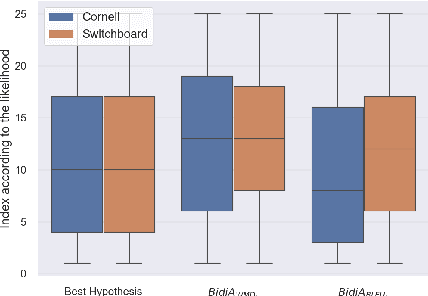

Sequence-to-sequence neural networks have been widely used in language-based applications as they have flexible capabilities to learn various language models. However, when seeking for the optimal language response through trained neural networks, current existing approaches such as beam-search decoder strategies are still not able reaching to promising performances. Instead of developing various decoder strategies based on a "regular sentence order" neural network (a trained model by outputting sentences from left-to-right order), we leveraged "reverse" order as additional language model (a trained model by outputting sentences from right-to-left order) which can provide different perspectives for the path finding problems. In this paper, we propose bidirectional strategies in searching paths by combining two networks (left-to-right and right-to-left language models) making a bidirectional beam search possible. Besides, our solution allows us using any similarity measure in our sentence selection criterion. Our approaches demonstrate better performance compared to the unidirectional beam search strategy.
Does the Goal Matter? Emotion Recognition Tasks Can Change the Social Value of Facial Mimicry towards Artificial Agents
May 05, 2021

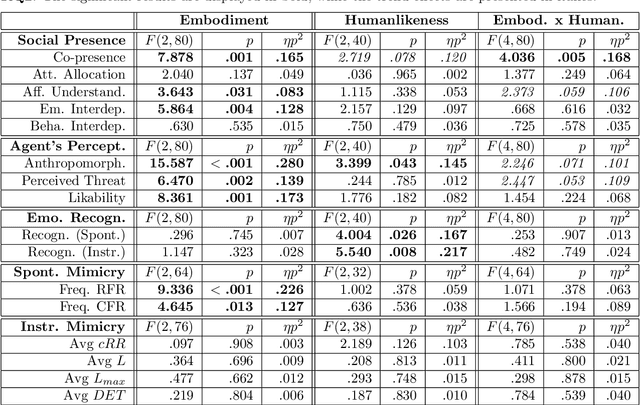

In this paper, we present a study aimed at understanding whether the embodiment and humanlikeness of an artificial agent can affect people's spontaneous and instructed mimicry of its facial expressions. The study followed a mixed experimental design and revolved around an emotion recognition task. Participants were randomly assigned to one level of humanlikeness (between-subject variable: humanlike, characterlike, or morph facial texture of the artificial agents) and observed the facial expressions displayed by a human (control) and three artificial agents differing in embodiment (within-subject variable: video-recorded robot, physical robot, and virtual agent). To study both spontaneous and instructed facial mimicry, we divided the experimental sessions into two phases. In the first phase, we asked participants to observe and recognize the emotions displayed by the agents. In the second phase, we asked them to look at the agents' facial expressions, replicate their dynamics as closely as possible, and then identify the observed emotions. In both cases, we assessed participants' facial expressions with an automated Action Unit (AU) intensity detector. Contrary to our hypotheses, our results disclose that the agent that was perceived as the least uncanny, and most anthropomorphic, likable, and co-present, was the one spontaneously mimicked the least. Moreover, they show that instructed facial mimicry negatively predicts spontaneous facial mimicry. Further exploratory analyses revealed that spontaneous facial mimicry appeared when participants were less certain of the emotion they recognized. Hence, we postulate that an emotion recognition goal can flip the social value of facial mimicry as it transforms a likable artificial agent into a distractor.
On-the-fly Detection of User Engagement Decrease in Spontaneous Human-Robot Interaction, International Journal of Social Robotics, 2019
Apr 20, 2020



In this paper, we consider the detection of a decrease of engagement by users spontaneously interacting with a socially assistive robot in a public space. We first describe the UE-HRI dataset that collects spontaneous Human-Robot Interactions following the guidelines provided by the Affective Computing research community to collect data "in-the-wild". We then analyze the users' behaviors, focusing on proxemics, gaze, head motion, facial expressions and speech during interactions with the robot. Finally, we investigate the use of deep learning techniques (Recurrent and Deep Neural Networks) to detect user engagement decrease in realtime. The results of this work highlight, in particular, the relevance of taking into account the temporal dynamics of a user's behavior. Allowing 1 to 2 seconds as buffer delay improves the performance of taking a decision on user engagement.
Heavy-tailed Representations, Text Polarity Classification & Data Augmentation
Mar 25, 2020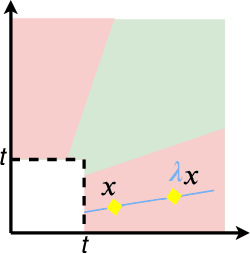
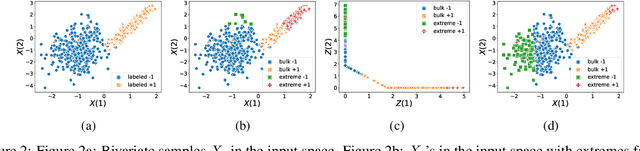
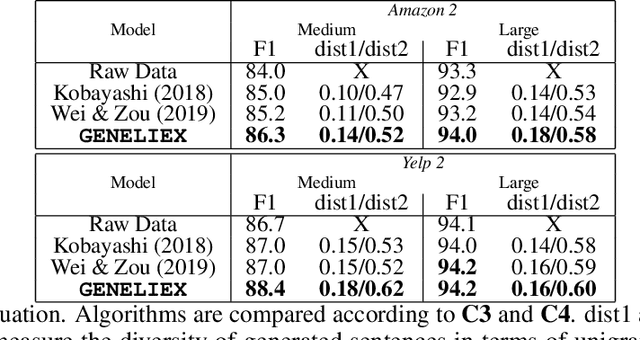
The dominant approaches to text representation in natural language rely on learning embeddings on massive corpora which have convenient properties such as compositionality and distance preservation. In this paper, we develop a novel method to learn a heavy-tailed embedding with desirable regularity properties regarding the distributional tails, which allows to analyze the points far away from the distribution bulk using the framework of multivariate extreme value theory. In particular, a classifier dedicated to the tails of the proposed embedding is obtained which performance outperforms the baseline. This classifier exhibits a scale invariance property which we leverage by introducing a novel text generation method for label preserving dataset augmentation. Numerical experiments on synthetic and real text data demonstrate the relevance of the proposed framework and confirm that this method generates meaningful sentences with controllable attribute, e.g. positive or negative sentiment.
Guider l'attention dans les modeles de sequence a sequence pour la prediction des actes de dialogue
Feb 26, 2020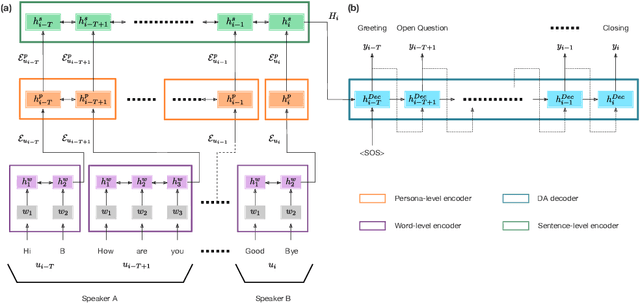
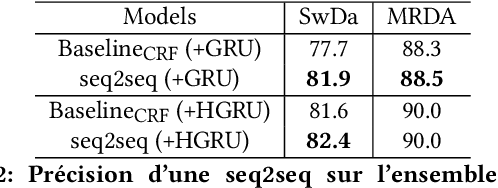
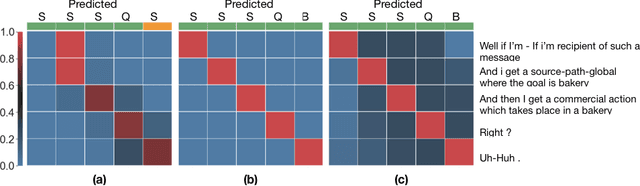

The task of predicting dialog acts (DA) based on conversational dialog is a key component in the development of conversational agents. Accurately predicting DAs requires a precise modeling of both the conversation and the global tag dependencies. We leverage seq2seq approaches widely adopted in Neural Machine Translation (NMT) to improve the modelling of tag sequentiality. Seq2seq models are known to learn complex global dependencies while currently proposed approaches using linear conditional random fields (CRF) only model local tag dependencies. In this work, we introduce a seq2seq model tailored for DA classification using: a hierarchical encoder, a novel guided attention mechanism and beam search applied to both training and inference. Compared to the state of the art our model does not require handcrafted features and is trained end-to-end. Furthermore, the proposed approach achieves an unmatched accuracy score of 85% on SwDA, and state-of-the-art accuracy score of 91.6% on MRDA.
* in French
Guiding attention in Sequence-to-sequence models for Dialogue Act prediction
Feb 26, 2020
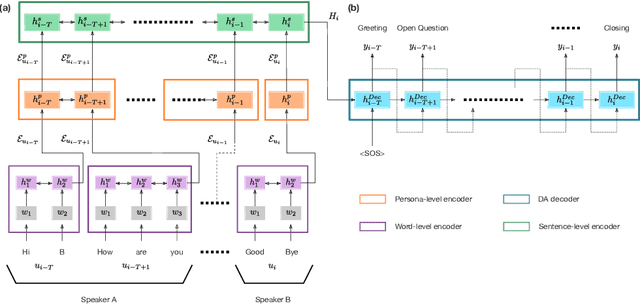
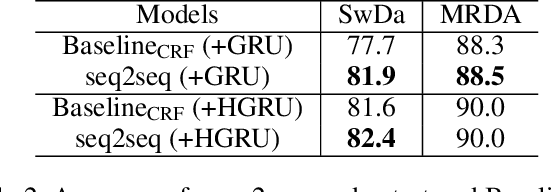

The task of predicting dialog acts (DA) based on conversational dialog is a key component in the development of conversational agents. Accurately predicting DAs requires a precise modeling of both the conversation and the global tag dependencies. We leverage seq2seq approaches widely adopted in Neural Machine Translation (NMT) to improve the modelling of tag sequentiality. Seq2seq models are known to learn complex global dependencies while currently proposed approaches using linear conditional random fields (CRF) only model local tag dependencies. In this work, we introduce a seq2seq model tailored for DA classification using: a hierarchical encoder, a novel guided attention mechanism and beam search applied to both training and inference. Compared to the state of the art our model does not require handcrafted features and is trained end-to-end. Furthermore, the proposed approach achieves an unmatched accuracy score of 85% on SwDA, and state-of-the-art accuracy score of 91.6% on MRDA.